9、共享变量(Broadcast Variable和Accumulator)
一、共享变量
1、共享变量工作原理
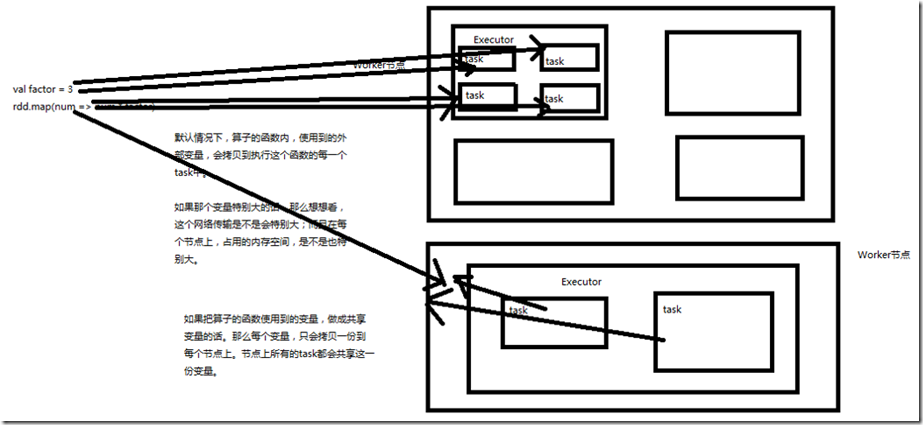
Spark一个非常重要的特性就是共享变量。 默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想
要共享某个变量,那么这种方式是做不到的。 Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝
一份,更大的用处是优化性能,减少网络传输以及内存消耗。Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。
2、Broadcast Variable
Spark提供的Broadcast Variable,是只读的。并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本。因此其最大作用,就是减少变量到各个节点的网络传
输消耗,以及在各个节点上的内存消耗。此外,spark自己内部也使用了高效的广播算法来减少网络消耗。 可以通过调用SparkContext的broadcast()方法,来针对某个变量创建广播变量。然后在算子的函数内,使用到广播变量时,每个节点只会拷贝一份副本了。每个节点可以使
用广播变量的value()方法获取值。记住,广播变量,是只读的。 ------java实现------ package cn.spark.study.core; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast; /**
* 广播变量
* @author bcqf
*
*/ public class BroadcastVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("BroadcastVariable").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); // 在java中,创建共享变量,就是调用SparkContext的broadcast()方法
// 获取的返回结果是Broadcast<T>类型
final int factor = 3;
final Broadcast<Integer> factorBroadcast = sc.broadcast(factor); List<Integer> numberList = Arrays.asList(1,2,3,4,5); JavaRDD<Integer> numbers = sc.parallelize(numberList); //让集合中的每个数字,都乘以外部定义的那个factor
JavaRDD<Integer> multipleNumbers = numbers.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception {
// 使用共享变量时,调用其value()方法,即可获取其内部封装的值
int factor = factorBroadcast.value();
return v1 * factor;
}
}); multipleNumbers.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); sc.close();
}
} //结果
3
6
9
12
15
--------scala实现-------- package cn.spark.study.core import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object BroadcastVariable {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("BroadcastVariable").setMaster("local")
val sc = new SparkContext(conf) val factor = 3;
val factorBroadcast = sc.broadcast(factor) val numberArray = Array(1,2,3,4,5)
val numbers = sc.parallelize(numberArray, 1) val multipleNumbers = numbers.map { num => num * factorBroadcast.value}
multipleNumbers.foreach { num => println(num)}
}
}
3、Accumulator
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。
但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。 ------java实现------- package cn.spark.study.core; import java.util.Arrays;
import java.util.List; import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction; public class AccumulatorVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Accumulator").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf); // 创建Accumulator变量
// 需要调用SparkContext的accumulator()方法
final Accumulator<Integer> sum = sc.accumulator(0); List<Integer> numberList = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> numbers = sc.parallelize(numberList); numbers.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
// 然后在函数内部,就可以对Accumulator变量,调用add()方法,累加值
sum.add(t);
}
}); // 在driver程序中,可以调用Accumulator的value()方法,获取其值
System.out.println(sum.value()); sc.close();
} } //结果
15 --------scala实现--------- package cn.spark.study.core import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object AccumulatorVariable {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AccumulatorVariable").setMaster("local")
val sc = new SparkContext(conf) val sum = sc.accumulator(0) val numberArray = Array(1,2,3,4,5)
val numbers = sc.parallelize(numberArray, 1)
numbers.foreach {num => sum += num } println(sum)
}
}
9、共享变量(Broadcast Variable和Accumulator)的更多相关文章
- 08、共享变量(Broadcast Variable和Accumulator)
共享变量工作原理 Spark一个非常重要的特性就是共享变量. 默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中.此时每个task只能操作自己的那份 ...
