Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?
前言
在 《从0到1学习Flink》—— Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇文章更详细的介绍下,并写一个 demo 出来让大家理解。
Flink Kafka source
准备工作
我们先来看下 Flink 从 Kafka topic 中获取数据的 demo,首先你需要安装好了 FLink 和 Kafka 。
运行启动 Flink、Zookepeer、Kafka,
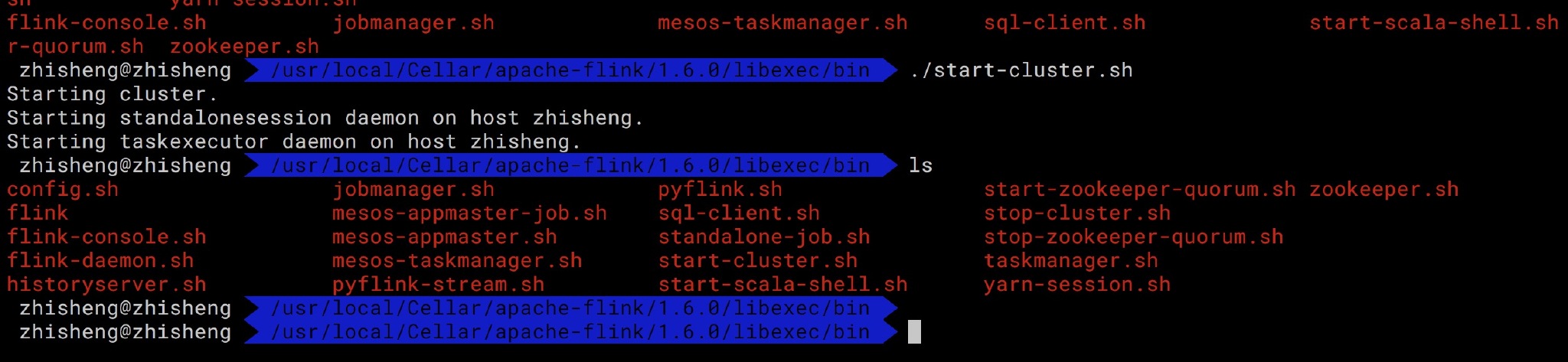

好了,都启动了!
maven 依赖
<!--flink java-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--日志-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<!--flink kafka connector-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--alibaba fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
测试发送数据到 kafka topic
实体类,Metric.java
package com.zhisheng.flink.model;
import java.util.Map;
/**
* Desc:
* weixi: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class Metric {
public String name;
public long timestamp;
public Map<String, Object> fields;
public Map<String, String> tags;
public Metric() {
}
public Metric(String name, long timestamp, Map<String, Object> fields, Map<String, String> tags) {
this.name = name;
this.timestamp = timestamp;
this.fields = fields;
this.tags = tags;
}
@Override
public String toString() {
return "Metric{" +
"name='" + name + '\'' +
", timestamp='" + timestamp + '\'' +
", fields=" + fields +
", tags=" + tags +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public long getTimestamp() {
return timestamp;
}
public void setTimestamp(long timestamp) {
this.timestamp = timestamp;
}
public Map<String, Object> getFields() {
return fields;
}
public void setFields(Map<String, Object> fields) {
this.fields = fields;
}
public Map<String, String> getTags() {
return tags;
}
public void setTags(Map<String, String> tags) {
