Python 爬虫之request+beautifulsoup+mysql
一、什么是爬虫?
它是指向网站发起请求,获取资源后分析并提取有用数据的程序;
爬虫的步骤:

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)文件
二、本次选择爬虫的数据来源于链家,因为本人打算搬家,想观察一下近期的链家租房数据情况,所以就直接爬取了链家数据,相关的代码如下:
from bs4 import BeautifulSoup as bs
from requests.exceptions import RequestException
import requests
import re
from DBUtils import DBUtils
def main(response): #web页面数据提取与入库操作
html = bs(response.text, 'lxml')
for data in html.find_all(name='div',attrs={"class":"content__list--item--main"}):
try:
print(data)
Community_name = data.find(name="a", target="_blank").get_text(strip=True)
name=str(Community_name).split(" ")[0]
sizes=str(Community_name).split(" ")[1]
forward=str(Community_name).split(" ")[2]
flood = data.find(name="span",class_="hide").get_text(strip=True)
flood=str(flood).replace(" ","").replace("/","")
sqrt= re.compile("\d\d+㎡")
area=str(data.find(text=sqrt)).replace(" ","")
maintance=data.find(name="span",class_="content__list--item--time oneline").get_text(strip=True)
maintance=str(maintance)
price=data.find(name="span",class_="content__list--item-price").get_text(strip=True)
price=str(price)
print(name,sizes,forward,flood,maintance,price)
insertsql = "INSERT INTO test_log.`information`(Community_name,size,forward,area,flood,maintance,price) VALUES "('"+name+"','"+sizes+"','"+forward+"','"+area+"','"+flood+"','"+maintance+"','"+price+"');"
insert_sql(insertsql)
except:
print("have an error!!!")
def insert_sql(sql): #数据入库操作
dbconn=DBUtils("test6")
dbconn.dbExcute(sql)
def get_one_page(urls): #获取web页面数据
try:
headers = {"Host": "bj.lianjia.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Sec-Fetch-Site": "none",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-User": "?1",
"Sec-Fetch-Dest": "document",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": "lianjia_uuid=fa1c2e0b-792f-4a41-b48e-78531bf89136; _smt_uid=5cfdde9d.cbae95b; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216b3fad98fc1d1-088a8824f73cc4-e353165-2710825-16b3fad98fd354%22%2C%22%24device_id%22%3A%2216b3fad98fc1d1-088a8824f73cc4-e353165-2710825-16b3fad98fd354%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%7D; _ga=GA1.2.1891741852.1560141471; UM_distinctid=17167f490cb566-06c7739db4a69e-4313f6b-100200-17167f490cca1e; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1588171341; lianjia_token=2.003c978d834648dbbc2d3aa4b226145cd7; select_city=110000; lianjia_ssid=fc20dfa1-6afb-4407-9552-2c4e7aeb73ce; CNZZDATA1253477573=1893541433-1588166864-https%253A%252F%252Fwww.baidu.com%252F%7C1591157903; CNZZDATA1254525948=1166058117-1588166331-https%253A%252F%252Fwww.baidu.com%252F%7C1591154084; CNZZDATA1255633284=1721522838-1588166351-https%253A%252F%252Fwww.baidu.com%252F%7C1591158264; CNZZDATA1255604082=135728258-1588168974-https%253A%252F%252Fwww.baidu.com%252F%7C1591153053; _jzqa=1.2934504416856578000.1560141469.1588171337.1591158227.3; _jzqc=1; _jzqckmp=1; _jzqy=1.1588171337.1591158227.1.jzqsr=baidu.