leetcode之820. 单词的压缩编码 | python极简实现字典树
题目
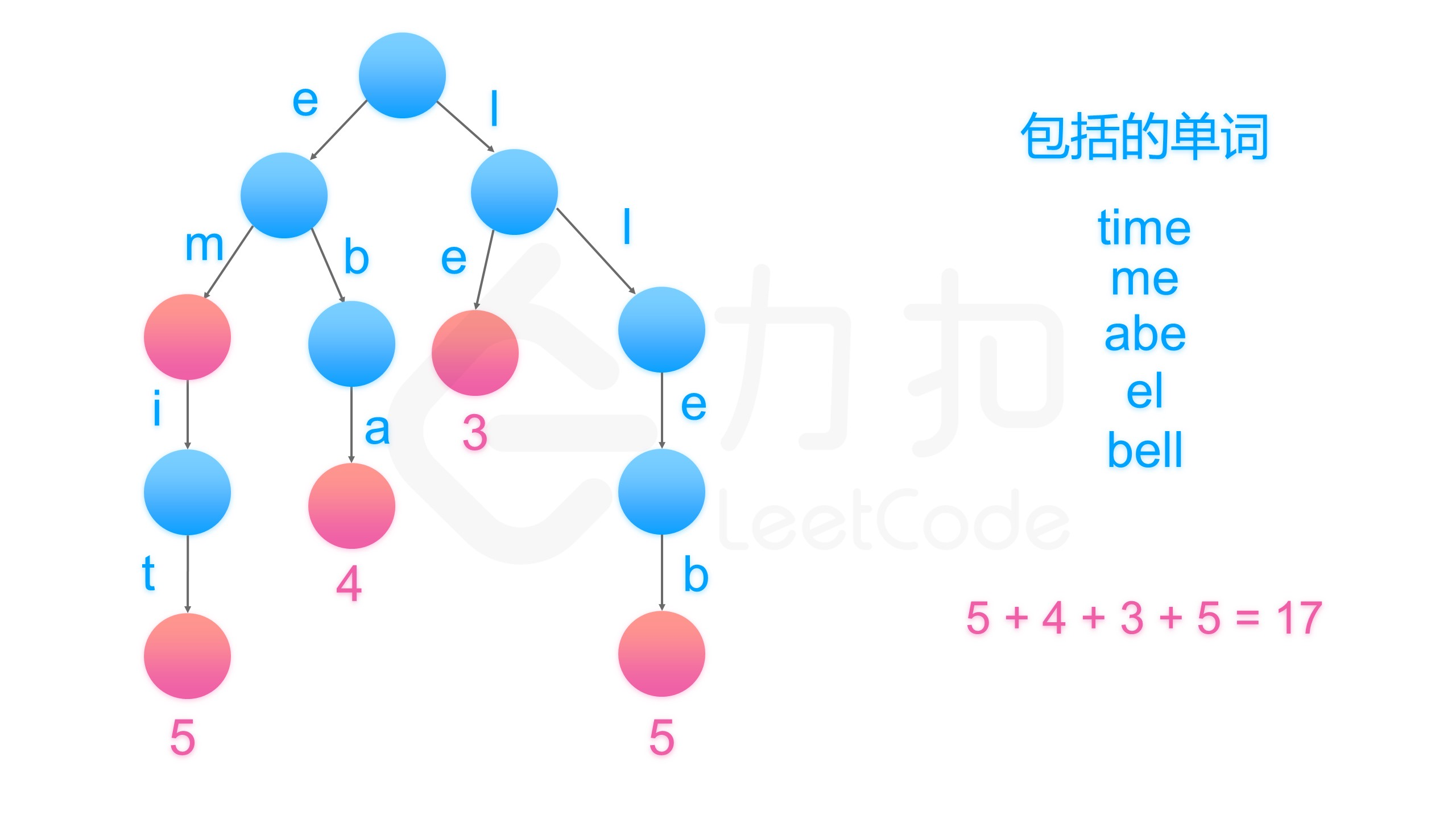
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 "#" 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
示例:
输入: words = ["time", "me", "bell"]
输出: 10
说明: S = "time#bell#" , indexes = [0, 2, 5] 。
提示:
1 <= words.length <= 2000
1 <= words[i].length <= 7
每个单词都是小写字母 。
https://leetcode-cn.com/problems/short-encoding-of-words
今天leetcode的每日一题的官方题解的python解法惊艳到我了,代码十分Pythonic,正好我也不太熟悉字典树和reduce的用法,学了一下:
简单的来说就是:一句话实现字典树,一句话完成建树过程。
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
words = list(set(words)) #remove duplicates
#Trie is a nested dictionary with nodes created
# when fetched entries are missing
Trie = lambda: collections.defaultdict(Trie)
trie = Trie()
#reduce(..., S, trie) is trie[S[0]][S[1]][S[2]][...][S[S.length - 1]]
nodes = [reduce(dict.__getitem__, word[::-1], trie)
for word in words]
#Add word to the answer if it's node has no neighbors
return sum(len(word) + 1
for i, word in enumerate(words)
if len(nodes[i]) == 0)
Trie = lambda: collections.defaultdict(Trie)这个循环嵌套字典是类似这样的效果{{{{}}}},意思是只要没有key的我们就返回一个空字典。
其实字典树的本质就是循环嵌套字典。
trie[word[-1]][word[-2]].........是写成这样了reduce(dict.__getitem__, word[::-1], trie)
下面给出@Lucien在leetcode题解下的评论解释
关于Python字典树方法的解释:
我们需要一棵字典树,把所有word加入这棵树
找到所有叶子的高度和
一步步从最正常的写法走向Pythonic的解。
# 定义字典树中的一个节点
class Node(object):
def __init__(self):
self.children={}
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
words = list(set(words)) #需要去重,否则在之后计算“叶子高度”的时候会重复计算
trie=Node() #这是字典树的根
nodes=[] #这里保存着每个word对应的最后一个节点,比如对于单词time,它保存字母t对应的节点(因为是从后往前找的)
for word in words:
now=trie
for w in reversed(word):
if w in now.children:
now=now.children[w]
else:
now.children[w]=Node()
now=now.children[w]
nodes.append(now)
ans=0
for w,c in zip(words,nodes):
if len(c.children)==0: #没有children,意味着这个节点是个叶子,nodes保存着每个word对应的最后一个节点,当它是一个叶子时,我们就该累加这个word的长度+1,这就是为什么我们在最开始要去重
ans+=len(w)+1
return ans
相信以上的解答大家可以看懂,那么就从Node开始简化。原先我们把Node声明为一个类,但这个类中只有一个字典,所以我们不如就直接用一个字典来表示节点,一个空字典以为着这是一个叶子节点,否则字典中的每一个元素都是它的一个孩子,上面的代码可以简化为:
class Solution:
def minimumLengthEncoding(self, words: List[str]) -> int:
