flink 流式处理中如何集成mybatis框架
flink 中自身虽然实现了大量的connectors,如下图所示,也实现了jdbc的connector,可以通过jdbc 去操作数据库,但是flink-jdbc包中对数据库的操作是以ROW来操作并且对数据库事务的控制比较死板,有时候操作关系型数据库我们会非常怀念在java web应用开发中的非常优秀的mybatis框架,那么其实flink中是可以自己集成mybatis进来的。 我们这里以flink 1.9版本为例来进行集成。
如下图为flink内部自带的flink-jdbc:
创建一个flink的流式处理项目,引入flink的maven依赖和mybatis依赖(注意这里引入的是非spring版本,也就是mybatis的单机版):
<properties> <flink.version>1.9.0</flink.version>
</properties>
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.2</version>
</dependency>
<!-- flink java 包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
maven依赖引入以后,那么需要在resources下面定义mybatis-config.xml 配置:
mybatis-config.xml 需要定义如下配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<typeAlias alias="BankBillPublic" type="xxxx.xx.xx.BankBillPublic" />
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://xx.xx.xx.xx:3306/hue?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&autoReconnect=true" />
<property name="username" value="xxxx" />
<property name="password" value="xxxx*123%" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/xxxxxMapper.xml" />
</mappers>
</configuration>
typeAlias 标签中为自定义的数据类型,然后在xxxxxMapper.xml 中parameterType或者resultType就可以直接用这种定义的数据类型。
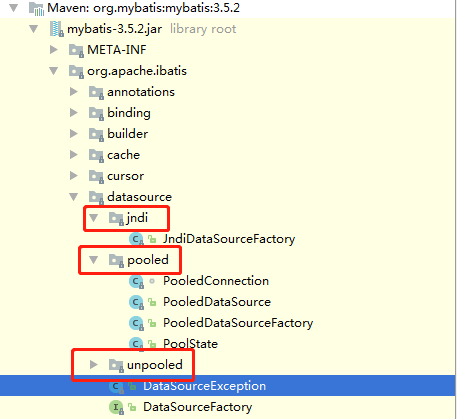
dataSource type="POOLED" 我们使用的是mybatis中的POOLED 类型,也就是连接池的方式去使用。默认支持如下这三种类型。
我们也可以使用阿里巴巴开源的druid连接池,那么就需要引入对应的maven依赖,如下所示:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.14</version>
</dependency>
然后定义一个对应的druid的DataSource,如下所示:
import java.sql.SQLException;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.ibatis.datasource.DataSourceFactory;
import com.alibaba.druid.pool.DruidDataSource; public class DruidDataSourceFactory implements DataSourceFactory {
private Properties props; @Override
public DataSource getDataSource() {
DruidDataSource dds = new DruidDataSource();
dds.setDriverClassName(this.props.getProperty("driver"));
dds.setUrl(this.props.getProperty("url"));
dds.setUsername(this.props.getProperty("username"));
dds.setPassword(this.props.getProperty("password"));
// 其他配置可以根据MyBatis主配置文件进行配置
try {
dds.init();
} catch (SQLException e) {
e.printStackTrace();
}
return dds;
} @Override
public void setProperties(Properties props) {
this.props = props;
}
}
之后就可以mybatis的配置中使用了,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<typeAlias alias="BankBillPublic" type="xxxx.xx.xx.BankBillPublic" />
<typeAlias alias="DRUID"
type="com.xx.mybatis.druid.utils.DruidDataSourceFactory" />
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="DRUID">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://xx.xx.xx.xx:3306/hue?characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&allowMultiQueries=true&autoReconnect=true" />
<property name="username" value="xxxx" />
<property name="password" value="xxxx*123%" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/xxxxxMapper.xml" />
</mappers>
</configuration>
<mappers> 下面为定义的mybatis 的xxxxxMapper文件。里面放置的都是sql语句。
本文作者张永清,转载请注明出处:flink 流式处理中如何集成mybatis框架
xxxxxMapper.xml 中的sql示例:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="xx.xx.bigdata.flink.xx.xx.mapper.UserRelaInfoMapper">
<!--查询关键字匹配 -->
