Hadoop:eclipse配置hadoop-eclipse-plugin(版本hadoop2.7.3)
配置hadoop-eclipse-plugin(版本hadoop2.7.3):
1:首先下载我们需要的 hadoop-eclipse-plugin-2.7.3.jar,winutils.exe 和 hadoop.dll
链接地址:https://pan.baidu.com/s/1nuCoe0L#list/path=%2F
2:解压hadoop软件,并且安装到D盘的一个英文路径
3:把hadoop.dll和winutile.exe放到hadoop的bin文件夹里
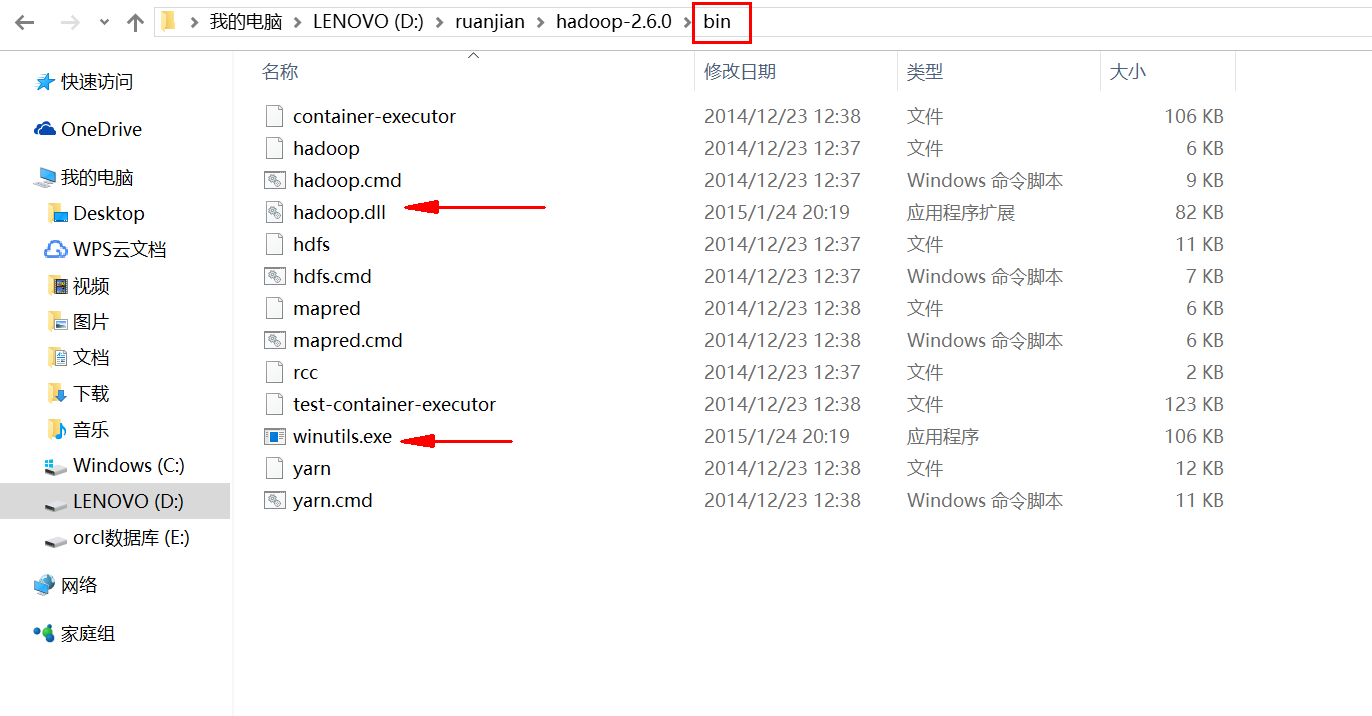
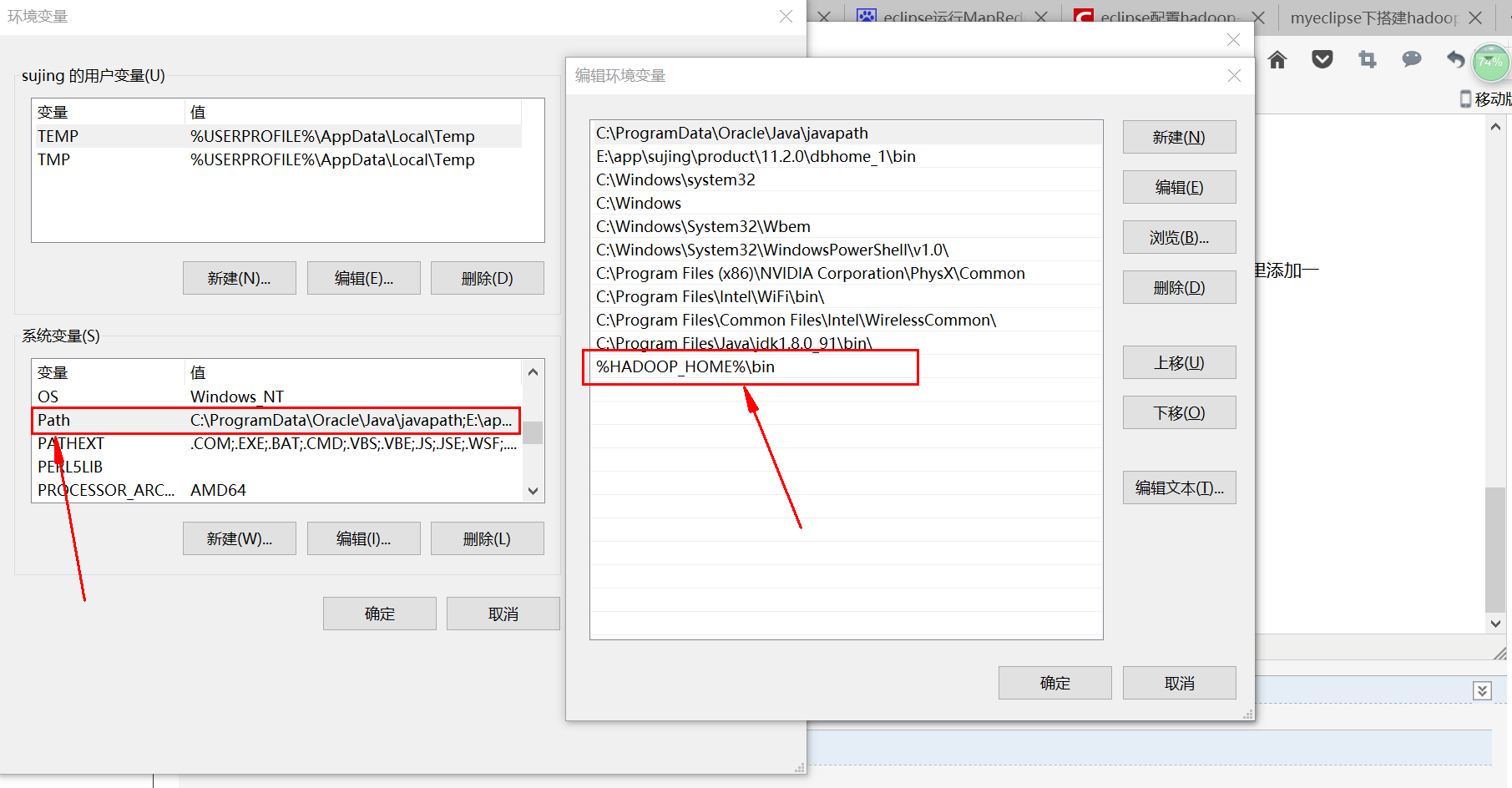
4:右击我的电脑-->属性-->高级系统设置里面要配置三个属性:
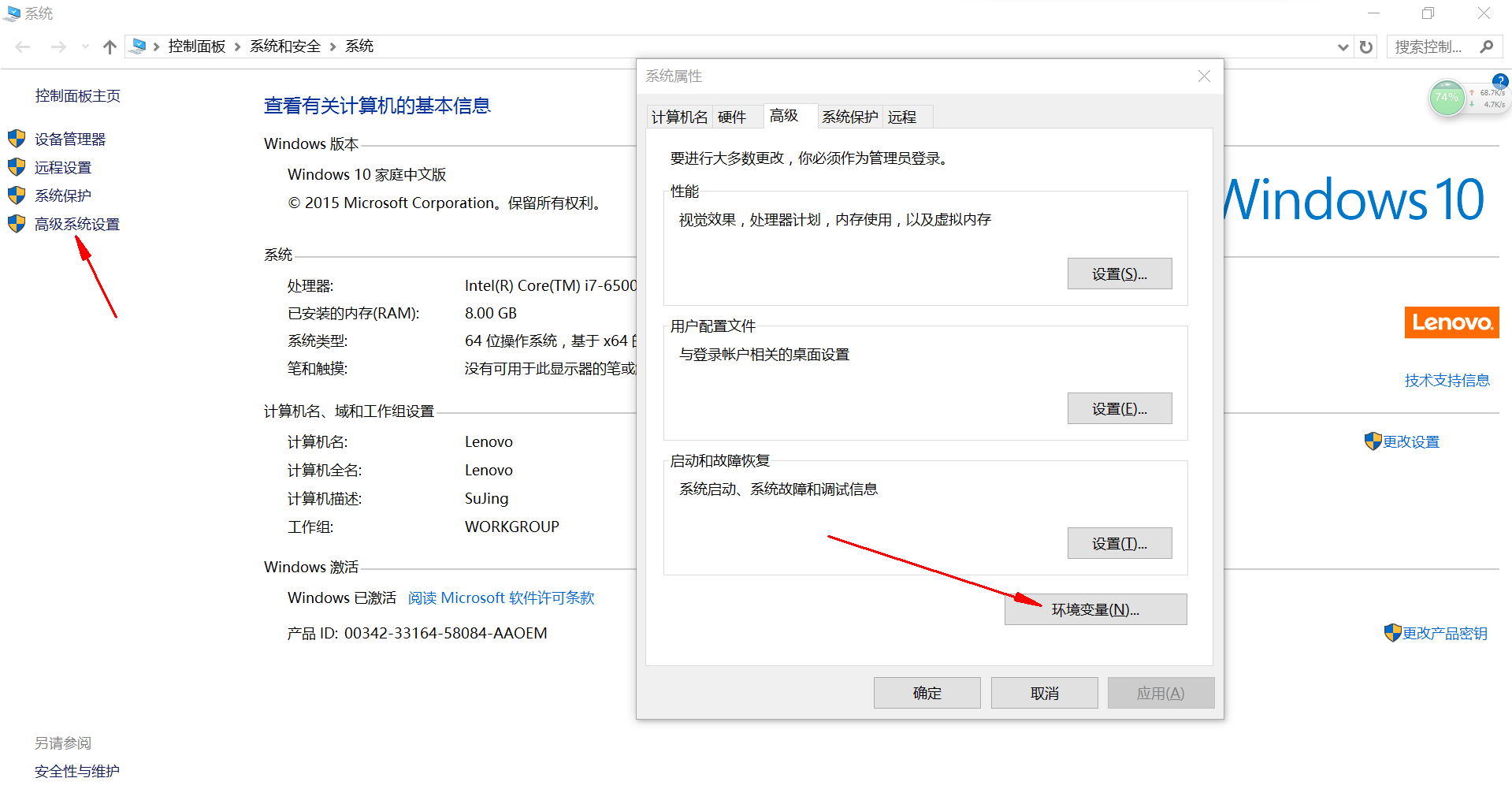