this.tags = tags;
}
}
往 kafka 中写数据工具类:KafkaUtils.java
import com.alibaba.fastjson.JSON;
import com.zhisheng.flink.model.Metric;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
/**
* 往kafka中写数据
* 可以使用这个main函数进行测试一下
* weixin: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class KafkaUtils {
public static final String broker_list = "localhost:9092";
public static final String topic = "metric"; // kafka topic,Flink 程序中需要和这个统一
public static void writeToKafka() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", broker_list);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //key 序列化
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //value 序列化
KafkaProducer producer = new KafkaProducer<String, String>(props);
Metric metric = new Metric();
metric.setTimestamp(System.currentTimeMillis());
metric.setName("mem");
Map<String, String> tags = new HashMap<>();
Map<String, Object> fields = new HashMap<>();
tags.put("cluster", "zhisheng");
tags.put("host_ip", "101.147.022.106");
fields.put("used_percent", 90d);
fields.put("max", 27244873d);
fields.put("used", 17244873d);
fields.put("init", 27244873d);
metric.setTags(tags);
metric.setFields(fields);
ProducerRecord record = new ProducerRecord<String, String>(topic, null, null, JSON.toJSONString(metric));
producer.send(record);
System.out.println("发送数据: " + JSON.toJSONString(metric));
producer.flush();
}
public static void main(String[] args) throws InterruptedException {
while (true) {
Thread.sleep(300);
writeToKafka();
}
}
}
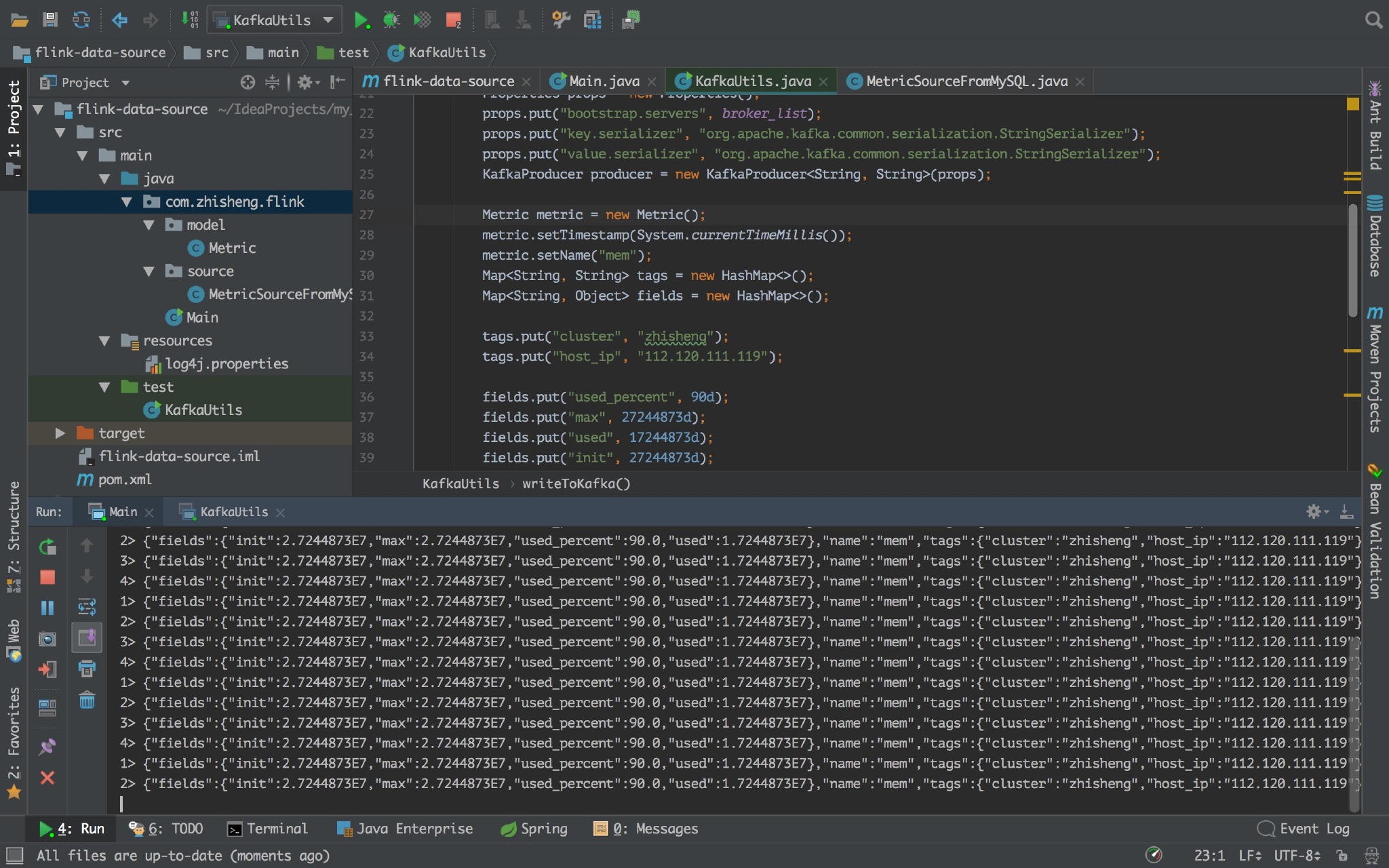
运行:

如果出现如上图标记的,即代表能够不断的往 kafka 发送数据的。
Flink 程序
Main.java
package com.zhisheng.flink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import java.util.Properties;