<select id="queryUserRelaInfo" parameterType="String" resultType="UserRelaInfo">
SELECT id AS id,
USER_NAME AS userName,
APPL_IDCARD AS applIdCard,
PEER_USER AS peerUser,
RELA_TYPE AS relaType,
CREATE_USER AS createUser,
CREATE_TIME AS createTime
FROM USER_RELA_INFO
<where>
<if test="applIdCard != null">
APPL_IDCARD=#{applIdCard}
</if>
<if test="peerUser != null">
AND PEER_USER=#{peerUser}
</if>
</where>
</select>
</mapper>
定义Mapper,一般可以定义一个interface ,和xxxxxMapper.xml中的namespace保持一致
注意传入的参数一般加上@Param 注解,传入的参数和xxxxxMapper.xml中需要的参数保持一致
public interface UserRelaInfoMapper {
List<UserRelaInfo> queryUserRelaInfo(@Param("applIdCard")String applIdCard,@Param("peerUser") String peerUser);
}
定义SessionFactory工厂(单例模式):
/**
*
* sqlsession factory 单例 事务设置为手动提交
*/
public class MybatisSessionFactory {
private static final Logger LOG = LoggerFactory.getLogger(MybatisSessionFactory.class);
private static SqlSessionFactory sqlSessionFactory;
private MybatisSessionFactory(){
super();
}
public synchronized static SqlSessionFactory getSqlSessionFactory(){
if(null==sqlSessionFactory){
InputStream inputStream=null;
try{
inputStream = MybatisSessionFactory.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
catch (Exception e){
LOG.error("create MybatisSessionFactory read mybatis-config.xml cause Exception",e);
}
if(null!=sqlSessionFactory){
LOG.info("get Mybatis sqlsession sucessed....");
}
else {
LOG.info("get Mybatis sqlsession failed....");
}
}
return sqlSessionFactory;
}
}
使用mybatis 对数据库进行操作:
SqlSession sqlSession = MybatisSessionFactory.getSqlSessionFactory().openSession();
UserRelaInfoMapper userRelaInfoMapper = sqlSession.getMapper(UserRelaInfoMapper .class);
//调用对应的方法
userRelaInfoMapper.xxxx();
//提交事务
sqlSession.commit();
//回滚事务,一般可以捕获异常,在发生Exception的时候,事务进行回滚
sqlSession.rollback();
这里以mysql为示例,写一个flink下mysql的sink示例,可以自己来灵活控制事务的提交:
public class MysqlSinkFunction<IN> extends RichSinkFunction {
private static final Logger LOG = LoggerFactory.getLogger(MysqlSinkFunction.class);
@Override
public void invoke(Object value, Context context) throws Exception{
SqlSession sqlSession = MybatisSessionFactory.getSqlSessionFactory().openSession();
try{
//插入
LOG.info("MysqlSinkFunction start to do insert data...");
xxx.xxx();
//更新
LOG.info("MysqlSinkFunction start to do update data...");
xxx.xxx();
//删除
LOG.info("MysqlSinkFunction start to do delete data...");
xxx.xxx();
sqlSession.commit();
LOG.info("MysqlSinkFunction commit transaction success...");
}
catch (Throwable e){
sqlSession.rollback();
LOG.error("MysqlSinkFunction cause Exception,sqlSession transaction rollback...",e);
}
}
}
相信您如果以前在spring中用过mybatis的话,对上面的这些操作一定不会陌生。由此你也可以发现,在大数据中可以完美的集成mybatis,这样可以发挥mybatis框架对数据库操作的优势,使用起来也非常简单方便。
一旦集成了mybaitis后,在flink中就可以方便的对各种各样的关系型数据库进行操作了。
本文作者张永清,转载请注明出处:flink 流式处理中如何集成mybatis框架
flink 流式处理中如何集成mybatis框架的更多相关文章
- Spring集成MyBatis框架
Java在写数据库查询时,我接触过四种方式: 1.纯Java代码,引用对应的数据库驱动包,自己写连接与释放逻辑(可以用连接池) 这种模式实际上性能是非常不错的,但是使用起来并不是非常方便:一是要手工为 ...
- Idea中Spring整合MyBatis框架中配置文件中对象注入问题解决方案
运行环境:Spring框架整合MaBitis框架 问题叙述: 在Spring配置文件applicationContext-mybatis.xml中配置好mybatis之后 <?xml versi ...