(1)变量名:HADOOP_HOME 变量值:hadoop解压后的路径
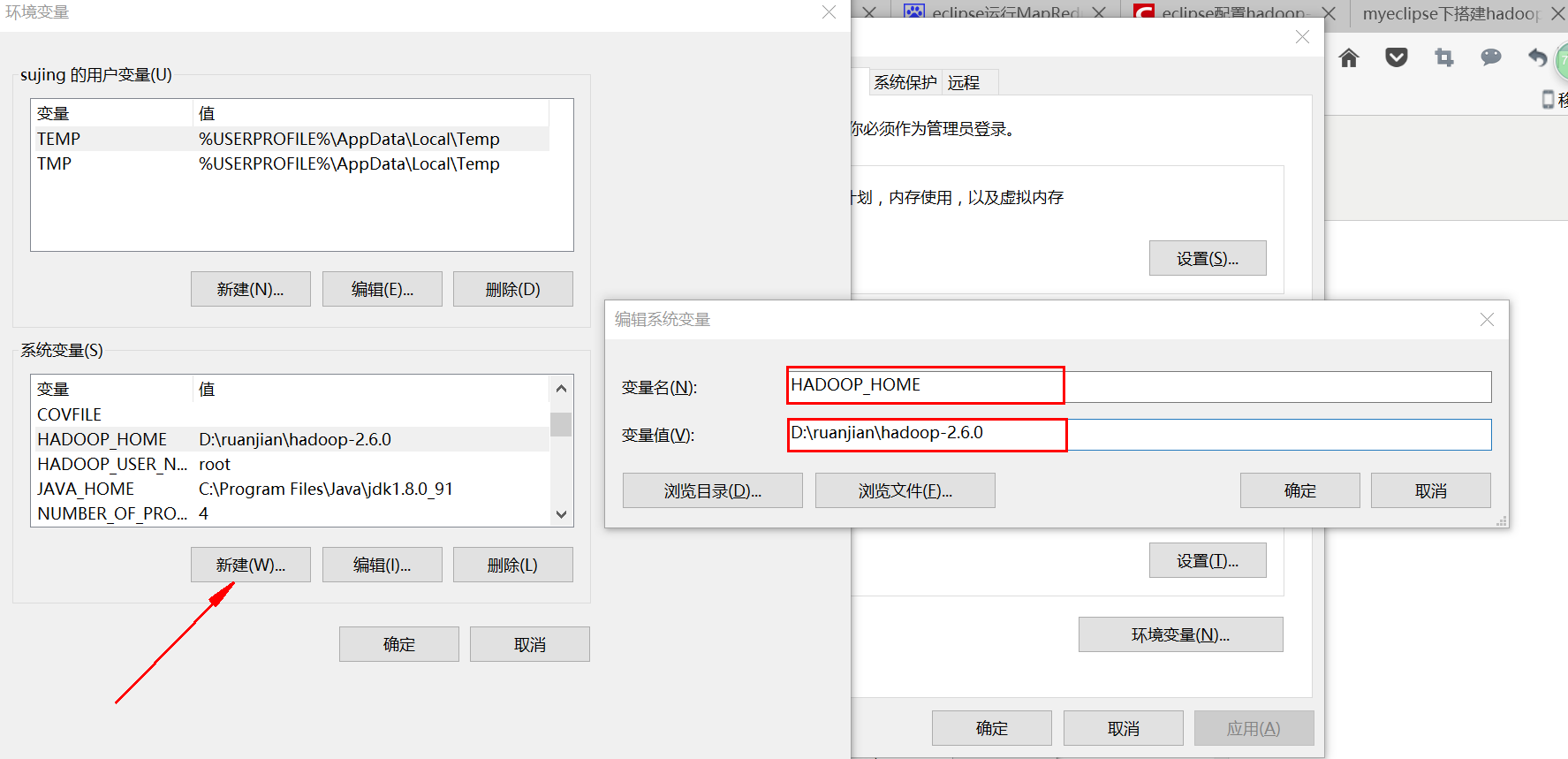
(2)变量名:HADOOP_USER_NAME 变量值:root
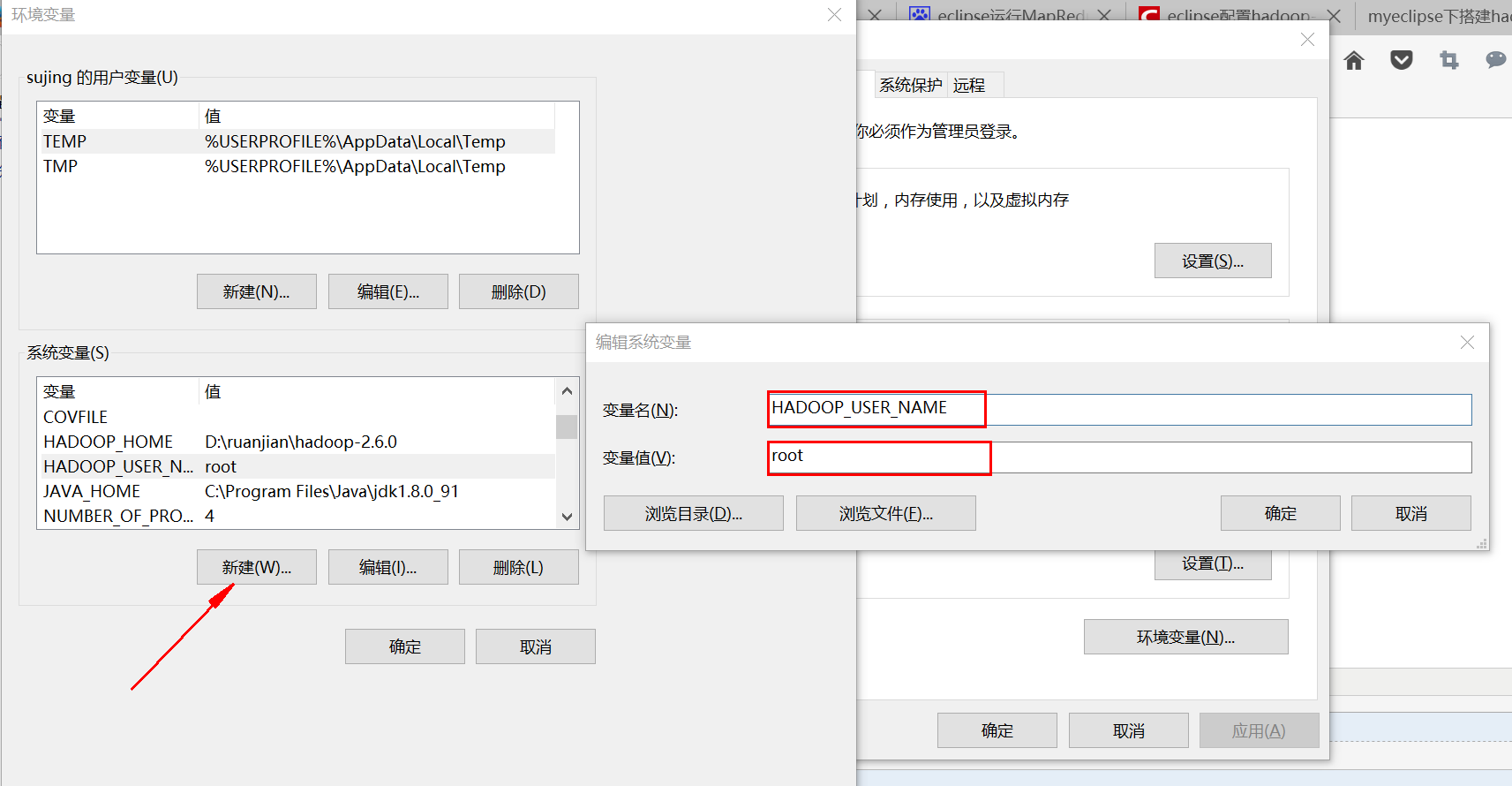
