kubernetes 监控方案之:heapster+influxdb+grafana(十八)
heapster 已经 deprecated 了:https://github.com/kubernetes/heapster,所以下面的演示主要针对 Kubernetes 1.10 之前的版本,我这里是新版本,所以是收集不到数据的。
一、Heapster 介绍
Heapster 是容器集群监控和性能分析工具,天然的支持 Kubernetes 和 CoreOS。
Kubernetes 有个出名的监控 agent—cAdvisor。在每个 kubernetes Node 上都会运行 cAdvisor,它会收集本机以及容器的监控数据 (cpu,memory,filesystem,network,uptime)。在较新的版本中,K8S 已经将 cAdvisor 功能集成到 kubelet 组件中。每个 Node 节点可以直接进行
web 访问。
Heapster 是一个收集者,Heapster 可以收集 Node 节点上的 cAdvisor 数据,将每个 Node 上的 cAdvisor 的数据进行汇总,还可以按照 kubernetes 的资源类型来集合资源,比如 Pod、Namespace,可以分别获取它们的 CPU、内存、网络和磁盘的 metric。默认的 metric 数据聚合时间间隔是1分钟。还可以把数据导入到第三方工具(如 InfluxDB)。
Kubernetes 原生 dashboard 的监控图表信息来自 heapster。在 Horizontal Pod Autoscaling 中也用到了 Heapster,HPA 将 Heapster 作为 Resource Metrics API,向其获取 metric。
** 架构图 **
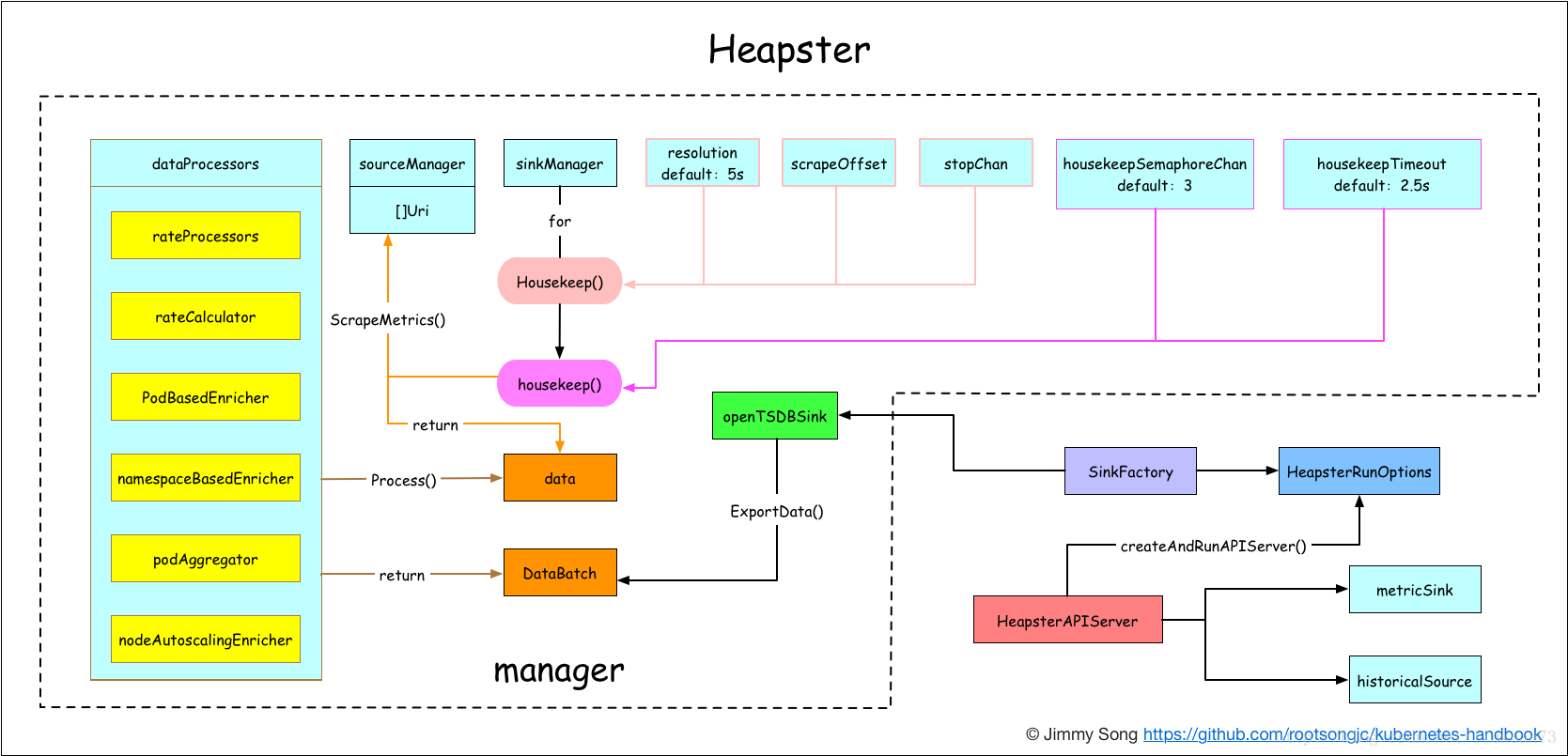
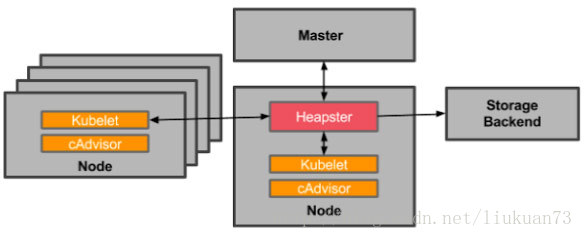
Heapster 首先从 apiserver 获取集群中所有 Node 的信息,然后通过这些 Node 上的 kubelet 获取有用数据,而 kubelet 本身的数据则是从 cAdvisor 得到。所有获取到的数据都被推到 Heapster 配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如InfluxDB + grafana。
二、部署
Heapster 本身是一个 Kubernetes 应用,部署方法很简单,运行如下命令:
[root@master ~]# git clone https://github.com/kubernetes/heapster.git
[root@master ~]# kubectl apply -f heapster/deploy/kube-config/influxdb/
deployment.extensions/monitoring-grafana created
service/monitoring-grafana created
serviceaccount/heapster created
deployment.extensions/heapster created
service/heapster created
deployment.extensions/monitoring-influxdb created
service/monitoring-influxdb created
[root@master ~]# kubectl apply -f heapster/deploy/kube-config/rbac/heapster-rbac.yaml
clusterrolebinding.rbac.authorization.k8s.io/heapster created
因为众所周知的原因,有些镜像我们是下载不下来,只能间接的获取,我们还是在阿里云的仓库里面找一下。
docker pull registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4
docker tag registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4 k8s.gcr.io/heapster-amd64:v1.5.4
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s_grc_io/heapster-amd64:v1.5.4
