opencv::GMM(高斯混合模型)
GMM方法概述:基于高斯混合模型期望最大化。
高斯混合模型 (GMM)
高斯分布与概率密度分布 - PDF
初始化
初始化EM模型:
Ptr<EM> em_model = EM::create();
em_model->setClustersNumber(numCluster);
em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL);
em_model->setTermCriteria(TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 100, 0.1));
em_model->trainEM(points, noArray(), labels, noArray());

#include <opencv2/opencv.hpp>
#include <iostream> using namespace cv;
using namespace cv::ml;
using namespace std; int main(int argc, char** argv) {
Mat img = Mat::zeros(, , CV_8UC3);
RNG rng(); Scalar colorTab[] = {
Scalar(, , ),
Scalar(, , ),
Scalar(, , ),
Scalar(, , ),
Scalar(, , )
}; int numCluster = rng.uniform(, );
printf("number of clusters : %d\n", numCluster); int sampleCount = rng.uniform(, );
Mat points(sampleCount, , CV_32FC1);
Mat labels; // 生成随机数
for (int k = ; k < numCluster; k++) {
Point center;
center.x = rng.uniform(, img.cols);
center.y = rng.uniform(, img.rows);
Mat pointChunk = points.rowRange(k*sampleCount / numCluster,
k == numCluster - ? sampleCount : (k + )*sampleCount / numCluster); rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));
} randShuffle(points, , &rng);
//初始化EM模型
Ptr<EM> em_model = EM::create();
em_model->setClustersNumber(numCluster);
em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL);
em_model->setTermCriteria(TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, , 0.1));
em_model->trainEM(points, noArray(), labels, noArray()); // 处理每个像素
Mat sample(, , CV_32FC1);
for (int row = ; row < img.rows; row++) {
for (int col = ; col < img.cols; col++) {
sample.at<float>() = (float)col;
sample.at<float>() = (float)row;
int response = cvRound(em_model->predict2(sample, noArray())[]);
Scalar c = colorTab[response];
//填充
circle(img, Point(col, row), , c*0.75, -);
}
} // 画出采样数据
for (int i = ; i < sampleCount; i++) {
Point p(cvRound(points.at<float>(i, )), points.at<float>(i, ));
circle(img, p, , colorTab[labels.at<int>(i)], -);
} imshow("GMM-EM Demo", img); waitKey();
return ;
}
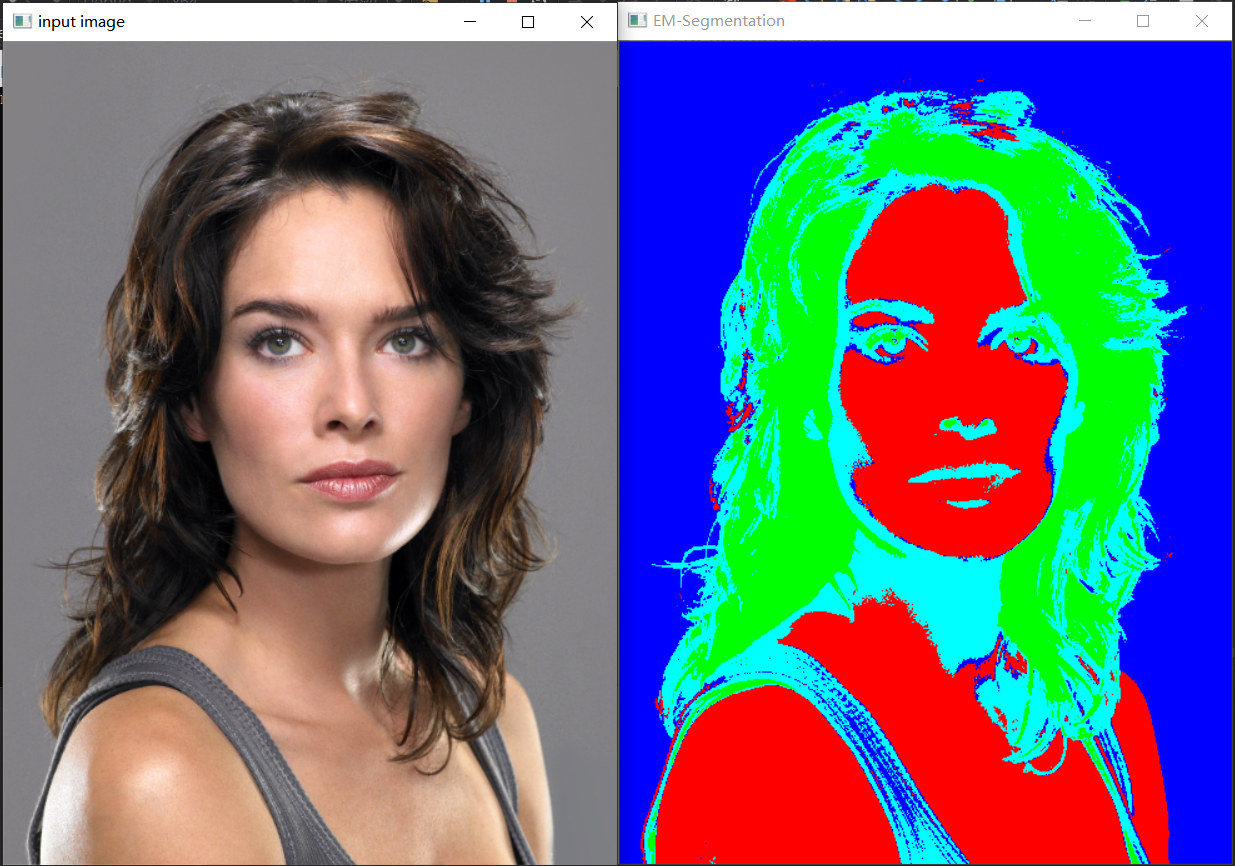
#include <opencv2/opencv.hpp>
#include <iostream> using namespace cv;
using namespace cv::ml;
using namespace std; int main(int argc, char** argv) {