(3)path属性里添加一个:%HADOOP_HOME%\bin
5:把jar包倒在eclipse安装路径的plugins的文件夹里,然后重启eclipse

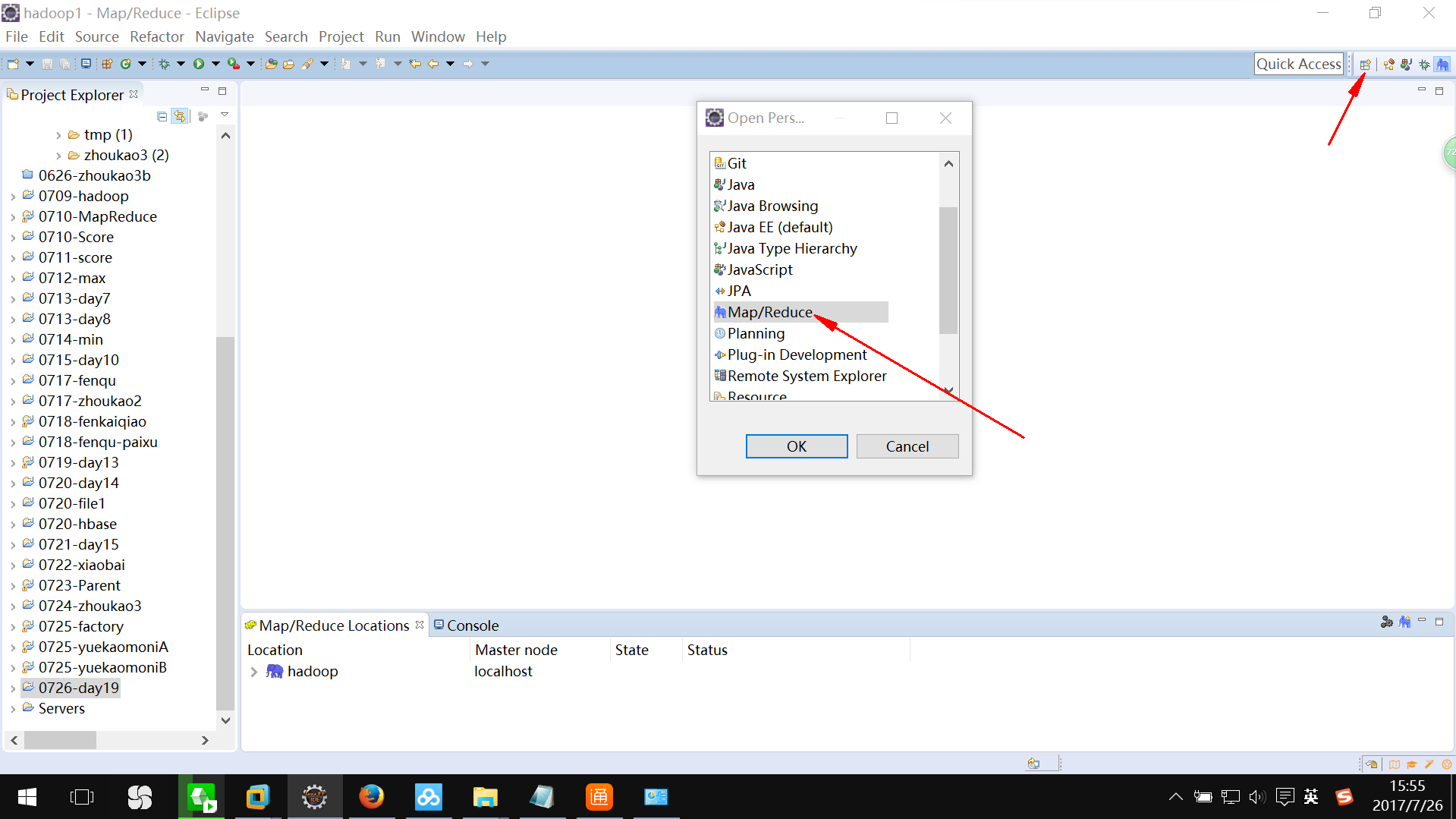
6:打开eclipse的右上角有个田字格,选择Map/Reduce