/**
* Desc:
* weixi: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class Main {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //key 反序列化
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest"); //value 反序列化
DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer011<>(
"metric", //kafka topic
new SimpleStringSchema(), // String 序列化
props)).setParallelism(1);
dataStreamSource.print(); //把从 kafka 读取到的数据打印在控制台
env.execute("Flink add data source");
}
}
运行起来:
看到没程序,Flink 程序控制台能够源源不断的打印数据呢。
自定义 Source
上面就是 Flink 自带的 Kafka source,那么接下来就模仿着写一个从 MySQL 中读取数据的 Source。
首先 pom.xml 中添加 MySQL 依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.34</version>
</dependency>
数据库建表如下:
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(25) COLLATE utf8_bin DEFAULT NULL,
`password` varchar(25) COLLATE utf8_bin DEFAULT NULL,
`age` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
插入数据:
INSERT INTO `student` VALUES ('1', 'zhisheng01', '123456', '18'), ('2', 'zhisheng02', '123', '17'), ('3', 'zhisheng03', '1234', '18'), ('4', 'zhisheng04', '12345', '16');
COMMIT;
新建实体类:Student.java
package com.zhisheng.flink.model;
/**
* Desc:
* weixi: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class Student {
public int id;
public String name;
public String password;
public int age;
public Student() {
}
public Student(int id, String name, String password, int age) {
this.id = id;
this.name = name;
this.password = password;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
新建 Source 类 SourceFromMySQL.java,该类继承 RichSourceFunction ,实现里面的 open、close、run、cancel 方法:
package com.zhisheng.flink.source;