Mat src = imread("D:/images/cvtest.png");
if (src.empty()) {
printf("could not load iamge...\n");
return -;
}
namedWindow("input image", CV_WINDOW_AUTOSIZE);
imshow("input image", src); // 初始化
int numCluster = ;
const Scalar colors[] = {
Scalar(, , ),
Scalar(, , ),
Scalar(, , ),
Scalar(, , )
}; int width = src.cols;
int height = src.rows;
int dims = src.channels();
int nsamples = width * height;
Mat points(nsamples, dims, CV_64FC1);
Mat labels;
Mat result = Mat::zeros(src.size(), CV_8UC3); // 图像RGB像素数据转换为样本数据
int index = ;
for (int row = ; row < height; row++) {
for (int col = ; col < width; col++) {
index = row * width + col;
Vec3b rgb = src.at<Vec3b>(row, col);
points.at<double>(index, ) = static_cast<int>(rgb[]);
points.at<double>(index, ) = static_cast<int>(rgb[]);
points.at<double>(index, ) = static_cast<int>(rgb[]);
}
} // EM Cluster Train
Ptr<EM> em_model = EM::create();
em_model->setClustersNumber(numCluster);
em_model->setCovarianceMatrixType(EM::COV_MAT_SPHERICAL);
em_model->setTermCriteria(TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, , 0.1));
em_model->trainEM(points, noArray(), labels, noArray()); // 对每个像素标记颜色与显示
Mat sample(dims, , CV_64FC1);
double time = getTickCount();
int r = , g = , b = ;
for (int row = ; row < height; row++) {
for (int col = ; col < width; col++) {
/*index = row * width + col;
int label = labels.at<int>(index, 0);
Scalar c = colors[label];
result.at<Vec3b>(row, col)[0] = c[0];
result.at<Vec3b>(row, col)[1] = c[1];
result.at<Vec3b>(row, col)[2] = c[2];*/ b = src.at<Vec3b>(row, col)[];
g = src.at<Vec3b>(row, col)[];
r = src.at<Vec3b>(row, col)[];
sample.at<double>() = b;
sample.at<double>() = g;
sample.at<double>() = r;
int response = cvRound(em_model->predict2(sample, noArray())[]);
Scalar c = colors[response];
result.at<Vec3b>(row, col)[] = c[];
result.at<Vec3b>(row, col)[] = c[];
result.at<Vec3b>(row, col)[] = c[];
}
}
printf("execution time(ms) : %.2f\n", (getTickCount() - time) / getTickFrequency() * );
imshow("EM-Segmentation", result); waitKey();
return ;
}
opencv::GMM(高斯混合模型)的更多相关文章
- GMM高斯混合模型学习笔记(EM算法求解)
提出混合模型主要是为了能更好地近似一些较复杂的样本分布,通过不断添加component个数,能够随意地逼近不论什么连续的概率分布.所以我们觉得不论什么样本分布都能够用混合模型来建模.由于高斯函数具有一 ...