docker pull registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4
docker tag registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4 k8s.gcr.io/heapster-grafana-amd64:v5.0.4
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s-kernelsky/heapster-grafana-amd64:v5.0.4
docker pull registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2
docker tag registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2 k8s.gcr.io/heapster-influxdb-amd64:v1.5.2
docker image rm registry.cn-hangzhou.aliyuncs.com/k8s-images1/heapster-influxdb-amd64:v1.5.2
Heapster 相关资源如下:
[root@master ~]# kubectl get pod -n kube-system |grep -e heapster -e monitor
heapster-f64999bc-8x7j7 1/1 Running 0 16m
monitoring-grafana-564f579fd4-jsx2r 1/1 Running 0 16m
monitoring-influxdb-8b7d57f5c-ntnxc 1/1 Running 0 16m
[root@master ~]# kubectl get deploy -n kube-system |grep -e heapster -e monitor
heapster 1/1 1 1 16m
monitoring-grafana 1/1 1 1 16m
monitoring-influxdb 1/1 1 1 16m
[root@master ~]# kubectl get svc -n kube-system |grep -e heapster -e monitor
heapster ClusterIP 10.101.170.222 <none> 80/TCP 16m
monitoring-grafana ClusterIP 10.104.60.71 <none> 80/TCP 16m
monitoring-influxdb ClusterIP 10.104.104.41 <none> 8086/TCP 16m
为便与访问,可以通过 kubectl edit 将 Service monitoring-grafana的类型修改为 NodePort。
[root@master ~]# kubectl patch svc monitoring-grafana -p '{"spec":{"type":"NodePort"}}' -n kube-system
service/monitoring-grafana patched
目前我们的 Pod heapster,是采集不到数据的,因为已经被废弃,大家可以通过下面的命令查看到错误信息。
kubectl logs heapster-f64999bc-8x7j7 -n kube-system
三、使用
浏览器打开 Grafana 的 Web UI:http://MASTER_IP:32314/
Heapster 已经预先配置好了 Grafana 的 DataSource 和 Dashboard。
Heapster 预定义的 Dashboard 很直观也很简单。如有必要,可以在 Grafana 中定义自己的 Dashboard 满足特定的业务需求。
kubernetes 监控方案之:heapster+influxdb+grafana(十八)的更多相关文章
- 7、Docker监控方案(cAdvisor+InfluxDB+Grafana)
一.组件介绍 我们采用现在比较流行的cAdvisor+InfluxDB+Grafana组合进行Docker监控. 1.cAdvisor(数据采集) 开源软件cAdvisor(Container Adv ...