import com.zhisheng.flink.model.Student;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* Desc:
* weixi: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class SourceFromMySQL extends RichSourceFunction<Student> {
PreparedStatement ps;
private Connection connection;
/**
* open() 方法中建立连接,这样不用每次 invoke 的时候都要建立连接和释放连接。
*
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
connection = getConnection();
String sql = "select * from Student;";
ps = this.connection.prepareStatement(sql);
}
/**
* 程序执行完毕就可以进行,关闭连接和释放资源的动作了
*
* @throws Exception
*/
@Override
public void close() throws Exception {
super.close();
if (connection != null) { //关闭连接和释放资源
connection.close();
}
if (ps != null) {
ps.close();
}
}
/**
* DataStream 调用一次 run() 方法用来获取数据
*
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<Student> ctx) throws Exception {
ResultSet resultSet = ps.executeQuery();
while (resultSet.next()) {
Student student = new Student(
resultSet.getInt("id"),
resultSet.getString("name").trim(),
resultSet.getString("password").trim(),
resultSet.getInt("age"));
ctx.collect(student);
}
}
@Override
public void cancel() {
}
private static Connection getConnection() {
Connection con = null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "root123456");
} catch (Exception e) {
System.out.println("-----------mysql get connection has exception , msg = "+ e.getMessage());
}
return con;
}
}
Flink 程序:
package com.zhisheng.flink;
import com.zhisheng.flink.source.SourceFromMySQL;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Desc:
* weixi: zhisheng_tian
* blog: http://www.54tianzhisheng.cn/
*/
public class Main2 {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new SourceFromMySQL()).print();