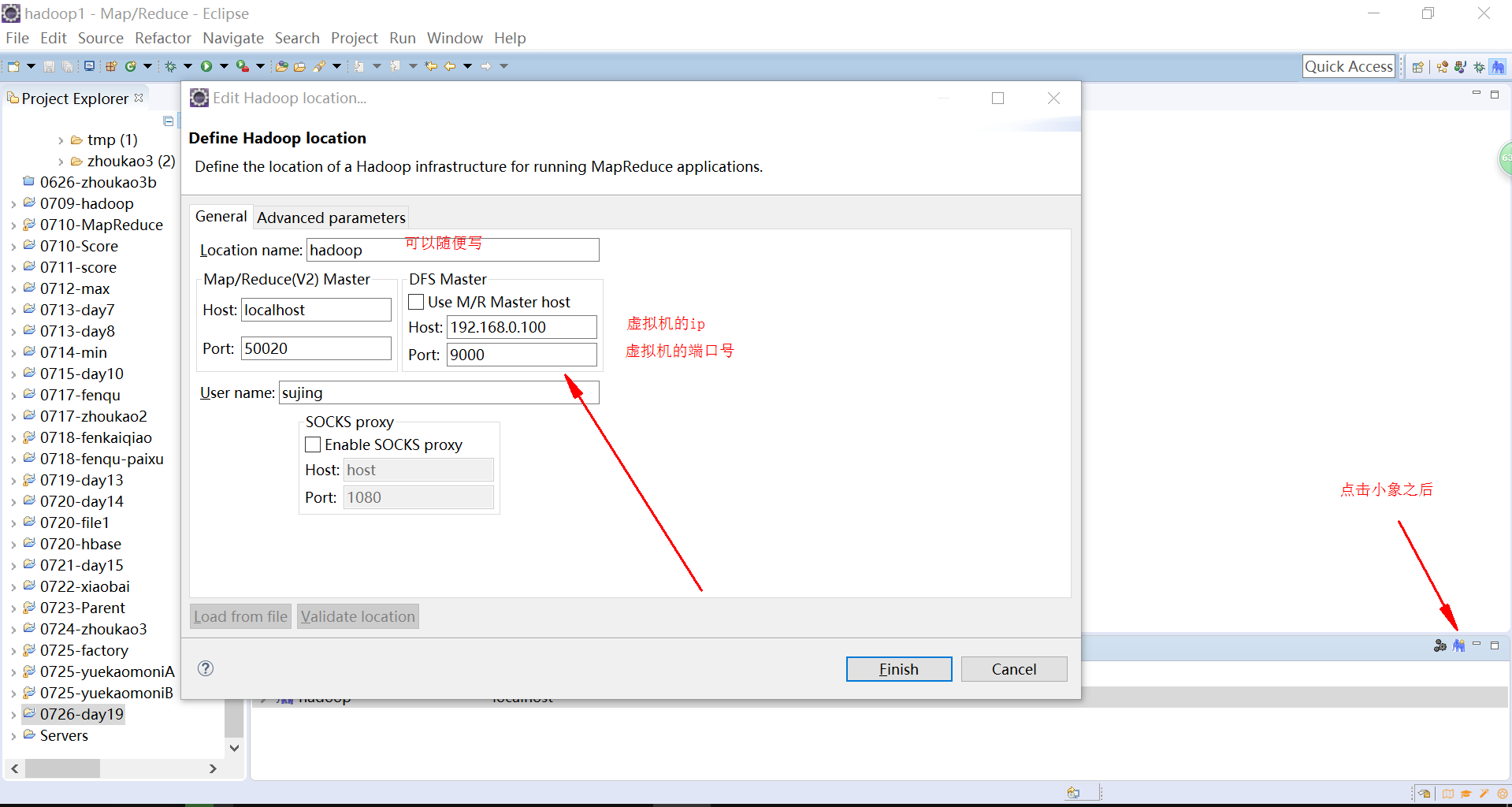
7:点击下方的小象
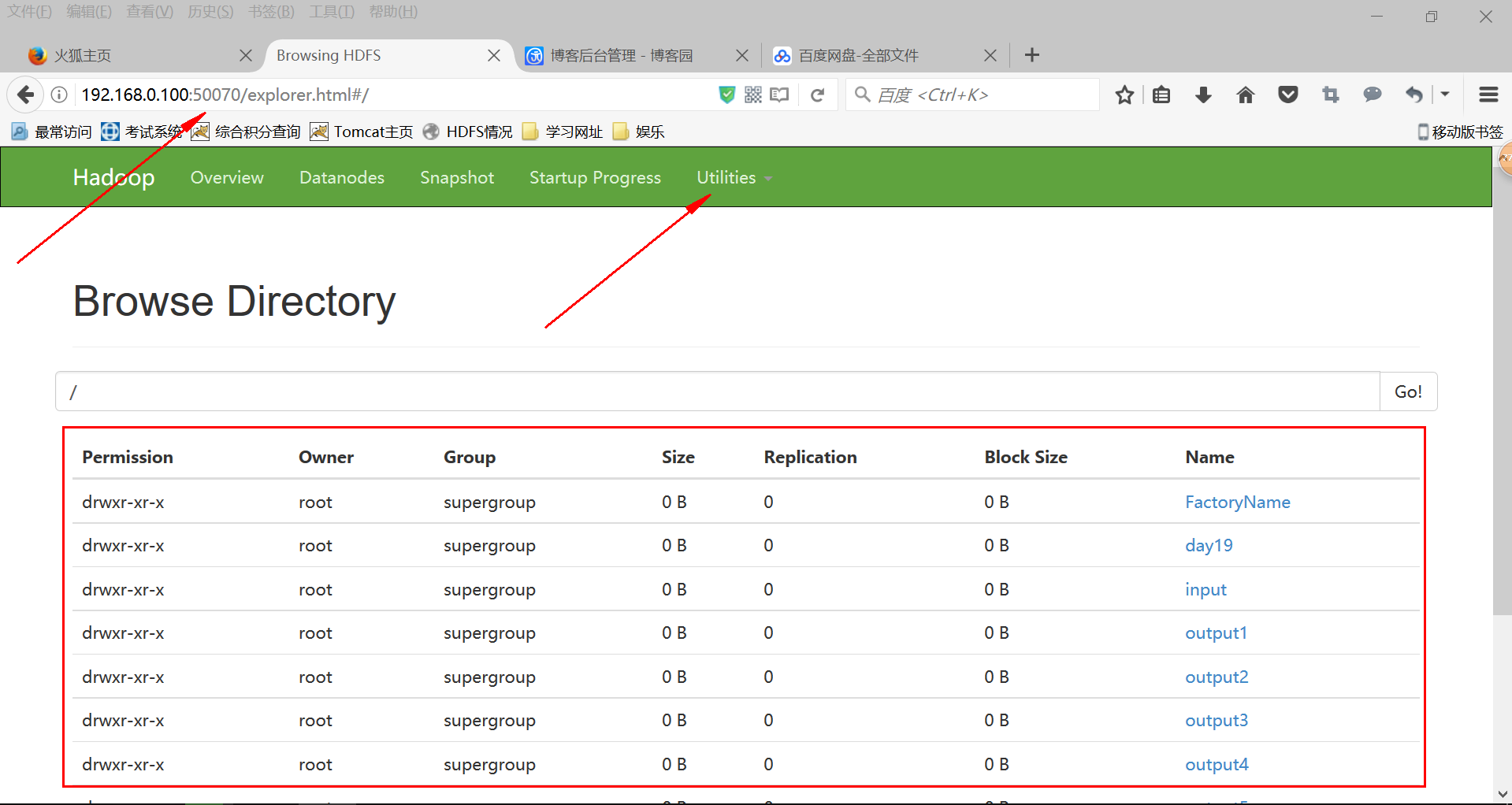
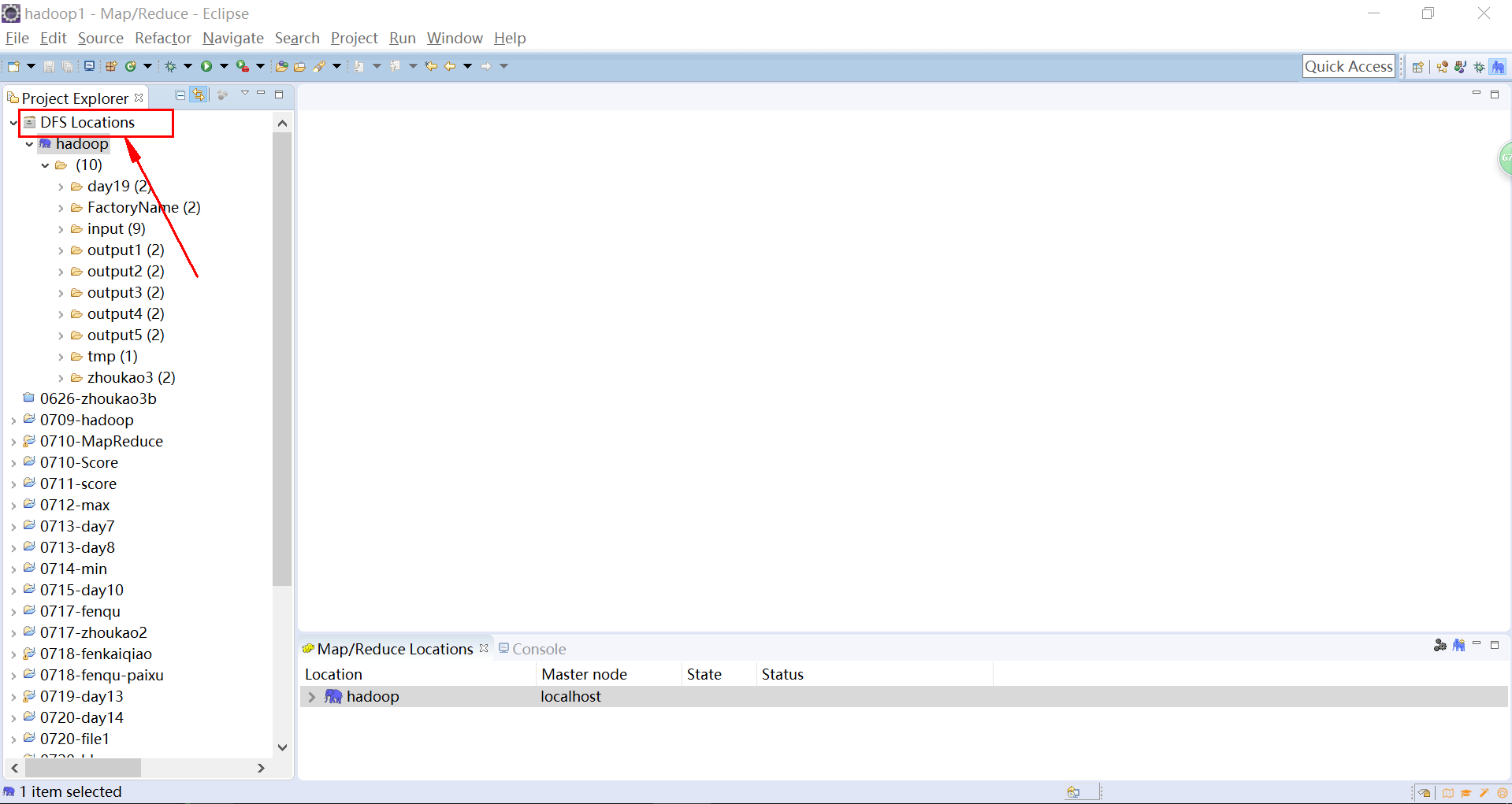
8:然后启动虚拟机的HDFS,最后在浏览器里查看的那些文件都能在eclipse的左边的DFS Locations里展示出来啦~
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击下方的【好文要顶】按钮【精神支持】,因为这两种支持都是使我继续写作、分享的最大动力!