- 微服务学习一:idea中springboot集成mybatis
一直都想学习微服务,这段时间在琢磨这块的内容,个人之前使用eclipse,现在用intellij idea来进行微服务的开发,个人感觉intellij idea比eclipse更简洁更方便,因为int ...
- Apache Flink流式处理
花了四小时,看完Flink的内容,基本了解了原理. 挖个坑,待总结后填一下. 2019-06-02 01:22:57等欧冠决赛中,填坑. 一.概述 storm最大的特点是快,它的实时性非常好(毫秒级延 ...
- Flink流式引擎技术分析--大纲
Flink简介 Flink组件栈 Flink特性 流处理特性 API支持 Libraries支持 整合支持 Flink概念 Stream.Transformation.Operator Paralle ...
- Flink流式计算
Structured Streaming A stream is converted into a dynamic table. A continuous query is evaluated on ...
- 流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- [转载]流式大数据处理的三种框架:Storm,Spark和Samza
许多分布式计算系统都可以实时或接近实时地处理大数据流.本文将对三种Apache框架分别进行简单介绍,然后尝试快速.高度概述其异同. Apache Storm 在Storm中,先要设计一个用于实时计算的 ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(四):集成 MyBatis 框架
引入依赖 Spring Boot对于MyBatis的支持需要引入mybatis-spring-boot-starter的pom文件. <dependency> <groupId> ...
随机推荐
- JSON:JSON对象和JSON数组混排的复杂字符串
在java中的一个好用的JSON工具包:net.sf.json.JSONObject 和 net.sf.json.JSONArray 一 解析JSON对象和JSON数组类型混排的复杂字符串 举个例子: ...
- CSS3、jQuery实现3D翻书动画
使用CSS3 ,jQuery实现点击翻书动画效果,完整效果可在firefox中查看 HTML <div class="desktop"> <div class=& ...
- VoodooPad Mac笔记本
VoodooPad Mac笔记本 VoodooPad是记录您的笔记和想法的地方.想法,图片,列表,密码和妈妈的苹果派食谱.包括您需要跟踪和组织的所有内容,VoodooPad会与您一起成长而不会妨碍您. ...
- 020 - FreeRTOS学习路线总结
零.为什么写? 在H7-tools预售群里,有位朋友提出如何学习FreeRTOS这类的问题,便由此总结下自己的学习路线.最近又打算接触RTT,和FreeRTOS做个对比. 文章分两步来讲,学习路线和学 ...
- The usage of Markdown---杂谈:缩进/换行/分割线/注释/文字颜色
目录 1. 序言 2. 缩进 3. 换行 4. 分割线 5. 注释 6. 改变文字大小和颜色 更新时间:2019.09.14 1. 序言 今天一口气更新了接近10篇博客(虽然只是将我之前基本码好的 ...
- Net Framework,Net Core 和 Net Standard 区别
前几天我在一个群里看到有关这方面的讨论,最后感觉讨论的不是很清晰,有幸的是我们的项目去年就开始迁移NetCore的调研了,我个人多多少少也是有过这方面的研究.下面我将说一下我自己对着三个的认识如果有不 ...
- Android原生PDF功能实现
1.背景 近期,公司希望实现安卓原生端的PDF功能,要求:高效.实用. 经过两天的调研.编码,实现了一个简单Demo,如上图所示. 关于安卓原生端的PDF功能实现,技术点还是很多的,为了咱们安卓开发的 ...
- python基础-数字类型及内置方法
--数字类型及内置方法 整型-int 用途:多用于年龄.电话.QQ号等变量 定义方法 age = 18 # age = int(18) 常用方式:多用于数学计算 # int(x)将x转换成整数,是向下 ...
- MySQL字符集与排序规则总结
字符集与排序规则概念 在数据库当中都有字符集和排序规则的概念, 很多开发人员甚至包括有些DBA都会将这个混淆,当然这个情况也有一些情有可原的原因.一来两者本来就是相辅相成,相互依赖关联: 另外一方 ...
- Java 干货之深入理解Java泛型
一般的类和方法,只能使用具体的类型,要么是基本类型,要么是自定义的类.如果要编写可以应用多中类型的代码,这种刻板的限制对代码得束缚会就会很大. ---<Thinking in Java> ...