env.execute("Flink add data sourc");
}
}
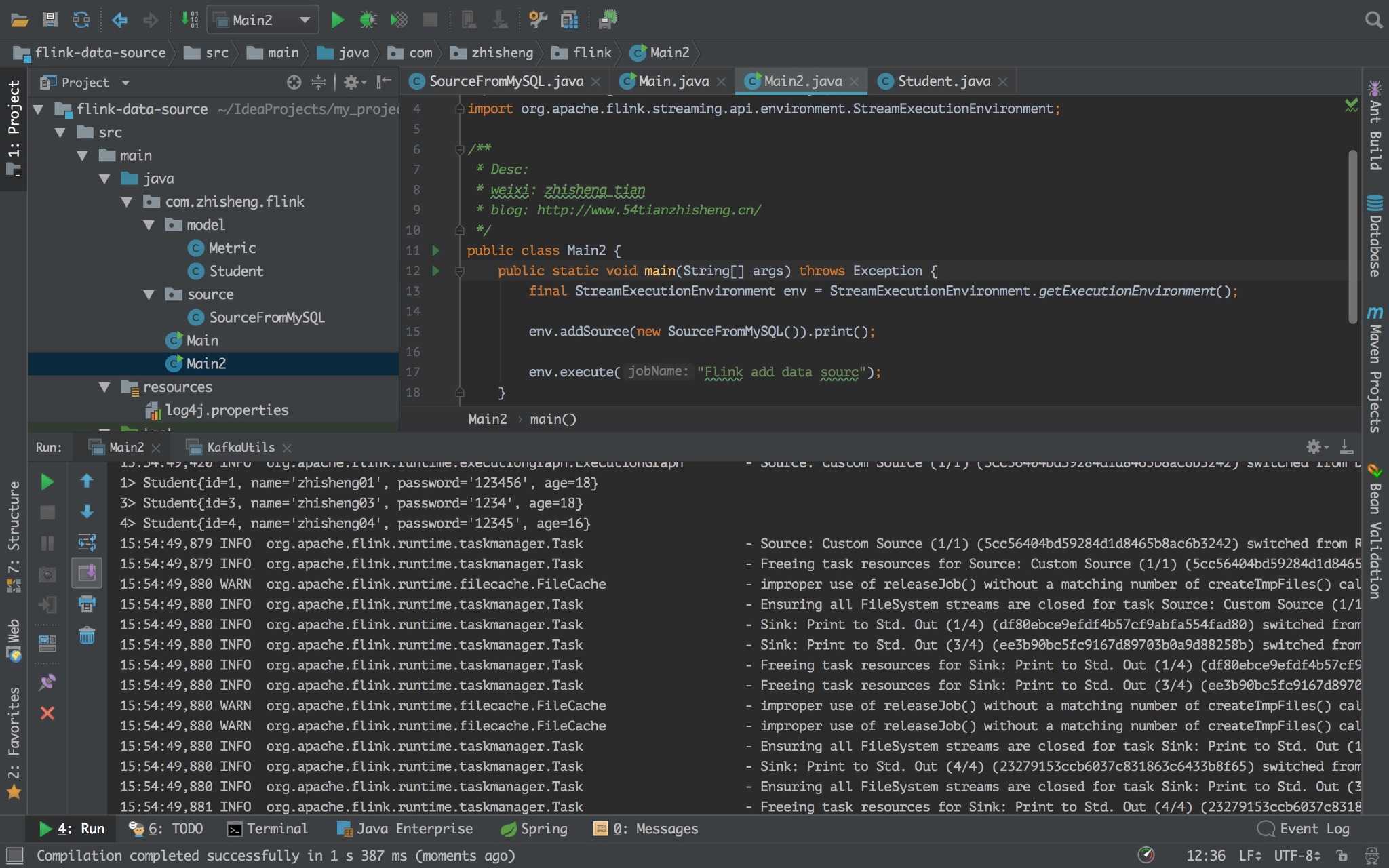
运行 Flink 程序,控制台日志中可以看见打印的 student 信息。
RichSourceFunction
从上面自定义的 Source 可以看到我们继承的就是这个 RichSourceFunction 类,那么来了解一下:
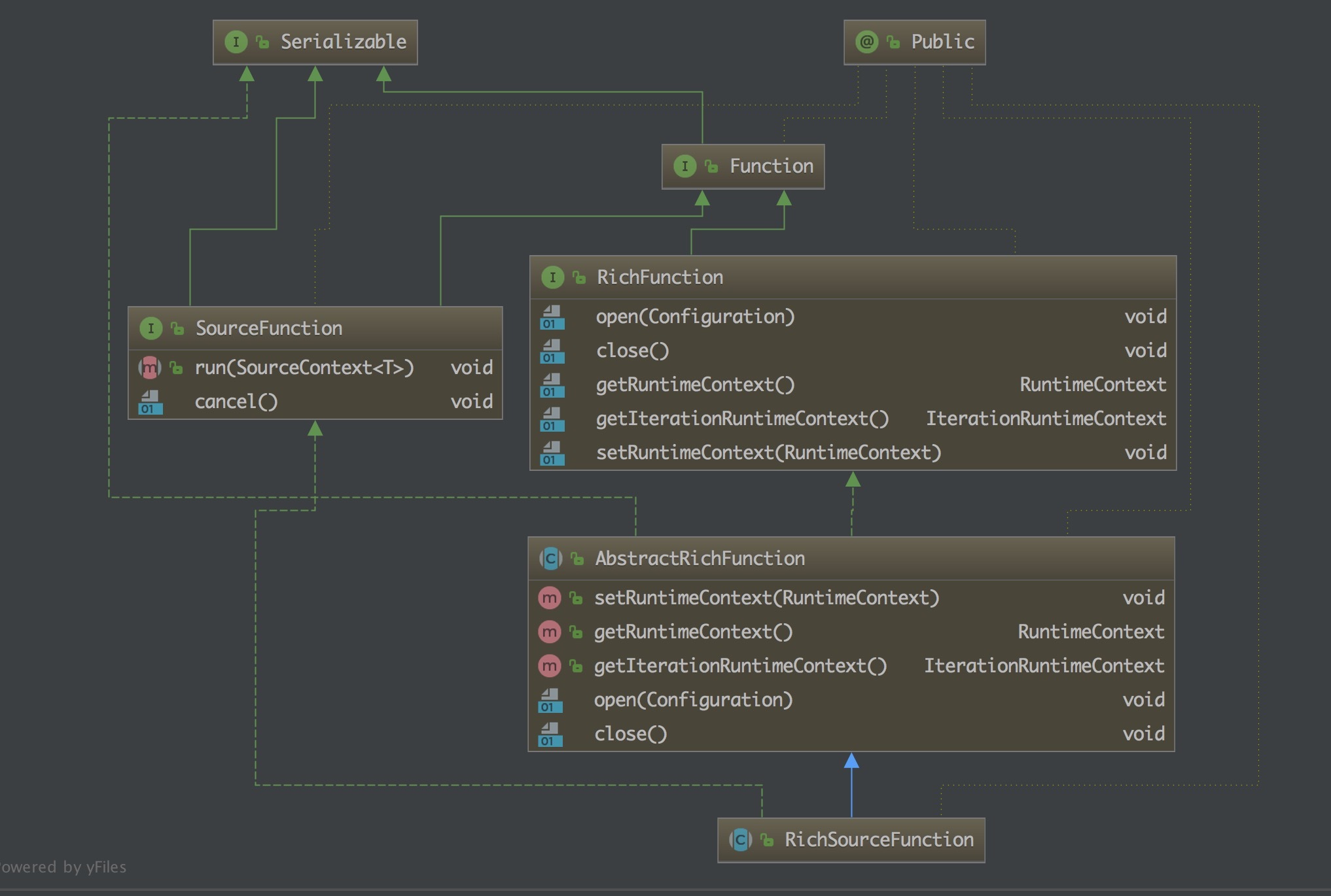
一个抽象类,继承自 AbstractRichFunction。为实现一个 Rich SourceFunction 提供基础能力。该类的子类有三个,两个是抽象类,在此基础上提供了更具体的实现,另一个是 ContinuousFileMonitoringFunction。
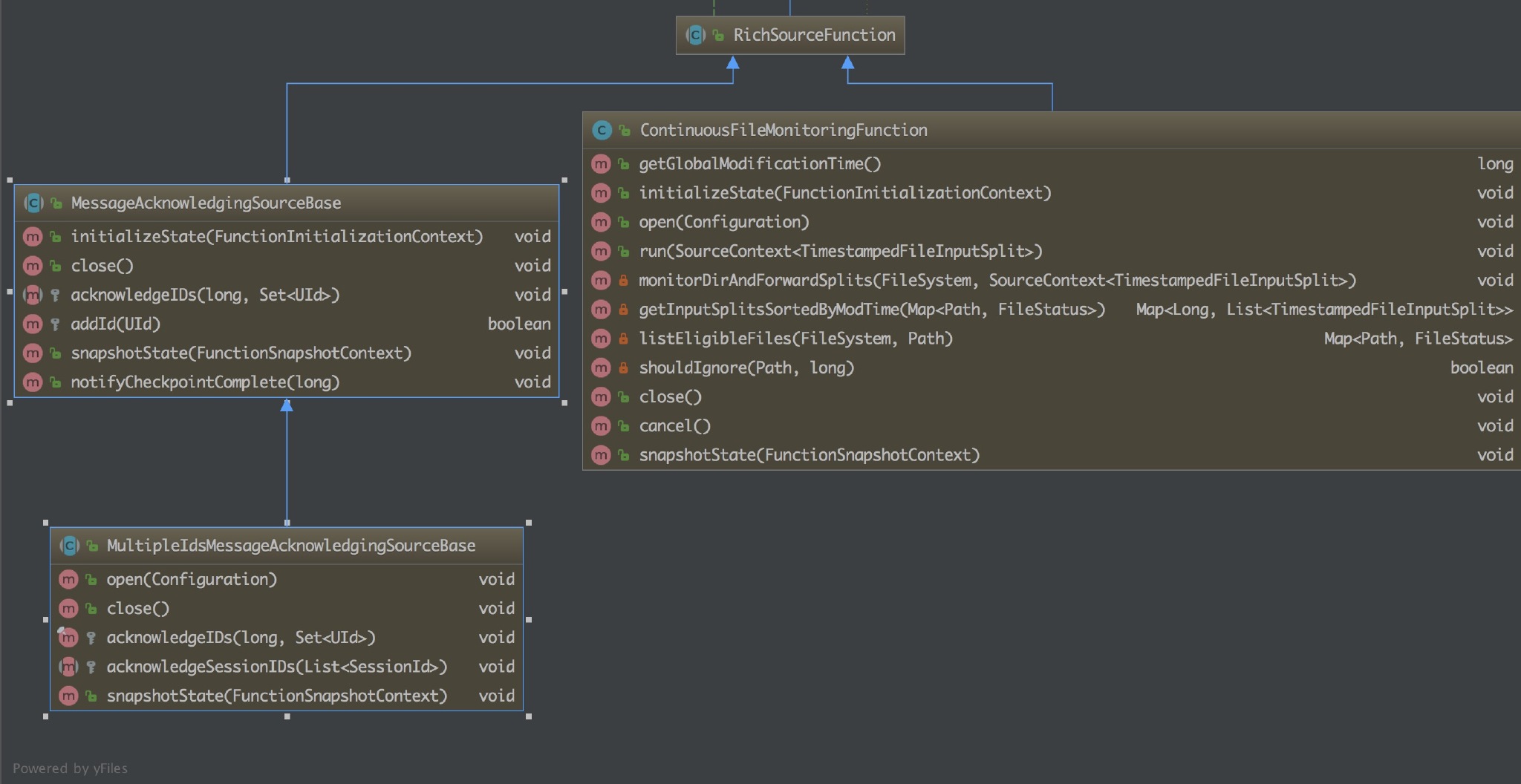
- MessageAcknowledgingSourceBase :它针对的是数据源是消息队列的场景并且提供了基于 ID 的应答机制。
- MultipleIdsMessageAcknowledgingSourceBase : 在 MessageAcknowledgingSourceBase 的基础上针对 ID 应答机制进行了更为细分的处理,支持两种 ID 应答模型:session id 和 unique message id。
- ContinuousFileMonitoringFunction:这是单个(非并行)监视任务,它接受 FileInputFormat,并且根据 FileProcessingMode 和 FilePathFilter,它负责监视用户提供的路径;决定应该进一步读取和处理哪些文件;创建与这些文件对应的 FileInputSplit 拆分,将它们分配给下游任务以进行进一步处理。
最后
本文主要讲了下 Flink 使用 Kafka Source 的使用,并提供了一个 demo 教大家如何自定义 Source,从 MySQL 中读取数据,当然你也可以从其他地方读取,实现自己的数据源 source。可能平时工作会比这个更复杂,需要大家灵活应对!
关注我
转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/10/30/flink-create-source/
微信公众号:zhisheng
另外我自己整理了些 Flink 的学习资料,目前已经全部放到微信公众号(zhisheng)了,你可以回复关键字:Flink 即可无条件获取到。另外也可以加我微信 你可以加我的微信:yuanblog_tzs,探讨技术!

更多私密资料请加入知识星球!

Github 代码仓库
https://github.com/zhisheng17/flink-learning/
以后这个项目的所有代码都将放在这个仓库里,包含了自己学习 flink 的一些 demo 和博客
博客
1、Flink 从0到1学习 —— Apache Flink 介绍
2、Flink 从0到1学习 —— Mac 上搭建 Flink 1.6.0 环境并构建运行简单程序入门
3、Flink 从0到1学习 —— Flink 配置文件详解
4、Flink 从0到1学习 —— Data Source 介绍
5、Flink 从0到1学习 —— 如何自定义 Data Source ?
6、Flink 从0到1学习 —— Data Sink 介绍
7、Flink 从0到1学习 —— 如何自定义 Data Sink ?
8、Flink 从0到1学习 —— Flink Data transformation(转换)
9、Flink 从0到1学习 —— 介绍 Flink 中的 Stream Windows
10、Flink 从0到1学习 —— Flink 中的几种 Time 详解