words = list(set(words)) #需要去重,否则在之后计算“叶子高度”的时候会重复计算
trie={} #这是字典树的根
nodes=[] #这里保存着每个word对应的最后一个节点,比如对于单词time,它保存字母t对应的节点(因为是从后往前找的)
for word in words:
now=trie
for w in reversed(word):
if w in now:
now=now[w]
else:
now[w]={}
now=now[w]
nodes.append(now)
ans=0
for w,c in zip(words,nodes):
if len(c)==0: #一个空字典,意味着这个节点是个叶子
ans+=len(w)+1
return ans
继续简化,我们不想在生成字典树时每次都判断“当前字典有没有这个键”,我们希望,有这个键,就返回它的值,否则返回一个空字典给我。很自然,我们需要用到defaultdict,它默认返回一个字典。但,只是返回一个普通字典吗?比如defaultdict(dict)? 不行,实际上它需要返回一个defaultdict,且这个defaultdict仍旧会递归地返回defaultdict。于是,递归地,我们定义这样一个函数,它返回一个defaultdict类型,且它的默认值是该类型本身。 Trie = lambda: collections.defaultdict(Trie) ,注意,这里的Trie是一个函数,它返回一个defaultdict实例。有了它,我们创建字典树的过程就变成了:
nodes=[]
Trie = lambda: collections.defaultdict(Trie)
trie = Trie()
for word in words:
now=trie
for w in word[::-1]:
now=now[w]
nodes.append(now)
更进一步,可以简化为
nodes=[]
Trie = lambda: collections.defaultdict(Trie)
trie = Trie()
for word in words:
nodes.append(trie[word[-1]][word[-2]].........)
它就变成了
nodes = [reduce(dict.__getitem__, word[::-1], trie)
for word in words]
先不管数组的推导式,单看数组的一项 reduce(dict.getitem, word[::-1], trie),reduce三个参数分别为:方法,可循环项,初始值。即它初始值是trie,按照word[::-1]的循环顺序,每次去执行方法dict.getitem,且将这个输出作为下次循环的输入,所以它就是trie[word[-1]][word[-2]].........的意思。
最后一步的sum很简单,只要大家明白nodes里存的是什么就很明显了。
另外附上标准的C++写法:
class TrieNode{
TrieNode* children[26];
public:
int count;
TrieNode() {
for (int i = 0; i < 26; ++i) children[i] = NULL;
count = 0;
}
TrieNode* get(char c) {
if (children[c - 'a'] == NULL) {
children[c - 'a'] = new TrieNode();
count++;
}
return children[c - 'a'];
}
};
class Solution {
public:
int minimumLengthEncoding(vector<string>& words) {
TrieNode* trie = new TrieNode();
unordered_map<TrieNode*, int> nodes;
for (int i = 0; i < (int)words.size(); ++i) {
string word = words[i];
TrieNode* cur = trie;
for (int j = word.length() - 1; j >= 0; --j)
cur = cur->get(word[j]);
nodes[cur] = i;
}
int ans = 0;
for (auto& [node, idx] : nodes) {
if (node->count == 0) {
ans += words[idx].length() + 1;
}
}
return ans;
}
};
leetcode之820. 单词的压缩编码 | python极简实现字典树的更多相关文章
- python set() leetcode 签到820. 单词的压缩编码
题目 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", "bell& ...