- Spark2.x(六十二):(Spark2.4)共享变量 - Broadcast原理分析
之前对Broadcast有分析,但是不够深入<Spark2.3(四十三):Spark Broadcast总结>,本章对其实现过程以及原理进行分析. 带着以下几个问题去写本篇文章: 1)dr ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- Spark踩坑记——共享变量
[TOC] 前言 Spark踩坑记--初试 Spark踩坑记--数据库(Hbase+Mysql) Spark踩坑记--Spark Streaming+kafka应用及调优 在前面总结的几篇spark踩 ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- Spark踩坑记:共享变量
收录待用,修改转载已取得腾讯云授权 前言 前面总结的几篇spark踩坑博文中,我总结了自己在使用spark过程当中踩过的一些坑和经验.我们知道Spark是多机器集群部署的,分为Driver/Maste ...
- 常用Actoin算子 与 内存管理 、共享变量、内存机制
一.常用Actoin算子 (reduce .collect .count .take .saveAsTextFile . countByKey .foreach ) collect:从集群中将所有的计 ...
随机推荐
- java之结合代码理解synchronized关键字
为了保证数据的一致性即实现线程的安全性,java虚拟机提供了同步和锁机制.synchronized关键字是最基本的互斥同步手段.除此之外,还可以使用java.util.concurrent包中的重入锁 ...
- MVC-09安全
部分8:添加安全. MVC应用程序安全性 Models文件夹包含表示应用程序模型的类. Visual Web Developer自动创建AccountModels.cs文件,该文件包含用于应用程序认证 ...
- 子进程的LD_PRELOAD
一个指定LD_PRELOAD的进程创建的子进程是否受LD_PRELOAD的影响? 1. fork()后在子进程中执行函数. main.c #include <unistd.h> #incl ...
- 【开发笔记】- Linux命令大全
系统信息 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS ...
- 【转载】C#中string类使用Substring方法截取字符串
在C#的字符串操作过程中,截取字符串是一种常见的字符串操作,可使用string类的Substring方法来完成字符串的截取操作,该方法支持设定截取的开始位置以及截取的字符串长度等参数,Substrin ...
- 为什么Java中一个char能存下一个汉字
在Java中,char的长度是2字节,即16位,2的16次方是65536. 1.如果采用utf-8编码,一个汉字占3个字节,char为什么还能存下一个汉字呢? 参考:https://developer ...
- 74.js---移动端文章的瀑布流的实现。
移动端文章的瀑布流的实现. 1.首先在前端html页面已经通过PHP代码循环完全数据. 2.然后在js先全部隐藏,通过判断滑动到底部,每次加载一部分数据,直到数据全部显示完全. js代码: // ...
- js两个变量互换值
js两个变量交换值 这个问题看似很基础,但是有很多的实现方式,你知道的有多少呢,网上也有很多的方法,下面就来总结一下 中间变量(临时变量) 临时变量其实很好理解,通过一个中间变量进行交换值 var s ...
- 造成thrift 编译构建项目失败的原因之一:thrift环境变量没设置
由于重装了系统和IDEA工具,打开原项目时使用install 构建使用thrift 协议的项目时失败.下面是说说我遇到的问题 看下图,就是构建时控制台输出的日志,因为是乱码,当时没重视,就先去检查po ...
- 02- web-mini框架添加路由、MySQL(二)
本篇在上篇的基础上为其增设路由功能,同时将上篇中的数据库中数据备份添加进去. 一.装饰器 在之前有介绍过为一个函数不改变源代码不改变原函数的调用方式下为其增设附加功能,需要用到装饰器,而在该上篇的we ...