12-UA池和代理池
一、UA池和代理池
1、UA池
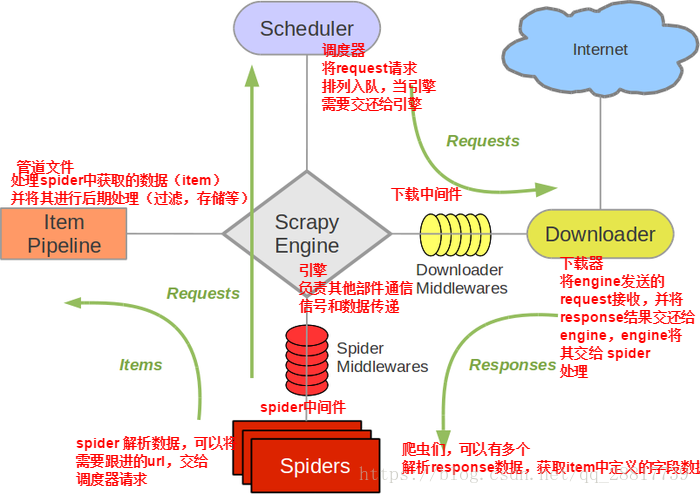
scrapy的下载中间件:
下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件。
作用:
(1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系列处理。比如设置请求的 User-Agent,设置代理等
(2)在下载器完成将Response传递给引擎中,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent ,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
UA池作用:尽可能多的将scrapy框架中的请求伪装成不同类型的浏览器以及不同电脑的身份。
- 操作流程:
1.下载中间件中拦截请求
2.将拦截到的请求的请求头信息中的UA进行伪装
3.在配置文件中开启下载中间件
代码展示:(只需要看proccess_request方法)
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from scrapy.http import HtmlResponse
import random
from time import sleep class WangyixinwenDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
# 代理池
PROXY_http = [
'153.180.102.104:80',
'195.208.131.189:56055',
]
PROXY_https = [
'120.83.49.90:9000',
'95.189.112.214:35508',
] def process_request(self, request, spider):
"""
在这里可以设置UA,如果要设置IP就需要等自己IP出现问题再前去process_exception中设置代理IP
但最后一定要返回request对象
:param request:
:param spider:
:return:
"""
# ua = random.choice(self.user_agent_list)#随机选择一个元素(反爬策略(即不同浏览器和机型))出来
# request.headers["User-Agent"] = ua
#return request#将修正的request对象重新进行发送
return None def process_response(self, request, response, spider):
#刚才响应体缺失,因此从这里我们应该重新返回新的响应体
#这里要用到爬虫程序中的urls,判断url是否在里面,在urls里面的就会出现响应缺失,
# 、因此需要返回新的响应体
if request.url in spider.urls:
#响应缺失是因为是动态加载数据,因此我们配合selenium使用
#在这里实例化selenium的话会被实例化多次,然而selenium只需要实例化一次,
#这个时候我们可以将selenium放在实例化一次的爬虫程序开始的时候,实例化完成引入
sleep(2)
bro = spider.bro.get(url=request.url)#浏览器中发送请求
sleep(1)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(1.5)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(0.7)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
sleep(1)
spider.bro.execute_script("window.scrollTo(0,document.body.scrollHeight)")
#发送到请求我们需要获取浏览器当前页面的源码数据 获取数据之前需要翻滚页面
page_text = spider.bro.page_source
#改动返回响应对象 scrapy提供了一个库url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request
new_response = HtmlResponse(url=request.url,body=page_text,encoding="utf-8",request=request)
return new_response
else:
return response
#提交完新的响应体之后,去设置将下载中间件打开 def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
#如果抛出异常,那么就换代理IP
# 代理ip的设定
# if request.url.split(':')[0] == 'http':
# request.meta['proxy'] = random.choice(self.PROXY_http)
# else:
# request.meta['proxy'] = random.choice(self.PROXY_https)
# # 将修正后的请求对象重新进行请求发送
# return request
pass
然后去配置文件开启中间件settings.py:
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543,
}
2、代理池
作用:尽可能多的将scrapy框架中的请求的IP设置成不同的,当服务器禁止自己电脑的ip的时候将自动调用process_exception中的ip代理设置
操作流程:
1.在下载中间件中拦截请求
2.将拦截到的请求的IP修改成某一代理IP
3.在配置文件中开启下载中间件
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception. # Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
#如果抛出异常,那么就换代理IP
# 代理ip的设定
if request.url.split(':')[0] == 'http':
request.meta['proxy'] = random.choice(self.PROXY_http)
else:
request.meta['proxy'] = random.choice(self.PROXY_https)
# 将修正后的请求对象重新进行请求发送
return request
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'Wangyixinwen.middlewares.WangyixinwenDownloaderMiddleware': 543,
}
拦截请求直接在上面中间件代码的process_exception中,配置文件也在上面。
12-UA池和代理池的更多相关文章
- 10 UA池和代理池
在Scrapy中,引擎和下载器之间有一个组件,叫下载中间件(Downloader Middlewares).因它是介于Scrapy的request/response处理的钩子,所以有2方面作用: (1 ...
