Python 爬虫从入门到进阶之路(十一)
之前的文章我们介绍了一下 Xpath 模块,接下来我们就利用 Xpath 模块爬取《糗事百科》的糗事。
之前我们已经利用 re 模块爬取过一次糗百,我们只需要在其基础上做一些修改就可以了,为了保证项目的完整性,我们重新再来一遍。
我们要爬取的网站链接是 https://www.qiushibaike.com/text/page/1/ 。
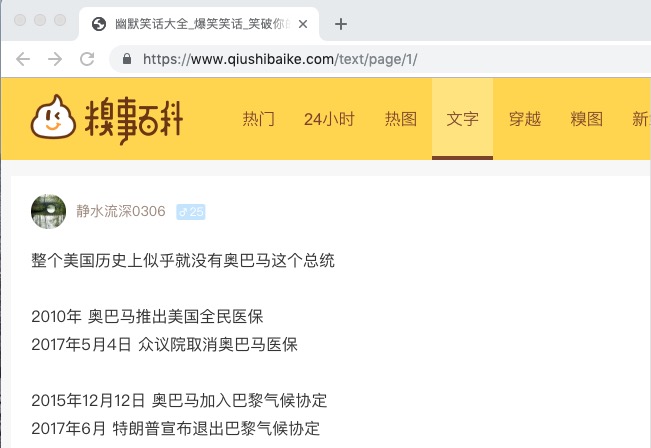
我们通过 Xpath Helper 的谷歌插件经过分析获取到我们想要的内容为: //div[@class="content"]/span[1]
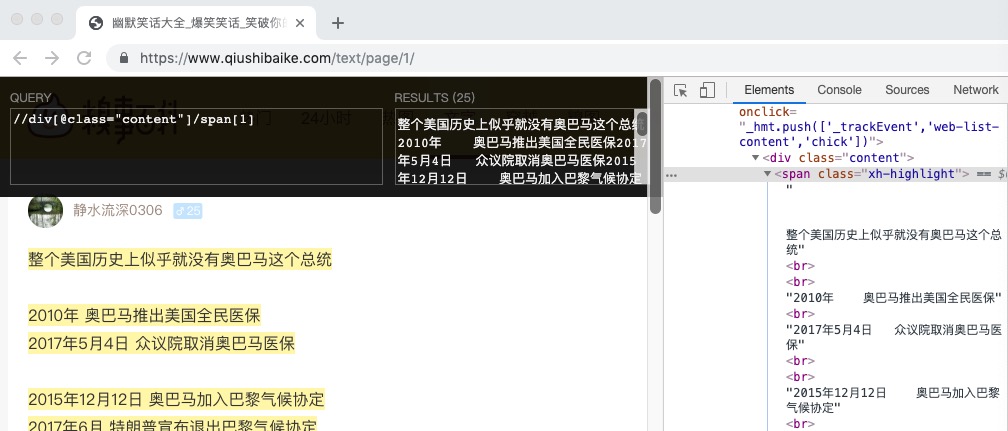
然后我们就可以通过 text() 来获取里面的内容了, //div[@class="content"]/span[1]/text()
import urllib.request
from lxml import etree
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context url = "https://www.qiushibaike.com/text/page/1/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 解析html 为 HTML 文档
selector = etree.HTML(html)
content_list = selector.xpath('//div[@class="content"]/span[1]/text()')
print(content_list)
输出结果为:
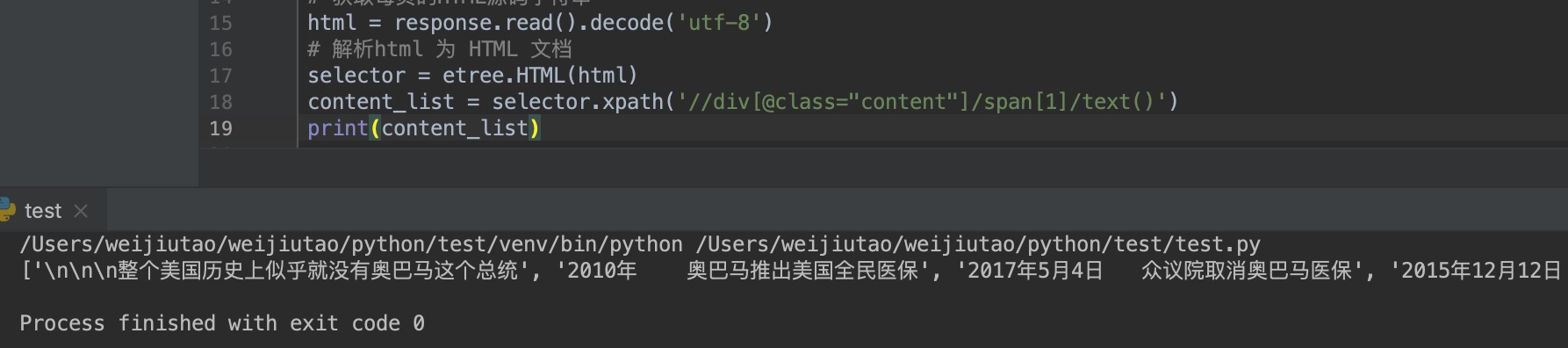
从上面的输出结果可以看出我们已经拿到了我们想要的数据,并且是一个列表类型,我们对列表进行操作扥别拿到糗事再存储到本地即可。
for item in item_list:
item = item.replace("\n", "")
self.writePage(item)
上面的代码中 item_list 即为我们上面所获取到的 content_list 列表,在之前通过 re 模块获取数据时通过对列表的内容分析,我们发现有 <span> ,<span class="contentForAll">查看全文,</span>,<br/>,\n 等多余内容,而通过 Xpath 只有 \n 为多余,我们通过 replace 方法将其转为空,剩下的就是我们想要的内容了,接下来就是存储到本地即可了。
上面就可以实现一个获取 糗事百科 的糗事的简单爬虫,但是只能爬取单个页面的内容,通过分析 url 我们发现 https://www.qiushibaike.com/text/page/1/ 中最后的 1 即为页码,我们就可以根据这个页码逐一爬取更多页面的内容,最终的代码如下:
import urllib.request
from lxml import etree