Hadoop:eclipse配置hadoop-eclipse-plugin(版本hadoop2.7.3)的更多相关文章
- eclipse配置hadoop插件
1. 版本信息 eclipse windows 64 bit hadoop 2.5.2 64 bit hadoop eclipse-plug 2.5.2 2. 下载hadoop-2.5.2.t ...
- Eclipse配置Hadoop开发环境
Step 1:选择Hadoop版本对应的Eclipse插件jar包(可自行编译),我的Hadoop版本是hadoop-0.20.2,对应的插件应该是:hadoop-0.20.2-eclipse-plu ...
- eclipse配置hadoop location的端口号
在eclipse下配置hadoop location的时候 hadoop端口号应该与conf文件夹下的core-site.xml以及mapred-site.xml保持一致 前者对应dfs master ...
- eclipse配置hadoop的错误
配置好eclipse,在执行run on hadoop的时候,提示11/03/29 16:47:59 WARN conf.Configuration: DEPRECATED: hadoop-site. ...
- Eclipse安装Hadoop插件配置Hadoop开发环境
一.编译Hadoop插件 首先需要编译Hadoop 插件:hadoop-eclipse-plugin-2.6.0.jar,然后才可以安装使用. 第三方的编译教程:https://github.com/ ...
- Windows下Eclipse连接hadoop
2015-3-27 参考: http://www.cnblogs.com/baixl/p/4154429.html http://blog.csdn.net/u010911997/article/de ...
- 在 Ubuntu 上搭建 Hadoop 分布式集群 Eclipse 开发环境
一直在忙Android FrameWork,终于闲了一点,利用空余时间研究了一下Hadoop,并且在自己和同事的电脑上搭建了分布式集群,现在更新一下blog,分享自己的成果. 一 .环境 1.操作系统 ...
- Eclipse配置SpringBoot
从这一博客开始学习SpringBoot,今天学习Eclipse配置SpringBoot.Eclipse导入SpringBoot有两种方式,一种是在线一个是离线方式. 一.在线安装 点击Eclipse中 ...
- Hadoop安装配置
1.集群部署介绍 1.1 Hadoop简介 Hadoop是Apache软件基金会旗下的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesy ...
随机推荐
- 【转】Windows Dump文件获取
dump文件是进程的内存镜像.可以把程序的执行状态,即当时程序内存空间数据通过调试器保存到dump文件中. 1.利用WinDbg里的adplus来获取dump文件 Adplus.vbs 是一个Visu ...
- boost诊断工具BOOST_ASSERT、BOOST_VERIFY、BOOST_STATIC_ASSERT
boost.assert提供的主要工具是BOOST_ASSERT宏,类似于C语言的assert,提供运行时的断言,但功能有所增强; 默认情况下,BOOST_ASSERT宏等同于assert宏: # d ...
- (转)SPDY
SPDY:Google开发的基于传输控制协议(TCP)的应用层协议,目前已经被用于Google Chrome浏览器中来访问Google的SSL加密服务.SPDY并不是一种用于替代HTTP的协议,而是对 ...
- phpmail发送邮件
---恢复内容开始--- 首先.需要phpmailer的包. 地址:https://github.com/Synchro/PHPMailer 解开压缩包,将class.phpmailer.php,cl ...
- Unicode 和 UTF-8 是什么关系?
2015-10-14 10:08 评论: 9 收藏: 4 转载自: http://huoding.com/2015/10/13/472作者: 火丁笔记本文地址:https://linux.cn/ ...
- 转!!Java的三种代理模式
转自 http://www.cnblogs.com/cenyu/p/6289209.html 1.代理模式 代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象访问目标对象 ...
- smart git使用+单人开发一般流程
单人开发一般流程 clone checkout develop start gitflow start feature 写代码... 选中文件stage(相当于add) commit push fea ...
- git 从远程仓库指定分支clone代码到本地
不指定分支 git clone + clone 地址 # 例如 git clone https://amc-msra.visualstudio.com/xxx/_xx/xxxxxx 指定分支 git ...
- Python列表切片详解([][:][::])
Python切片是list的一项基本的功能,最近看到了一个程序,里面有这样一句类似的代码: a = list[::10] 1 不太明白两个冒号的意思就上网百度,发现大多数人写的博客中都没有提到这一个用 ...
- django--admin模型层
django amdin是django提供的一个后台管理页面,改管理页面提供完善的html和css,使得你在通过Model创建完数据库表之后,就可以对数据进行增删改查,而使用django admin ...