- K-Means(K均值)、GMM(高斯混合模型),通俗易懂,先收藏了!
1. 聚类算法都是无监督学习吗? 什么是聚类算法?聚类是一种机器学习技术,它涉及到数据点的分组.给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组.理论上,同一组中的数据点应该具有相似 ...
- GMM高斯混合模型 学习(2)
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvaHpxMjAwODExMjExMDc=/font/5a6L5L2T/fontsize/400/fill/I0 ...
- opencv的高斯混合模型
http://blog.jasonding.top/2015/04/05/Machine%20Learning/%E3%80%90%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%8 ...
- EM算法和高斯混合模型GMM介绍
EM算法 EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{ ...
- 高斯混合模型GMM与EM算法的Python实现
GMM与EM算法的Python实现 高斯混合模型(GMM)是一种常用的聚类模型,通常我们利用最大期望算法(EM)对高斯混合模型中的参数进行估计. 1. 高斯混合模型(Gaussian Mixture ...
- paper 62:高斯混合模型(GMM)参数优化及实现
高斯混合模型(GMM)参数优化及实现 (< xmlnamespace prefix ="st1" ns ="urn:schemas-microsoft-com:of ...
- 高斯混合模型(理论+opencv实现)
查资料的时候看了一个不文明的事情,转载别人的东西而不标注出处,结果原创无人知晓,转载很多人评论~~标注了转载而不说出处这样的人有点可耻! 写在前面: Gaussian Mixture Model (G ...
- 高斯混合模型(GMM)
复习: 1.概率密度函数,密度函数,概率分布函数和累计分布函数 概率密度函数一般以大写“PDF”(Probability Density Function),也称概率分布函数,有的时候又简称概率分布函 ...
随机推荐
- MySQL 部署分布式架构 MyCAT (二)
安装 MyCAT 安装 java 环境(db1) yum install -y java 下载 Mycat-server-1.6.5-release-20180122220033-linux.tar. ...
- __rpm.so: underfined symbol : rpmpkgverifySigs 故障分析
前言: 近期漏洞修复频繁,各种组件需要升级,经多次碰撞,发现 yum update 来升级组件是最有效最安全的方式(绿盟通过版本比对的扫描结果可以忽略). 然而,各家的设备各家管,一到升级就发现一堆问 ...
- 01day-webpack
<!-- .sass后缀的文件名 比较老了 现在它的后缀名是.scss 其实他们是同一个东西 只是 后缀名发生了变化 以 .sass写的文件的内容是 他没有括号 没有分号 有点怪 它跟新为了.s ...
- 第36课 经典问题(下)----关于string的疑问
实例1: 下面的代码输出什么,为什么? #include <iostream> #include <string> using namespace std; int main( ...
- pwn-pwn2
环境说明 Ubuntu 16.04 pwntool IDA gdb-peda 先丢到Ubuntu看看文件的类型 64位 然后看看保护机制,发现没有保护机制 然后丢到IDA看看 F5查看伪代码 ma ...
- pycharm 快速启动Django项目和python程序
Django 设置 *.py
- 【转】认识JWT
1. JSON Web Token是什么 JSON Web Token (JWT)是一个开放标准(RFC 7519),它定义了一种紧凑的.自包含的方式,用于作为JSON对象在各方之间安全地传输信息.该 ...
- lua 8 字符串
转自:http://www.runoob.com/lua/lua-strings.html 字符串或串(String)是由数字.字母.下划线组成的一串字符. Lua 语言中字符串可以使用以下三种方式来 ...
- 【声明式事务】Spring声明式事务实现(三)
以MyBatis为例. 一.基于注解的声明式事务配置 1. 添加tx名字空间 xmlns:tx="http://www.springframework.org/schema/tx" ...
- java调用含第三方库的py文件
这是一个心酸的历程. py文件如下: 这里调用出现的问题主要是第三方包的问题,因为你的py文件里可能含有很多三方库文件,jython的jar包里可能不含有这个,所以这时需要你找到你已有三方库文件的ex ...