Python爬虫系列(二):requests基础
1.发送请求:
import requests
# 获取数据
#r是一个 response 对象。包含请求返回的内容
r = requests.get('https://github.com/timeline.json')
print(r.content)
打印结果:
b'{"message":"Hello there, wayfaring stranger. If you\xe2\x80\x99re reading this then you probably didn\xe2\x80\x99t see our blog post a couple of years back announcing that this API would go away: GitHub API v2: End of Life Fear not, you should be able to get what you need from the shiny new Events API instead.","documentation_url":"Events | GitHub Developer Guide"}'
发送请求有4中方式,就是http协议的4中method:
r = requests.put("http://httpbin.org/put")
r = requests.delete("http://httpbin.org/delete")
r = requests.head("http://httpbin.org/get")
r = requests.options("http://httpbin.org/get")
2.传递 URL 参数
以下两种方式,是通过url传参。参数,必须是一个字典
import requests
payload1 = {'key1': 'value1', 'key2': 'value2'}
r1 = requests.get("http://httpbin.org/get", params=payload1)
print(r1.url)
payload2 = {'key1': 'value1', 'key2': ['value2', 'value3']}
r2 = requests.get('http://httpbin.org/get', params=payload2)
print(r2.url)
对应结果:
http://httpbin.org/get?key1=value1&key2=value2
http://httpbin.org/get?key1=value1&key2=value2&key2=value3
注意看差别
3.响应内容
r = requests.get('https://github.com/timeline.json')
#获取响应结果
print(r.text)
#获取内容编码
print(r.encoding)
#修改内容编码方式。修改之后再取text将使用新的编码方式
r.encoding = 'ISO-8859-1'

注意符号上编码不同
将内容编辑成二进制
i = BytesIO(r.content)
将内容转为JSON对象
print(r.json())
注意:成功调用 r.json() 并不意味着响应的成功。有的服务器会在失败的响应中包含一个 JSON 对象(比如 HTTP 500 的错误细节)。这种 JSON 会被解码返回。要检查请求是否成功,请使用 r.raise_for_status() 或者检查 r.status_code 是否和你的期望相同
原始响应内容
什么是原始内容?客户端和服务器端建立socket的那一层取回的内容。需要设置stream=True才能取回,返回的是urllib的对象。
r = requests.get('https://github.com/timeline.json', stream=True)
#取回流中的100个字节的内容
r.raw.read(100)

但是,若是要将返回的数据保存为文件,应这样使用流:
with open(filename, 'wb') as fd:
for chunk in r.iter_content(chunk_size):
fd.write(chunk)
用Response.iter_content替代r.raw
4.定制请求头
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'my-app/0.0.1'}
#说白了就给url传参数
r = requests.get(url, headers=headers)
有以下内容要注意:
注意: 定制 header 的优先级低于某些特定的信息源,例如:
如果在 .netrc 中设置了用户认证信息,使用 headers= 设置的授权就不会生效。而如果设置了auth= 参数,``.netrc`` 的设置就无效了。
如果被重定向到别的主机,授权 header 就会被删除。
代理授权 header 会被 URL 中提供的代理身份覆盖掉。
在我们能判断内容长度的情况下,header 的 Content-Length 会被改写。
更进一步讲,Requests 不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的 header 信息都会被传递进去。
注意: 所有的 header 值必须是 string、bytestring 或者 unicode。
5.更加复杂的 POST 请求
import requests
# 传递元组
payload1 = (('key1', 'value1'), ('key1', 'value2'))