- 详解k8s原生的集群监控方案(Heapster+InfluxDB+Grafana) - kubernetes
1.浅析监控方案 heapster是一个监控计算.存储.网络等集群资源的工具,以k8s内置的cAdvisor作为数据源收集集群信息,并汇总出有价值的性能数据(Metrics):cpu.内存.netwo ...
- Kubernetes 监控方案之 Prometheus Operator(十九)
目录 一.Prometheus 介绍 1.1.Prometheus 架构 1.2.Prometheus Operator 架构 二.Helm 安装部署 2.1.Helm 客户端安装 2.2.Tille ...
- kubernetes监控-Heapster+InfluxDB+Grafana(十五)
cAdvisor+InfluxDB+Grafana cAdvisor:是谷歌开源的一个容器监控工具,采集主机上容器相关的性能指标数据.比如CPU.内存.网络.文件系统等. Heapster是谷歌开源的 ...
- kubernetes监控和性能分析工具:heapster+influxdb+grafana
1.部署heapster 下载 heapster 相关 yaml 文件 [root@master dashboard]# wget https://raw.githubusercontent.com/ ...
- 14、Docker监控方案(Prometheus+cAdvisor+Grafana)
上一篇文章我们已经学习了比较流行的cAdvisor+InfluxDB+Grafana组合进行Docker监控.这节课来学习Prometheus+cAdvisor+Grafana组合. cAdvisor ...
- 建立Heapster Influxdb Grafana集群性能监控平台
依赖于kubenets dns服务 图形化展示度量指标的实现需要集成k8s的另外一个Addons组件: Heapster .Heapster原生支持K8s(v1.0.6及以后版本)和 CoreOS , ...
- 【Docker】性能测试监控平台搭建:InfluxDB+Grafana+Jmeter+cAdvisor
前言 在做性能测试时,如果有一个性能测试结果实时展示的页面,可以极大的提高我们对系统性能表现的掌握程度,进而提高我们的测试效率.但是我们每次打开Jmeter都会有几个硕大的字提示别用GUI模式进行负载 ...
- 性能测试监控:Jmeter+Collectd+Influxdb+Grafana
系统性能指标图示例: 采集数据(collectd)-> 存储数据(influxdb) -> 显示数据(grafana) InfluxDB 是 Go 语言开发的一个开源分布式时序数据库,非常 ...
随机推荐
- 摘:J2EE开发环境搭建(1)——安装JDK、Tomcat、Eclipse
J2EE开发环境搭建(1)——安装JDK.Tomcat.Eclipse 1:背景 进公司用SSH(Struts,spring和hibernate)开发已经有两个月了,但由于一 直要么只负责表示层的开发 ...
- Python 推送RabbitMQ
username = 'xxxxxxxx' pwd = 'xxxxxxxx' user_pwd = pika.PlainCredentials(username, pwd) s_conn = pika ...
- HBase数据结构
1 RowKey 与nosql数据库们一样,RowKey是用来检索记录的主键.访问HBASE table中的行,只有三种方式: 1.通过单个RowKey访问 2.通过RowKey的range(正则) ...
- [USACO 09FEB]Bullcow
Description 题库链接 有 \(n\) 头牛,每头牛可以为 \(\text{A}\) 牛也可以为 \(\text{B}\) 牛.现在给这些牛排队,要求相邻两头 \(\text{A}\) 牛之 ...
- 基于虚拟机+Ubuntu1604的ROS-kinetic配置流程
简单记录一下配置的过程 先换源,以阿里源为例 备份原有源 sudo cp /etc/apt/sources.list /etc/apt/sources_init.list 编辑源文件 sudo ged ...
- go语言的坑
go语言在for循环中遍历的临时变量地址是一样的 func main() { //SetLogConfToEtcd() for i := 0; i < 5; i++ { a := i fmt.P ...
- SpringBoot整合JDBC模板
目录 Grade实体类 public class Grade { private Integer gradeId; private String gradeName; public Grade(){ ...
- Codeforces Round #493 (Div. 2) 【A,B,C】
简单思维题 #include<bits/stdc++.h> using namespace std; #define int long long #define inf 0x3f3f3f3 ...
- 关于System.Reflection.TargetInvocationException 异常
什么是TargetInvocationException 由通过反射调用的方法引发的异常. 继承 Object Exception ApplicationException TargetInvocat ...
- lyft amundsen简单试用
昨天有说过amundsen 官方为我们提供了dockerc-compose 运行的参考配置,以下是一个来自官方的 quick start clone amundsen 代码 amundsen 使用了g ...