【Checkpoint】HA模式下结合zookeeper说一下checkpoint流程
checkpoint过程
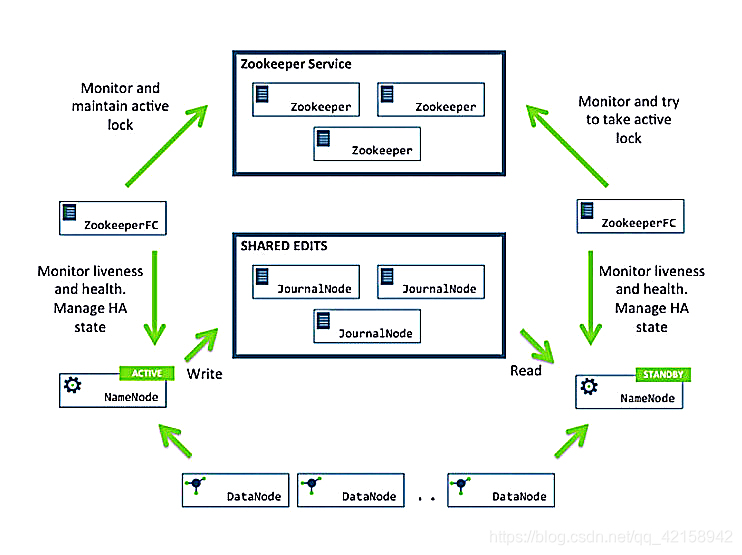
配置了HA的HDFS中,有active和standby namenode两个namenode节点。他们的内存中保存了一样的集群元数据信息,这个后续我会详细用一篇文章介绍HA,所以这里就不多说了。因为standby namenode已经将集群状态存储在内存中了,所以创建检查点checkpoint的过程只需要从内存中生成新的fsimage。
在hadoopHA中两个namenode节点为了数据同步会通过Journalnode相互通信。JournalNode存储管理EditsLog,俩个namenode共享这个EditsLog,两个NameNode都可以读取Edits;但EditsLog只有Active状态的NameNode节点可以做写操作;
- SBNN查看是否满足创建检查点的条件:
(1) 距离上次checkpoint的时间间隔 >= dfs.namenode.checkpoint.period(2)Edits中的事务条数达到{dfs.namenode.checkpoint.period}
(2) Edits中的事务条数达到dfs.namenode.checkpoint.period(2)Edits中的事务条数达到{dfs.namenode.checkpoint.txns}限制
这两个条件任何一个被满足了,就触发一次检查点创建。 - SbNN将内存中当前的状态保存成一个新的文件,命名为fsimage.ckpt_txid。其中txid是最后一个edit中的最后一条事务的ID(transaction ID)。然后为该fsimage文件创建一个MD5文件,并将fsimage文件重命名为fsimage_txid。
- SbNN向active namenode发送一条HTTP GET请求。请求中包含了SbNN的域名,端口以及新fsimage的txid。
- ANN收到请求后,用获取到的信息反过来向SbNN再发送一条HTTP GET请求,获取新的fsimage文件。这个新的fsimage文件传输到ANN上后,也是先命名为fsimage.ckpt_txid,并为它创建一个MD5文件。然后再改名为fsimage_txid。fsimage过程完成。
【Checkpoint】HA模式下结合zookeeper说一下checkpoint流程的更多相关文章
- Hadoop-2.X HA模式下的FSImage和EditsLog合并过程
补充了一下NameNode启动过程中有关FSImage与EditsLog的相关知识. 一.什么是FSImage和EditsLog 我们知道HDFS是一个分布式文件存储系统,文件分布式存储在多个Data ...
- HA模式下历史服务器配置
笔者的集群是 HA 模式的( HDFS 和 ResourceManager HA).在 ” Hadoop-2.5.0-cdh5.3.2 HA 安装" 中详细讲解了关于 HA 模式的搭建,这里就不再赘述 ...
- HA模式下的java api访问要点
在非HA架构的HDFS中,客户端要通过java接口调用HDFS时一般是在JobRunner的类中按照下面的方式: 因为nodename只有一个节点所以会在代码中显式的指明要连接哪一个节点:但是在HA模 ...
