AI 大模型科普-概念向
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:奇铭
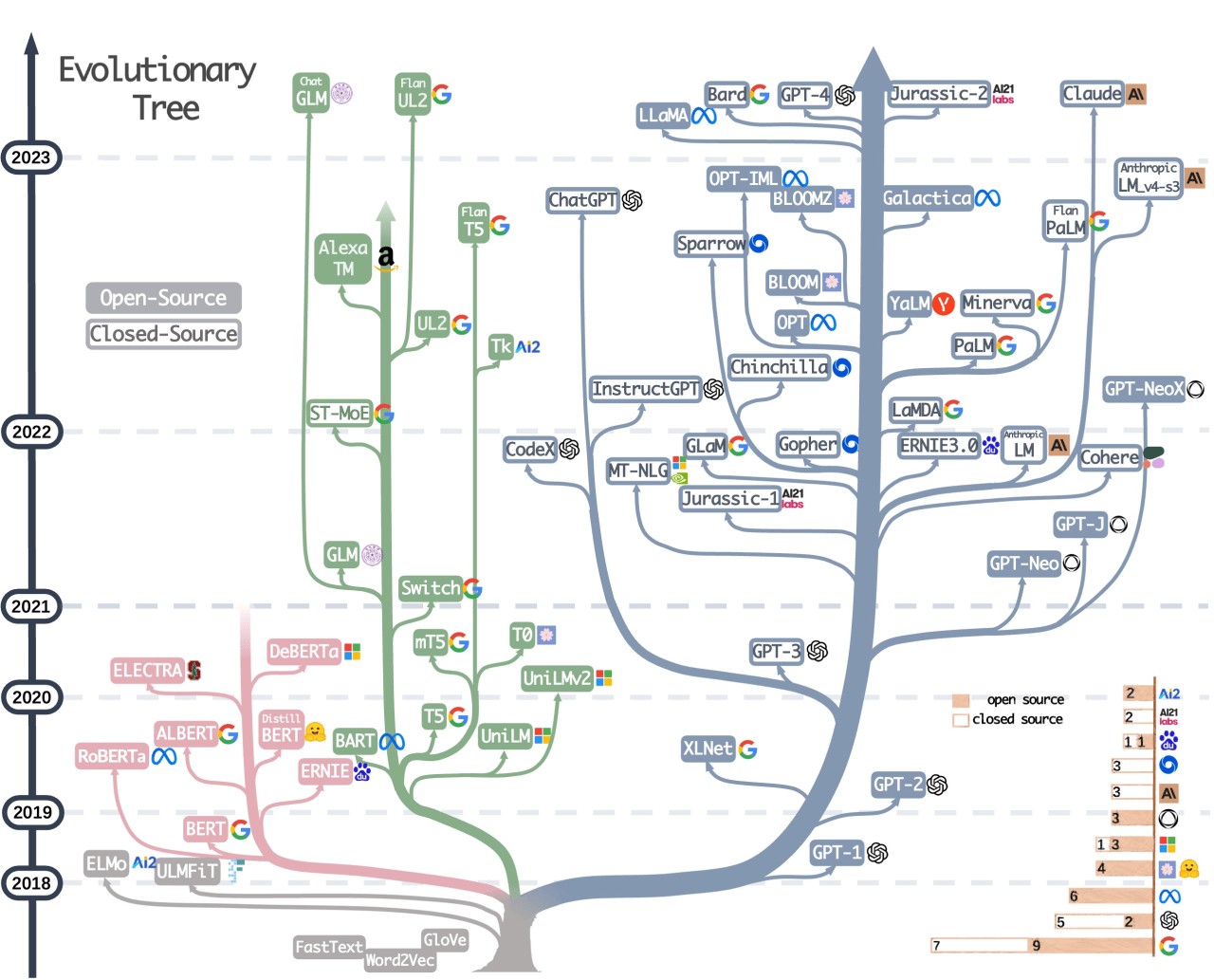
什么是大模型(LLM)
大模型(LLM)即大型语言模型(Large Language Model),它是一种具有大规模参数和复杂计算结构的人工智能语言模型。它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、文本生成,翻译、情感分析等等。LLM 的特点是规模庞大,包含数十亿的参数,能够学习语言数据中的复杂模式。
从某种角度上讲,可以将大模型看做一个巨大的函数,这个巨大的函数会基于已经给出的训练数据学习输入到输出的映射关系。这种关系通常是高度复杂且非线性的,而大模型则特别擅长于学习并应用这种复杂的映射关系,模型的参数量可以在一定意义上代表这种映射关系的复杂度。
模型参数量
通常情况下,参数量的大小与大模型性能呈正相关关系,比如最广为人知的 GPT ,其 3.5 版本有 1750亿(175B)参数,目前 OpenAI 暂未公布 ChatGPT4 的参数量,有传闻称 GPT-4 的参数数量约为恐怖的 100 万亿个。但是也有研究表明,大模型的参数与其性能并不成线性相关关系,也即大模型的参数量不是越大越好,会有一个临界阈值。
除此之外,很多模型都存在参数量不同的变体版本:比如可以从 Hugging Face 上看到 Meta-llama3 就有多个不同参数量的变体版本
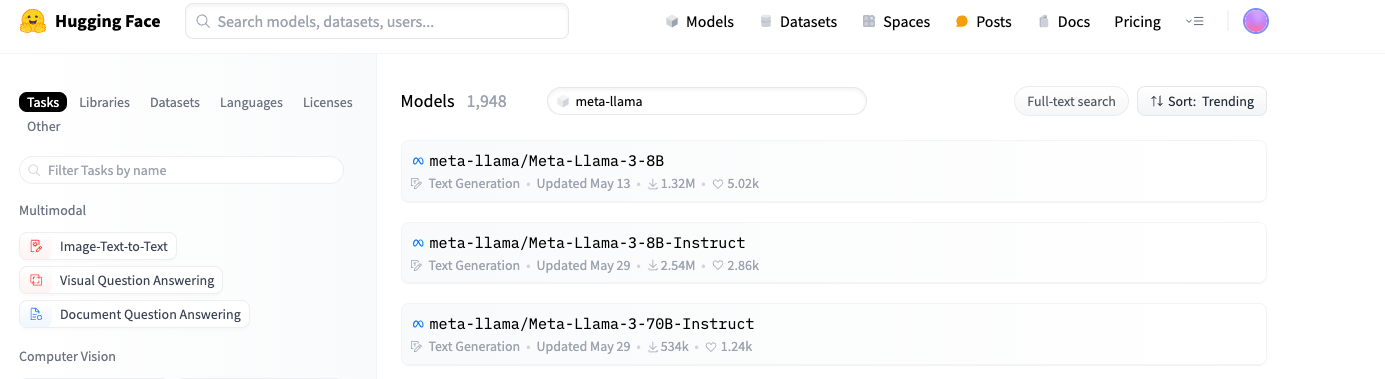
虽然通常情况下参数量越大的模型在执行任务的时候表现得越好,但是有些场景受设备性能的制约,无法部署参数量太大的模型,比如在移动设备上。
模型分类
单从自然语法处理(NLP)模型来说,就有很多的功能分类,下图为 Hugging Face 网站的 NLP 模型类型标签
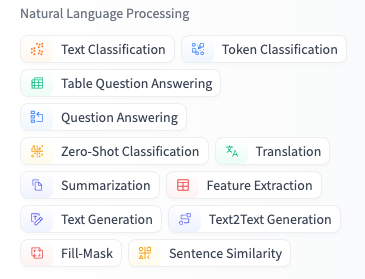