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context class Spider:
def __init__(self):
# 初始化起始页位置
self.page = 1
# 爬取开关,如果为True继续爬取
self.switch = True def loadPage(self):
"""
作用:打开页面
"""
url = "https://www.qiushibaike.com/text/page/" + str(self.page) + "/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 解析html 为 HTML 文档
selector = etree.HTML(html)
content_list = selector.xpath('//div[@class="content"]/span[1]/text()')
# 调用dealPage() 处理糗事里的杂七杂八
self.dealPage(content_list) def dealPage(self, item_list):
"""
@brief 处理得到的糗事列表
@param item_list 得到的糗事列表
@param page 处理第几页
"""
for item in item_list:
item = item.replace("\n", "")
self.writePage(item) def writePage(self, text):
"""
@brief 将数据追加写进文件中
@param text 文件内容
"""
myFile = open("./qiushi.txt", 'a') # 追加形式打开文件
myFile.write(text + "\n\n")
myFile.close() def startWork(self):
"""
控制爬虫运行
"""
# 循环执行,直到 self.switch == False
while self.switch:
# 用户确定爬取的次数
self.loadPage()
command = input("如果继续爬取,请按回车(退出输入quit)")
if command == "quit":
# 如果停止爬取,则输入 quit
self.switch = False
# 每次循环,page页码自增1
self.page += 1
print("爬取结束!") if __name__ == '__main__':
# 定义一个Spider对象
qiushiSpider = Spider()
qiushiSpider.startWork()
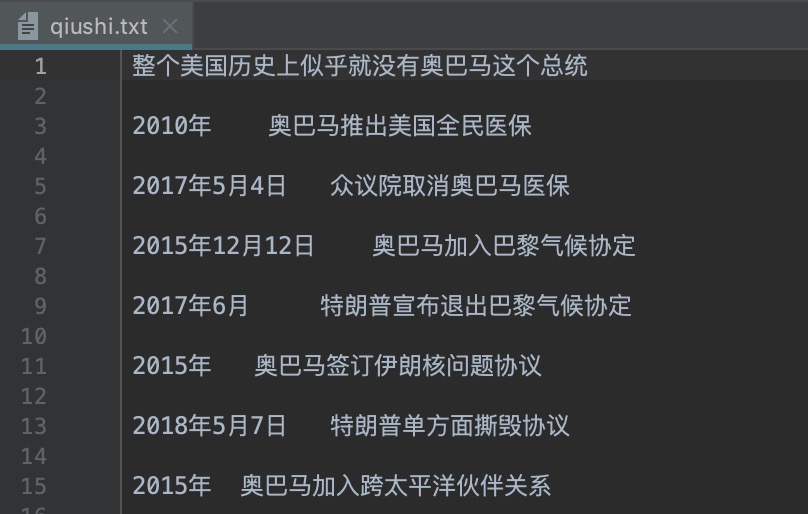
最终会在本地添加一个 qiushi.txt 的文件,结果如下:
Python 爬虫从入门到进阶之路(十一)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- Emoji:搜索将与您找到表情符号背后的故事