- Dalvik模式下System.loadLibrary函数的执行流程分析
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/78212010 Android逆向分析的过程中免不了碰到Android so被加固的 ...
- WLC HA模式下的注意事项
管理控制器:1.控制器默认开启的是SSH (CLI),Secure Web/https (GUI)2.登录控制器的管理地址为Active设备所控制(主备的配置同步,所以管理地址一致)3.WLC HA状 ...
- 在ZP的HA模式下 JM 重启失败
https://issues.apache.org/jira/browse/FLINK-10030 https://issues.apache.org/jira/browse/FLINK-10011 ...
- hadoop hdfs ha 模式
这是我自己在公司一个搭建公司大数据框架是自己的选项,在配置yarn ha 出现了nodemanager起不来的问题于是我把yarn搭建为普通yarn 如果有人解决 高yarn的nodemanager问 ...
- 浅谈SQL Server中的事务日志(三)----在简单恢复模式下日志的角色
简介 在简单恢复模式下,日志文件的作用仅仅是保证了SQL Server事务的ACID属性.并不承担具体的恢复数据的角色.正如”简单”这个词的字面意思一样,数据的备份和恢复仅仅是依赖于手动备份和恢复.在 ...
- 转发-【分享】思科无线控制器HA模式升级
思科无线控制器HA模式下升级文档 当前使用版本:8.0.120.0 计划升级版本:8.2.151.0 其他工具: TFTP Server: 3CDaemon 远程登录:SecureCRT ...
随机推荐
- GoF23:建造者模式
目录 概念 角色分析 实现方式 方式一 角色分析 代码编写 方式二 角色分析 代码编写 总结 优点 缺点 应用场景 建造者也抽象工厂模式的比较 建造者模式也属于创建型模式,它提供了一种创建对象的最 ...
- 经典卷积神经网络算法(2):AlexNet
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 用最基本的遍历来实现判断字符串 a 是否被包含在字符串 b 中,并返回第一次出现的位置(找不到返回 -1)
用最基本的遍历来实现判断字符串 a 是否被包含在字符串 b 中,并返回第一次出现的位置(找不到返回 -1) 例子: a='12';b='1234567'; // 返回 0 a='47';b='1234 ...
- 201771030120-王嫄 实验一 软件工程准备 <课程学习目的思考>
项目 内容 课程班级博客链接 https://edu.cnblogs.com/campus/xbsf/nwnu2020SE 这个作业要求链接 https://www.cnblogs.com/nwnu- ...
- 【Scala】利用akka实现Spark启动通信
文章目录 思路分析 步骤 一.创建maven工程,导包 二.master进程代码开发 三.worker进程代码开发 思路分析 1.首先启动master,然后依次启动worker 2.启动worker时 ...
- c#实现生成PDF的底层方法
在用uwp生成pdf的时候,发展此类类库有限,有的也需要钱,我最后实现pdf的底层方法生成pdf,代码如下 private async void GeneratePdf() { var file = ...
- SpringBoot基础实战系列(三)springboot单文件与多文件上传
springboot单文件上传 对于springboot文件上传需要了解一个类MultipartFile ,该类用于文件上传.我此次使用thymeleaf模板引擎,该模板引擎文件后缀 .html. 1 ...
- Web_python_template_injection
0x01 pthon模板注入 判断是否为模板注入 paload http://124.126.19.106:34164/{{1+1}} //如果里面的值被执行了,那么存在模板注入 //调用os模块的p ...
- WriteUp_easy_sql_堆叠注入_强网杯2019
题目描述 随便注 解题过程 查看源码,发现应该不适合sqlmap自动化注入,该题应该是让你手工注入: <!-- sqlmap是没有灵魂的 --> <form method=" ...
- zz MySQL redo log及recover过程浅析
原作地址:http://www.cnblogs.com/liuhao/p/3714012.html 写在前面:作者水平有限,欢迎不吝赐教,一切以最新源码为准. InnoDB redo log 首先介绍 ...