例如: Meta-Llama-3、ChatGPT、Google/gemma-2 都是 Text Generation 模型(文本生成),文本生成模型参数量较大,一般参数量在 8B 以上,因为文本生成相对来说是更加复杂的任务。而掩码语言模型(Fill-Mask) 和文本分类模型(Text Classification)则一般参数量较小,约为几百 M 。
除了最为常见的语言模型以外,还有视觉模型、语音模型等,以及目前很火的多模态模型,多模态模型是指,大模型可以同时处理多种类型的输入,比如可以同时向模型输入文本和图片。
模型训练
目前常见的大语言模型的训练大体分为两个阶段:预训练阶段(Pre-Training) 和 微调阶段(Fine-Tuning)
预训练阶段使用大规模的、通常没有人工标注的文本数据,这些数据可以是来自互联网、书籍、百科等公开的资源,大模型在这些数据上通过自监督学习的方式进行训练。
例如,预测掩码语言模型任务(MLM ⇒ Mask Language Model),即模型接收输入文本,其中一部分单词被替换成一个特殊的掩码标记,例如[MASK]。模型的任务是预测被掩码的单词,只依赖于掩码词汇的上下文。再例如下一个句子预测任务(NSP ⇒ Next Sentence Prediction),模型需要预测一个句子是否在另一个句子之后出现。这对于理解两个句子之间的关系(比如,它们是否连贯)非常有用,也有助于提高模型在诸如问答和自然语言推理任务上的表现。在这些任务中,模型通过最大化自身预测正确的概率来调整自身参数,Google 的 Bert 模型就是用这两种方式进行训练的。
预训练阶段类似于学生在学校里接受语言教学,学习词汇、语法、句子结构等基础知识,这个过程非常广泛和通用,不针对特定的目标或应用。更具体地说,对于大模型来说,预训练通常在大量的数据上进行,这些数据能够包含丰富且广泛的语言信息。例如,一个预训练的语言模型可能会在整个维基百科的文本上进行学习,意图理解语言的基础语法和模式。
微调阶段则类似于学生根据他的特定需求(比如出国旅游、进行商务谈判等)进一步学习和实践语言。这个阶段的学习更加具有针对性,目标是适应特定的任务或场景。对于深度学习模型来说,微调就是在预训练的基础上,使用特定任务的数据(比如情感分类、问题回答等)进行进一步的训练,使模型更好地适应这种特定任务。