眼下.秉已经开始支持emoji搜索,这意味着,你可以插入或粘贴系列emoji表情,让我们的爱.微笑.食品等..些表情随意组合,必应总会带给你非常多有趣的但却没有不论什么实际用途的搜索结果. 这是一项非 ...
- ATS项目更新(2) 命令行编译Studio解决方案
1: rem "D:\Microsoft Visual Studio 8\SDK\v2.0\Bin\sdkvars.bat" 2: D: 3: cd ..\..\..\..\..\ ...
- git建tag备忘
1.git tag -a v1.1.8_20180613 -m '实时上传位置等功能提交测试' 2. git push origin v1.1.8_20180613
- uboot通过使用U磁盘引导内核RT5350成功
今天,在下次尝试使用16G 的u菜.这让两个分区,A位于zimage.一家商店rootfs:在uboot加载分区zimage并成功推出! RT5350 # fatload usb 0:1 0x80c0 ...
- 图形化界面安装oracle报错Could not execute auto check for display colors using command /usr/bin/xdpyinfo. Check if the DISPLAY variable is set.
问题描述: 在Linux + oracle 安装时,采有root 帐号登录x-windows 界面,然后 $su oracle 登录录安装Oracle 报以下错误: >>> Coul ...
- 2-18-搭建mysql集群实现高可用
1 环境清理以及安装 1.1 mysql旧版本清除 准备5台虚拟机,分配如下 mysql管理结点:xuegod1.cn IP:192.168.10.31 (安装server.clien ...
- LINQ查询表达式---------from子句
LINQ查询表达式---------from子句 LINQ的查询由3基本部分组成:获取数据源,创建查询,执行查询. //1.获取数据源 List<, , , , , }; //创建查询 var ...
- WebAPI增加Area以支持无限层级同名Controller
原文:WebAPI增加Area以支持无限层级同名Controller 微软的WebAPI默认实现逻辑 默认实现中不支持同名Controller,否则在访问时会报HttpError,在网上找到了各种路由 ...
- 轮廓追踪与C#实现
原文:轮廓追踪与C#实现 轮廓追踪是图像处理中常见的方法,主要目的是追踪二值图像中目标物体的外轮廓,所得结果为单像素闭合轮廓. 流 程: 1. 确定种子点,即追踪的起始像素(如最左上方在轮 ...
- Android CTS Test failed to run to conmpletion 测试超时问题
引用“Android cts all pass 全攻略”里面的一段话: ❀ testcase timeout 测试某个testcase的时候一直出现 “........”,迟迟没有pass或者fail ...