11、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 ElasticSearch
12、Flink 从0到1学习 —— Flink 项目如何运行?
13、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Kafka
14、Flink 从0到1学习 —— Flink JobManager 高可用性配置
15、Flink 从0到1学习 —— Flink parallelism 和 Slot 介绍
16、Flink 从0到1学习 —— Flink 读取 Kafka 数据批量写入到 MySQL
17、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RabbitMQ
18、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HBase
19、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 HDFS
20、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Redis
21、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Cassandra
22、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 Flume
23、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 InfluxDB
24、Flink 从0到1学习 —— Flink 读取 Kafka 数据写入到 RocketMQ
25、Flink 从0到1学习 —— 你上传的 jar 包藏到哪里去了
26、Flink 从0到1学习 —— 你的 Flink job 日志跑到哪里去了
28、Flink 从0到1学习 —— Flink 中如何管理配置?
29、Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
30、Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
32、为什么说流处理即未来?
33、OPPO 数据中台之基石:基于 Flink SQL 构建实时数据仓库
36、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
38、如何基于Flink+TensorFlow打造实时智能异常检测平台?只看这一篇就够了
40、Flink 全网最全资源(视频、博客、PPT、入门、实战、源码解析、问答等持续更新)
42、Flink 从0到1学习 —— 如何使用 Side Output 来分流?
源码解析
4、Flink 源码解析 —— standalone session 模式启动流程
5、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
6、Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
7、Flink 源码解析 —— 分析 Batch WordCount 程序的执行过程
8、Flink 源码解析 —— 分析 Streaming WordCount 程序的执行过程
9、Flink 源码解析 —— 如何获取 JobGraph?
10、Flink 源码解析 —— 如何获取 StreamGraph?
11、Flink 源码解析 —— Flink JobManager 有什么作用?
12、Flink 源码解析 —— Flink TaskManager 有什么作用?