- 【LeetCode】820. 单词的压缩编码 Short Encoding of Words(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址:https://leetcode-cn.com/problems/short- ...
- Java实现 LeetCode 820 单词的压缩编码(暴力)
820. 单词的压缩编码 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", & ...
- Java实现 LeetCode 820 单词的压缩编码(字典树)
820. 单词的压缩编码 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A. 例如,如果这个列表是 ["time", "me", & ...
- Python 极简教程(八)字符串 str
由于字符串过于重要,请认真看完并保证所有代码都至少敲过一遍. 对于字符串,前面在数据类型中已经提到过.但是由于字符串类型太过于常用,Python 中提供了非常多的关于字符串的操作.而我们在实际编码过程 ...
- [开发技巧]·Python极简实现滑动平均滤波(基于Numpy.convolve)
[开发技巧]·Python极简实现滑动平均滤波(基于Numpy.convolve) 1.滑动平均概念 滑动平均滤波法(又称递推平均滤波法),时把连续取N个采样值看成一个队列 ,队列的长度固定为N ...
- python极简代码之检测列表是否有重复元素
极简python代码收集,实战小项目,不断撸码,以防遗忘.持续更新: 1,检测列表是否有重复元素: 1 # !usr/bin/env python3 2 # *-* coding=utf-8 *-* ...
- python极简教程01:基础变量
测试奇谭,BUG不见. 其实很久之前,就有身边的同事或者网友让我分享一些关于python编程语言的教程,他们同大多数自学编程语言的人一样,无外乎遇到以下这些问题: 网络上的资料过多且良莠不全,不知道如 ...
- python极简教程04:进程和线程
测试奇谭,BUG不见. 大家好,我是谭叔. 这一场,主讲python的进程和线程. 目的:掌握初学必须的进程和线程知识. 进程和线程的区别和联系 终于开始加深难度,来到进程和线程的知识点~ 单就这两个 ...
随机推荐
- Python计算给定日期的周内的某一天
先理一下思路:1.weekday会根据某个日期返回0到6的一个数字来表示星期几对吧,0==星期一我们来列一个表: [0,1,2,3,4,5,6] 2.知道了星期几之后,你可以计算出那一周相对于这个0到 ...
- C++扬帆远航——7(年月日)
/* * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:charizi.cpp * 作者:常轩 * 完成日期:2016年 ...
- C语言职工信息管理系统
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- jvm的运行参数
1.我们为什么要对jvm做优化? 在本地开发环境中我们很少会遇到需要对jvm进行优化的需求,但是到了生产环境,我们可能将有下面的需求: 运行的应用“卡住了”,日志不输出,程序没有反应 服务器的CPU负 ...
- sql--自链接(推荐人)
表1: 需求:查出推荐人,和被推荐人 1.通过group_concat函数和分组,查出每个id推荐的人有哪些 select group_concat(u_name, u_id) as referce_ ...
- cmake引用包初探
应要求使用的是 mediastreamer2 库.以前开发是在tools下注册了一个新的tool,现在应该另行建立一个项目. 好像 CMake 写的项目叫package??? 项目名字是 mstest ...
- Xcode辅助工具之热重载插件利器
该博客首发于github.io 2018-06-13 13:43:44 文章最新修改于: 2019-03-31 13:47:20 昨天刚刚看完iOSTips微信公众号推送的文章, Injection: ...
- jinja2的url_for 和数据块
1.静态文件引入:{{ url_for('static', filename='文件路径') }} 2.定义路由:{{ url_for('模块名.视图名',变量=参数) }} 3.定义数据块: ...
- 安装msyql报错——error: Failed dependencies
报错原因: 1.存在两个版本的msyql-community-release. 解决方法: 1.将不要的哪个进行去除,使用命令: rpm -e --nodeps mysql80-community-r ...
- 鼠年开元用逐浪CMS v8.13版-NoSQL安装更轻便
作为国内领先的Zoomla!逐浪CMS,一直以来深受人道的除了其功能强大.性能稳定外,易用性也是其突出的现. 自Zoomla!逐浪CMS 8.x开始,官方在其程序包中,集成了一键安装进程,从而大大提升 ...