r1 = requests.post('http://httpbin.org/post', data=payload1)
# 传递字典
payload2 = {'key1': 'value1', 'key2': 'value2'}
r2 = requests.post("http://httpbin.org/post", data=payload2)
# 传递JSON字符串
url1 = 'https://api.github.com/some/endpoint'
payload3 = {'some': 'data'}
r3 = requests.post(url1, data=json.dumps(payload3))
# 传递JSON对象
url2 = 'https://api.github.com/some/endpoint'
payload4 = {'some': 'data'}
r4 = requests.post(url2, json=payload4)
6.传文件
import requests
url = 'http://httpbin.org/post'
# files = {'file': open('report.xls', 'rb')}
# 显式地设置文件名,文件类型和请求头
# files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
# 把字符串当做文件来发送
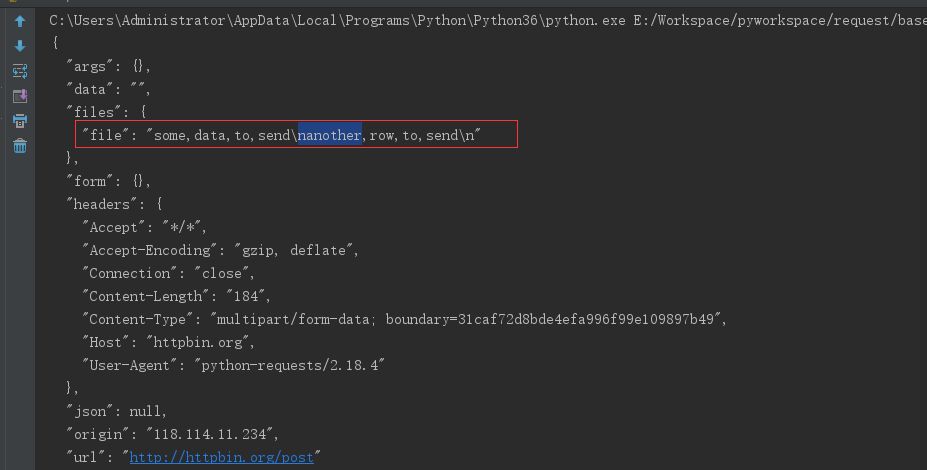
files = {'file': ('report.xls', 'some,data,to,send\nanother,row,to,send\n')}
r = requests.post(url, files=files)
print(r.text)
第3步响应结果
注意:官方建议使用 requests-toolbelt 发送多个文件。后面我们将进一步演示
7.响应状态码
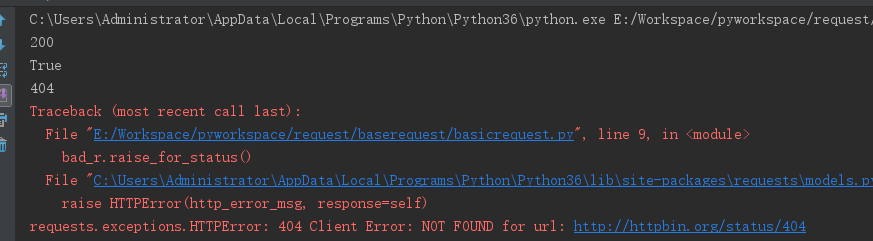
r = requests.get('http://httpbin.org/get')
print(r.status_code)
# 状态查询对象:requests.codes
print(r.status_code == requests.codes.ok)
bad_r = requests.get('http://httpbin.org/status/404')
print (bad_r.status_code)
# 在请求有问题的时候,raise_for_status()方法会手动出发异常
bad_r.raise_for_status()
执行结果:
8.响应头
import requests
r = requests.get('http://httpbin.org/get')
print(r.status_code)
#获取响应头。响应头是字典
print(r.headers)
print(r.headers['Content-Type'])
print(r.headers.get('content-type'))
9.Cookie
import requests
url = 'http://example.com/some/cookie/setting/url'
r = requests.get(url)
# 获取请求返回的cookies
r.cookies['example_cookie_name']
url = 'http://httpbin.org/cookies'
# 把请求带上cookies 这玩意在模拟登录后经常使用
r = requests.get(url, cookies=cookies)
r.text
# Cookie 的返回对象为 RequestsCookieJar,它的行为和字典类似,适合跨域名跨路径使用
#妹的,这是跨域吗。明明是模仿免登录
jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='httpbin.org', path='/cookies')
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
url = 'http://httpbin.org/cookies'
r = requests.get(url, cookies=jar)
r.text
10.重定向与请求历史
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向。
什么是重定向:输入的是A地址却自动跳转到B地址
以下实例:放回的301代表永久性重定向。不要纠结过多,记住就行了。
这里需要理解:本实例明明访问一个地址,为什么就重定向了。因为访问的是域名,DNS会自动转向实际的服务器,这里就重定向了
Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
r = requests.get('http://github.com')
print(r.url)
print(r.history)
禁用重定向:
使用GET、OPTIONS、POST、PUT、PATCH 或者 DELETE,那么可以通过 allow_redirects 参数禁用重定向处理
r = requests.get('http://github.com', allow_redirects=False)
print(r.status_code)
print(r.history)
使用HEAD启动重定向:
r = requests.head('http://github.com', allow_redirects=True)
print(r.history)