13、Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
14、Flink 源码解析 —— TaskManager 处理 SubmitJob 的过程
15、Flink 源码解析 —— 深度解析 Flink Checkpoint 机制
16、Flink 源码解析 —— 深度解析 Flink 序列化机制
17、Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
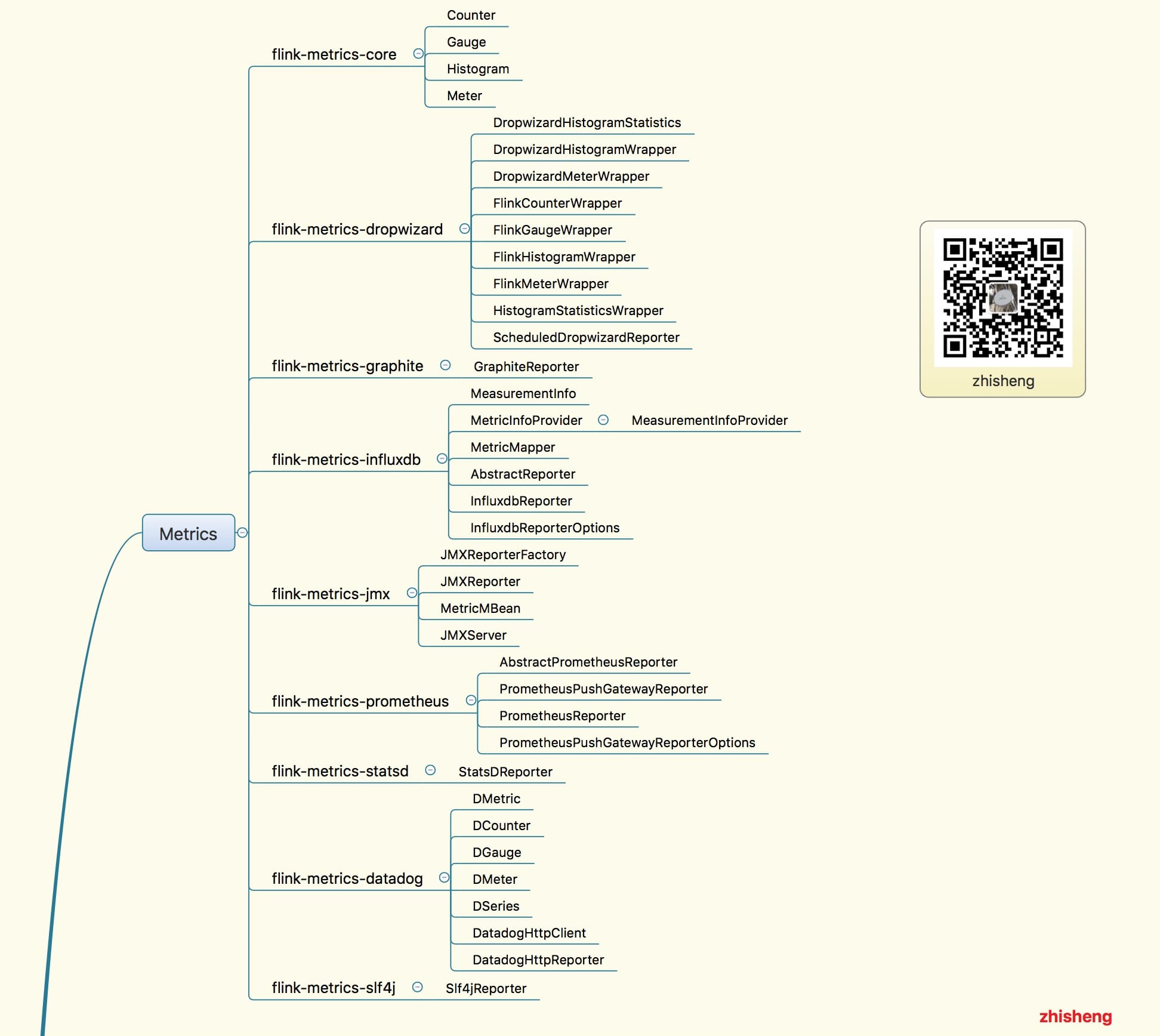
18、Flink Metrics 源码解析 —— Flink-metrics-core
19、Flink Metrics 源码解析 —— Flink-metrics-datadog
20、Flink Metrics 源码解析 —— Flink-metrics-dropwizard
21、Flink Metrics 源码解析 —— Flink-metrics-graphite
22、Flink Metrics 源码解析 —— Flink-metrics-influxdb
23、Flink Metrics 源码解析 —— Flink-metrics-jmx
24、Flink Metrics 源码解析 —— Flink-metrics-slf4j
25、Flink Metrics 源码解析 —— Flink-metrics-statsd
26、Flink Metrics 源码解析 —— Flink-metrics-prometheus
27、Flink 源码解析 —— 如何获取 ExecutionGraph ?