-; _qzjc=1; _gid=GA1.2.1223269239.1591158230; _qzja=1.1313673973.1560141469311.1588171337488.1591158227148.1591158227148.1591158233268.0.0.0.7.3; _qzjto=2.1.0; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMThmMWQwZTY0MGNiNTliNTI5OTNlNGYxZWY0ZjRmMmM3ODVhMTU3ODNhNjMwODhlZjlhMGM2MTJlMDFiY2JiN2I4OTBkODA0M2Q0YTM0YzIyMWE0YzIwOTBkODczNTQwNzM0NTc1NjBlM2EyYTc3NmYwOWQ3OWQ4OWJjM2UwYzAwY2RjMTk3MTMwNzYwZDRkZTc2ODY0OTY0NTA5YmIxOWIzZWQyMWUzZDE3ZjhmOGJmMGNmOGYyMTMxZTI1MzIxMGI4NzhjNjYwOGUyNjc3ZTgxZjA2YzUzYzE4ZjJmODhmMTA1ZGVhOTMyZTRlOTcxNmNiNzllMWViMThmNjNkZTJiMTcyN2E0YzlkODMwZWIzNmVhZTQ4ZWExY2QwNjZmZWEzNjcxMjBmYWRmYjgxMDY1ZDlkYTFhMDZiOGIwMjI2NTg1ZGU4NTQyODBjODFmYTUyYzI0NDg5MjRlNWI0N1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCI2Yzk3M2U5M1wifSIsInIiOiJodHRwczovL2JqLmxpYW5qaWEuY29tL2RpdGllenVmYW5nL2xpNDY0NjExNzkvcnQyMDA2MDAwMDAwMDFsMSIsIm9zIjoid2ViIiwidiI6IjAuMSJ9"}
response = requests.get(url=urls, headers=headers)
main(response)
except RequestException:
return None
if __name__=="__main__":
for i in range(64): #遍历翻页
if(i==0):
urls = "https://bj.lianjia.com/ditiezufang/li46461179/rt200600000001l1/"
get_one_page(urls)
else:
urls = "https://bj.lianjia.com/ditiezufang/li46461179/rt200600000001l1/".replace("rt","pg"+str(i))
get_one_page(urls)
说明:本代码中使用了《Python之mysql实战》的那篇文章,请注意结合着一起来看。
三、以下是获取到的数据入库后的结果图
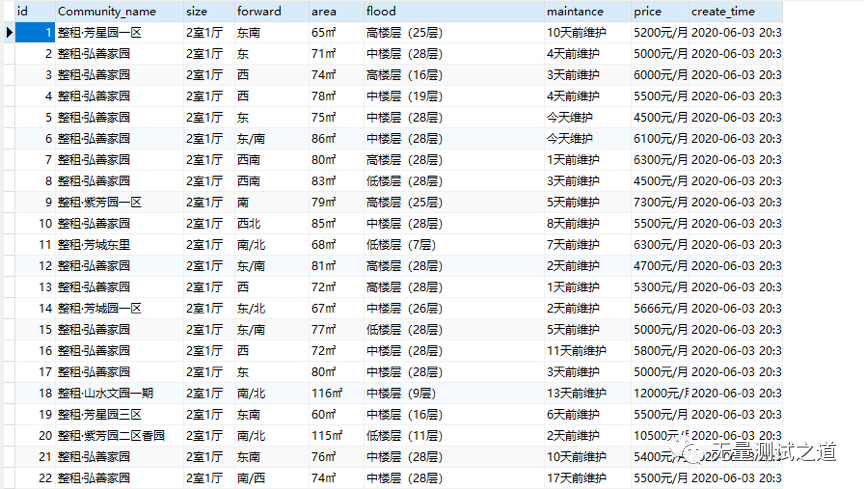
结论:爬虫是获取数据的重要方式之一,我们需要掌握多种方式去获取数据。机器学习是基于数据的学习,我们需要为机器学习做好数据的准备,大家一起加油哟~
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,一起共同成长吧。
Python 爬虫之request+beautifulsoup+mysql的更多相关文章
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- python爬虫之request and BeautifulSoup
1.爬虫的本质是什么? 模仿浏览器的行为,爬取网页信息. 2.requests 1.get请求 无参数实例 import requests ret = requests.get('https://gi ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- Python爬虫之request +re
什么是爬虫? 它是指向网站发起请求,获取资源后分析并提取有用数据的程序: 爬虫的步骤: 1.发起请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头.请求体等 ...
- Python爬虫利器:BeautifulSoup库
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. BeautifulSoup ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- Python爬虫基础之BeautifulSoup
一.BeautifulSoup的基本使用 from bs4 import BeautifulSoup from bs4 import SoupStrainer import re html_doc = ...
- python 爬虫系列01-连接mysql
爬虫学习中......................................... import pymysql conn = pymysql.connect(host=',database ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
随机推荐
- 如何搭建一个WEB服务器项目(六)—— 上传图片至服务器
上传图片(用户头像)至服务器 观前提示:本系列文章有关服务器以及后端程序这些概念,我写的全是自己的理解,并不一定正确,希望不要误人子弟.欢迎各位大佬来评论区提出问题或者是指出错误,分享宝贵经验.先谢谢 ...
- java 多线程详细笔记(原理理解到全部使用)
鸽了好久以后终于又更新了,看同学去实习都是先学源码然后修改之类,才发觉只是知道语法怎么用还远远不够,必须要深入理解以后不管是学习还是工作,才能举一反三,快速掌握. 目录 基础知识 进程与线程 线程原子 ...
- 类linux 系统上端口被占用
好几次遇到这问题,明明Ctrl+C退出了node,但是下次启动的时候总是会报错: listen EADDRINUSE :::80 之类的. 这时候可能是被占用,也可能是上次进程没有真的退出. ps - ...
- node的querystring
querystring.stringify({name:''scott",course:['jade','java'],from=''}); => 'name=scott&co ...
- Java Thread中,run方法和start方法的区别
两种方法的区别: 1.start方法 用 start方法来启动线程,是真正实现了多线程, 通过调用Thread类的start()方法来启动一个线程,这时此线程处于就绪(可运行)状态,并没有运行,一旦 ...
- 根据name获取控件
javascript: document.getElementsByName("name")[index]; jquery: $("tr[name='name']&quo ...
- ExtJS定时和JS定时
ExtJS定时 //定时刷新待办事宜状态 var task={ run:function(){ //执行的方法或方法体 }, interval:5*60*1000 //5分钟 } //定时启动 Ext ...
- Magicodes.IE 2.2发布
Magicodes.IE 导入导出通用库,支持Dto导入导出以及动态导出,支持Excel.Word.Pdf.Csv和Html.已加入NCC开源组织. Magicodes.IE 2.0发布 Magico ...
- 【JavaScript数据结构系列】06-双向链表DoublyLinkedList
[JavaScript数据结构系列]06-双向链表DoublyLinkedList 码路工人 CoderMonkey 转载请注明作者与出处 1. 认识双向链表 不同于普通链表/单向链表,双向链表最突出 ...
- [工具-003]如何从ipa中提取info.plist并提取相应信息
最近公司的产品要进行一次批量的升级,产品中的一些配置存放在info.plist,为了保证产品的信息无误,我们必须要对产品的发布信息进行验证.例如:广告ID,umeng,talkingdata等等.那么 ...