Python爬虫:
python中selenium操作下拉滚动条方法汇总
UI自动化中经常会遇到元素识别不到,找不到的问题,原因有很多,比如不在iframe里,xpath或id写错了等等;但有一种是在当前显示的页面元素不可见,拖动下拉条后元素就出来了。
比如下面这样一个网页,需要进行拖动下拉条后才能通过selenium找到密码输入框的元素,
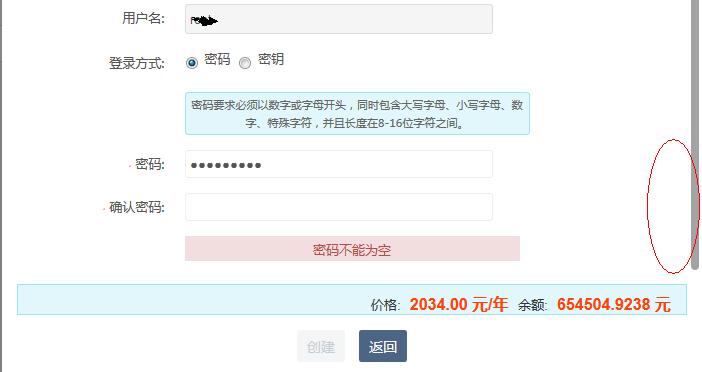
在python中有几种方法解决这种问题,简单介绍下,给需要的人:
方法一)使用js脚本直接操作,方法如下:
js="var q=document.getElementById('id').scrollTop=10000"
driver.execute_script(js)
或:
js="var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
这里的id为滚动条的id,但js中没有xpath的方法,所以滚动条没有id的网页此方法不适用
方法二)使用js脚本拖动到提定地方
target = driver.find_element_by_id("id_keypair")
driver.execute_script("arguments[0].scrollIntoView();", target) #拖动到可见的元素去
这个方法可以将滚动条拖动到需要显示的元素位置,此方法用途比较广,可以使用
方法三)根据页面显示进行变通,发送tab键
在本例中的页面中,密码是输入框,正常手工操作时,可以通过tab键会切换到密码框中,所以根据此思路,在python中也可以发送tab键来切换,使元素显示
from selenium.webdriver.common.keys import Keys
driver.find_element_by_id("id_login_method_0").send_keys(Keys.TAB)
update
前段时间使用robotframe work框架时,selenium2library里面有一个非常好用的功能Focus,会自动定位到元素,研读一下源码:
def focus(self, locator):
"""Sets focus to element identified by `locator`."""
element = self._element_find(locator, True, True)
self._current_browser().execute_script("arguments[0].focus();", element)
从源码中我们可以看到,此方法与我们在python自己写的方法二)一致,工具给我们做了封装。
Python爬虫:的更多相关文章
- 爬虫前篇 /https协议原理剖析
爬虫前篇 /https协议原理剖析 目录 爬虫前篇 /https协议原理剖析 1. http协议是不安全的 2. 使用对称秘钥进行数据加密 3. 动态对称秘钥和非对称秘钥 4. CA证书的应用 5. ...
- Python网络爬虫http和https协议
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- Python爬虫-02:HTTPS请求与响应,以及抓包工具Fiddler的使用
目录 1. HTTP和HTTPS 1.1. HTTP的请求和响应流程:打开一个网页的过程 1.2. URL 2. 客户端HTTP请求 3. Fiddler抓包工具的使用 3.1. 工作原理 3.2. ...
- java爬虫爬取https协议的网站时,SSL报错, java.lang.IllegalArgumentException TSLv1.2 报错
目前在广州一家小公司实习,这里的学习环境还是挺好的,今天公司从业十几年的大佬让我检查一下几年前的爬虫程序是否还能使用…… 我从myeclipse上check out了大佬的程序,放到workspace ...
- Python爬虫帮你打包下载所有抖音好听的背景音乐,还不快收藏一起听歌【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- python爬虫相关
一.Python re模块的基本用法: https://blog.csdn.net/chenmozhe22/article/details/80601971 二.爬取网页图片 https://www. ...
- 02.Python网络爬虫第二弹《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- Python网络爬虫第二弹《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
- python网络爬虫《http和https协议》
一.HTTP协议 1.官方概念: HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文 ...
随机推荐
- Eclipse优化之设置不自动弹出控制台和Server
有时候Eclipse启动,控制台console不会自动跳出来,需要手工点击该选项卡才行, 按下面的设置,可以让它自动跳出来(或不跳出来): windows -> preferences ...
- nui-app 笔记
https://uniapp.dcloud.io
- CSharpGL(54)用基于图像的光照(IBL)来计算PBR的Specular部分
CSharpGL(54)用基于图像的光照(IBL)来计算PBR的Specular部分 接下来本系列将通过翻译(https://learnopengl.com)这个网站上关于PBR的内容来学习PBR(P ...
- python做中学(七)ord() 函数
描述 ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII ...
- js移动端自适应动态设置html的fontsize
JS设计移动端页面时会遇到自适应问题,大多数都知道用rem来设置页面的比例大小,下面就来说几种常见的html中的fontsize设置方法: 1.使用flexible.js插件库. 淘宝就是利用这个来 ...
- vue 开发常见问题解决大全
vue添加favicon.ico,包含开发环境和生产环境显示. 1.把图标放在下项目的根目录.. 2.修改build文件夹下面的webpack.dev.conf.js(开发环境) 和webpack.p ...
- c++11 C++14 C++17
Since C++11, WG21, the ISO designation for the C++ standard, try to shipped the standard every 3 ye ...
- GO与PHP的AES交互,key长度问题
今天在使用go与php的AES加解密交互中,一直有个问题那就是在go中加密后,在php端始终都是无法解密,经过排查最后发现是加密key长度引起的问题, 这里简单记录下. go的AES使用的是第三方的库 ...
- linux安装IB驱动方法
一.准备 1.Linux操作系统7.6(根据实际情况变更,此处用redhat7.6系统举例) 2.驱动:MLNX_OFED_LINUX-4.6-1.0.1.1-rhel7.6-x86_64.tgz(根 ...
- JavaScript 数学
JavaScript Math 数学 神奇的圆周率 Math.PI ; // 返回 3.1415926535-- Math 数学方法 Math.round() Math.round(X):返回 X 的 ...