30、Flink Clients 源码解析
原文出处:zhisheng的博客,欢迎关注我的公众号:zhisheng
Flink 从 0 到 1 学习 —— 如何自定义 Data Source ?的更多相关文章
- Flink 从 0 到 1 学习 —— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- Flink 从0到1学习—— Flink 不可以连续 Split(分流)?
前言 今天上午被 Flink 的一个算子困惑了下,具体问题是什么呢? 我有这么个需求:有不同种类型的告警数据流(包含恢复数据),然后我要将这些数据流做一个拆分,拆分后的话,每种告警里面的数据又想将告警 ...
- Flink 从0到1学习 —— Flink 中如何管理配置?
前言 如果你了解 Apache Flink 的话,那么你应该熟悉该如何像 Flink 发送数据或者如何从 Flink 获取数据.但是在某些情况下,我们需要将配置数据发送到 Flink 集群并从中接收一 ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink 从 0 到 1 学习 —— Flink 配置文件详解
前面文章我们已经知道 Flink 是什么东西了,安装好 Flink 后,我们再来看下安装路径下的配置文件吧. 安装目录下主要有 flink-conf.yaml 配置.日志的配置文件.zk 配置.Fli ...
- Flink 从 0 到 1 学习 —— Flink Data transformation(转换)
toc: true title: Flink 从 0 到 1 学习 -- Flink Data transformation(转换) date: 2018-11-04 tags: Flink 大数据 ...
- 《从0到1学习Flink》—— 如何自定义 Data Source ?
前言 在 <从0到1学习Flink>-- Data Source 介绍 文章中,我给大家介绍了 Flink Data Source 以及简短的介绍了一下自定义 Data Source,这篇 ...
- 《从0到1学习Flink》—— 如何自定义 Data Sink ?
前言 前篇文章 <从0到1学习Flink>-- Data Sink 介绍 介绍了 Flink Data Sink,也介绍了 Flink 自带的 Sink,那么如何自定义自己的 Sink 呢 ...
- 《从0到1学习Flink》—— Flink 写入数据到 Kafka
前言 之前文章 <从0到1学习Flink>-- Flink 写入数据到 ElasticSearch 写了如何将 Kafka 中的数据存储到 ElasticSearch 中,里面其实就已经用 ...
随机推荐
- [Scikit-learn] 4.3 Preprocessing data
数据分析的重难点,就这么来了,欢迎欢迎,热烈欢迎. 4. Dataset transformations 4.3. Preprocessing data 4.3.1. Standardization, ...
- 关于webpack
webpack 是一个模块打包器,能够把所有的文件都当做是一个模块 它把所有的文件资源(js,json,css,sass,图片)都看作为模块 将这些文件资源解析处理以后,生成对应的打包文件 使用web ...
- Django REST Framework之频率限制
开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用 使用 自定义频率限制组件:utils/thottle.py class MyThrottle(BaseThrottle): ...
- python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜
本次主要爬取Top100电影榜单的电影名.主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢 首先打开要爬取的网址https://maoyan.com/board/4, ...
- Apache Thrift 的基本使用
Apache Thrift 的基本使用 可以先看看官网是如何介绍的 The Apache Thrift software framework, for scalable cross-language ...
- python高级—— 从趟过的坑中聊聊爬虫、反爬以及、反反爬,附送一套高级爬虫试题
前言: 时隔数月,我终于又更新博客了,然而,在这期间的粉丝数也就跟着我停更博客而涨停了,唉 是的,我改了博客名,不知道为什么要改,就感觉现在这个名字看起来要洋气一点. 那么最近到底咋不更新博客了呢?说 ...
- rabbitmq linux卸载
rabbitmq是运行在erlang环境下的,所以卸载时应将erlang卸载. 1.卸载rabbitmq相关 卸载前先停掉rabbitmq服务,执行命令 $ service rabbitmq-serv ...
- javaweb技术入门
JavaWeb巩固和进阶 1.如何配置外部应用? 方法一: server.xml 在<Host>中添加如下配置 <Context path="/xxx" docB ...
- angular 配置开发环境、测试环境、生产环境
1. 配置开发环境.测试环境.生产环境 (1). environment.ts - 开发环境: 用于程序开发 (创建项目时自动生成) export const environment = { prod ...
- GitHub项目徽标
前言 GitHub徽标,GitHub Badge,你也可以叫它徽章.就是在项目README中经常看到的那些表明构建状态或者版本等信息的小图标.就像这样: 这些好看的小图标不仅简洁美观,而且包含了清晰易 ...