11.超时
r=requests.get('http://github.com', timeout=0.001)
超时:是非常有用的。若是不设置超时,在很长一段时间都没返回,那么程序就会阻塞。timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在timeout 秒内没有从基础套接字上接收到任何字节的数据时)
12.错误与异常
遇到网络问题(如:DNS 查询失败、拒绝连接等)时,Requests 会抛出一个 ConnectionError 异常。
如果 HTTP 请求返回了不成功的状态码, Response.raise_for_status() 会抛出一个 HTTPError异常。
若请求超时,则抛出一个 Timeout 异常。
若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects 异常。
所有Requests显式抛出的异常都继承自 requests.exceptions.RequestException
截止目前,我们对requests有了一个基本认识。明天,我们将进一步讨论requests高级耍法。
我只希望公司的新同事,牛小妹能花点时间仔细看下,代码拿来运行下,看有什么效果。
Python爬虫系列(二):requests基础的更多相关文章
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- 爬虫系列(七) requests的基本使用
一.requests 简介 requests 是一个功能强大.简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装 下面我们将会介绍 requests 中常用 ...
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- 爬虫简介、requests 基础用法、urlretrieve()
1. 爬虫简介 2. requests 基础用法 3. urlretrieve() 1. 爬虫简介 爬虫的定义 网络爬虫(又被称为网页蜘蛛.网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程 ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
随机推荐
- 基于SIP协议的性能测试——奇林软件kylinPET
一.Sip协议简介: SIP(Session Initiation Protocol,会话初始协议)是由IETF(Internet Engineering Task Force,因特网工程任务组)制定 ...
- WEB应用之httpd基础入门(二)
前文我们聊了下httpd的一些基础设置,聊了下httpd的配置文件格式,长连接.mpm的配置以及访问控制基于文件路径和URL管控,回顾请参考https://www.cnblogs.com/qiuhom ...
- Python-列表做的购物车小程序
一.流程为,输入你有多少钱,然后循环购买商品,输入‘q’ 退出程序 goods=[['苹果',6500],['华为',4999],['小米',2999],['oppo',3599]] #初始化列表,填 ...
- Flutter 使用阿里巴巴icon库
在Flutter默认创建的项目中可以使用系统Material图标,在pubspec.yaml文件中使用图标设置如下: flutter: uses-material-design: true 系统图标如 ...
- eNSP 交换机 路由器 PC 互连设计/实现
0.实验目的 1.掌握网络设计的原理与步骤: 2.掌握IP分配.网关设置原则: 3.了解路由协议的作用,掌握网络互联设备的作用和配置. 1.实验环境 环境:eNSP模拟器 版本信息:1.3.00.10 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 1: 回归案例研究
引言: 最近开始学习"机器学习",早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程.今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子 ...
- 使用sstream进行int转换string的注意事项
个人网站 :http://39.106.25.239/ 1.引入sstream文件 2.使用stringstream 声明 3.使用一次sstream转换后要执行成员函数.clear() 来清除str ...
- 【深度学习】Neural networks(神经网络)(一)
神经网络的图解 感知机,是人工设置权重.让它的输出值符合预期. 而神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数. 如果用图来表示神经网络,最左边的一列称为输入层,最右边的一列称为输 ...
- 干净直接安装+PS下载
PS CS6 https://www.cr173.com/soft/247727.html 直接一键安装,很方便干净. 不要去华军软件下,广告浪费时间. 链接:https://pan.baidu.co ...
- AttributeError: module 'tensorflow.python.keras.backend' has no attribute 'get_graph'处理办法
原因:安装的tensorflow版本和keras版本不匹配,只需卸载keras,重新安装自己tensorflow对应的版本. Keras与tensorflow版本匹配查询网站