- scrapy下载中间件,UA池和代理池
一.下载中间件 框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请 ...
- 爬虫的UA池和代理池
爬虫的UA池和代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下 ...
- 14.UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - ...
- UA池和代理池
scrapy下载中间件 UA池 代理池 一.下载中间件 先祭出框架图: 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎 ...
- UA池和代理池在scrapy中的应用
一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器过程中, 下载中间件可以对请求进行一系 ...
- 爬虫开发13.UA池和代理池在scrapy中的应用
今日概要 scrapy下载中间件 UA池 代理池 今日详情 一.下载中间件 下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: ( ...
- 14,UA池和代理池
今日概要 scrapy下载中间件 UA池 代理池 一,下载中间件(Downloader Middlewares) 位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引擎将请求传递给下载器 ...
- scrapy的UA池和代理池
一.下载中间件(Downloader Middlewares) 框架图如下 下载中间件(Downloader Middlewares)位于scrapy引擎和下载器之间的一层组件. - 作用: (1)引 ...
随机推荐
- 单域MPLS 虚拟私有网络的整个详解配置过程(可跟做)
1.PE1和P和PE2之间跑IGP协议 运营商里面首选的还是ISIS协议我们实验的话,用的是OSPF协议 R3的IP地址和OSPF配置 [R3]display ip int brief *down: ...
- 12c新特性 在线操作数据文件
我们都知道,oracle pre-12c之前,若是想要把一个数据文件改名或者迁移, 必须在归档模式下先把这个数据文件offline之后, 然后进行OS上的copy或者rename 操作, 最后在sql ...
- 以太网驱动的流程浅析(三)-ifconfig的-19错误最底层分析【原创】
以太网驱动流程浅析(三)-ifconfig的-19错误最底层分析 Author:张昺华 Email:920052390@qq.com Time:2019年3月23日星期六 此文也在我的个人公众号以及& ...
- 基于django的个人博客网站建立(六)
基于django的个人博客网站建立(六) 前言 今天主要完成的是项目在腾讯云服务器上ubuntu16.04+django+mysql+uwsig+nginx的部署过程网站效果可点击这里访问 主要内容 ...
- java基础 - 形参和实参,值传递和引用传递
形参和实参 形参:就是形式参数,用于定义方法的时候使用的参数,是用来接收调用者传递的参数的. 形参只有在方法被调用的时候,虚拟机才会分配内存单元,在方法调用结束之后便会释放所分配的内存单元. 因此,形 ...
- CALL和RET指令实验
实验10 1.在屏幕8行3列,用绿色显示data段中的字符串 assume cs:code data segment db data ends code segment start: ;行 ;列 ;颜 ...
- Spring中,关于IOC和AOP的那些事
一.spring 的优点? 1.降低了组件之间的耦合性 ,实现了软件各层之间的解耦 2.可以使用容易提供的众多服务,如事务管理,消息服务等 3.容器提供单例模式支持 4.容器提供了AOP技术,利用它很 ...
- (转)滑动平均法、滑动平均模型算法(Moving average,MA)
原文链接:https://blog.csdn.net/qq_39521554/article/details/79028012 什么是移动平均法? 移动平均法是用一组最近的实际数据值来预测未来一期或几 ...
- 对python中等值和大小比较
等值.大小比较 在python中,只要两个对象的类型相同,且它们是内置类型(字典除外),那么这两个对象就能进行比较.关键词:内置类型.同类型.所以,两个对象如果类型不同,就没法比较,比如数值类型的数值 ...
- GO 使用静态链接库编译 生成可执行文件 使用第三方 .a 文件,无源码构造
go build 和 go install 都需要使用源码来进行编译.但是有时候我们只有.a或者.so文件.并不能获取到第三方库的源码,这时我们需要静态链接库编译的技巧: 上图是实验前的文件分布. 使 ...