微调阶段使用更加结构化的人工标注好的数据集来训练,这些数据集通常是特定领域的,通常包括(指令、问题、答案等)再通过将提示词模版结合。模型通过输入带有标签的训练数据来调整模型参数,使得模型能够更好地预测标签信息。
如下图是一个可以用于增强大模型 Text2SQL 能力的数据集:
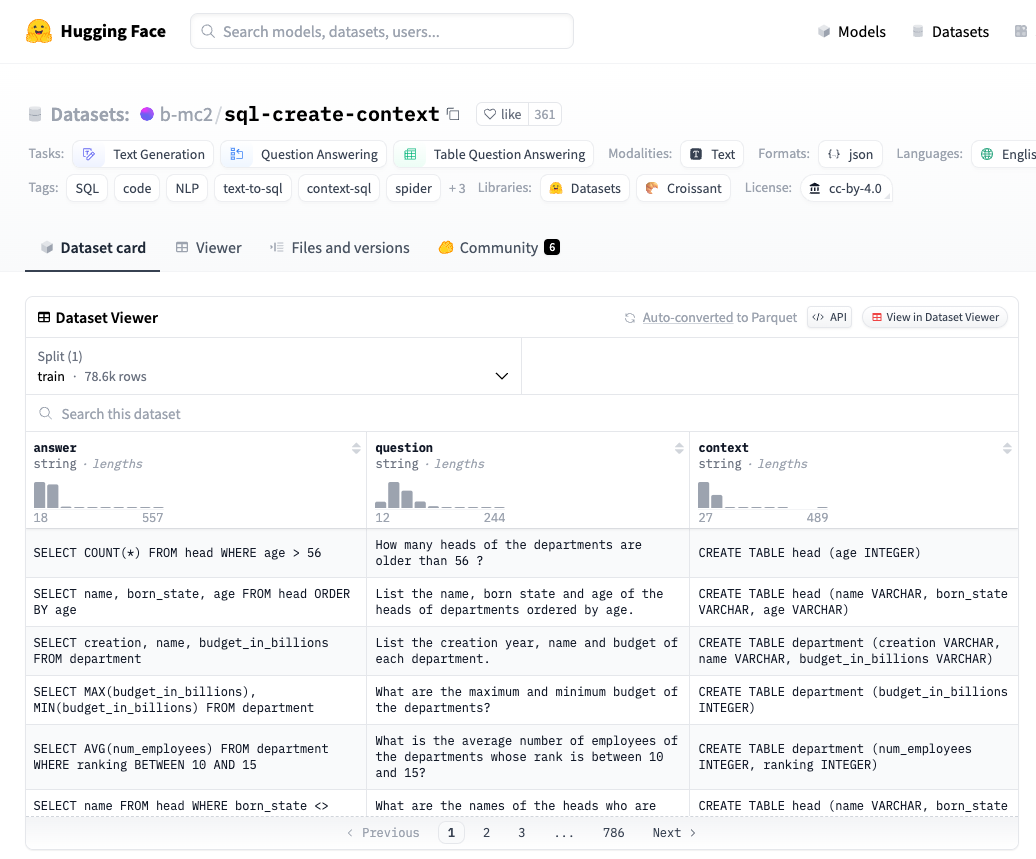
其数据结构为:
{
"question": "Please show the themes of competitions with host cities having populations larger than 1000.",
"context": "CREATE TABLE city (City_ID VARCHAR, Population INTEGER); CREATE TABLE farm_competition (Theme VARCHAR, Host_city_ID VARCHAR)",
"answer": "SELECT T2.Theme FROM city AS T1 JOIN farm_competition AS T2 ON T1.City_ID = T2.Host_city_ID WHERE T1.Population > 1000"
},
{
"question": "Please show the different statuses of cities and the average population of cities with each status.",
"context": "CREATE TABLE city (Status VARCHAR, Population INTEGER)",
"answer": "SELECT Status, AVG(Population) FROM city GROUP BY Status"
},
预训练模型在使用该数据集微调后,可以增强执行 text2SQL 任务方面的性能。
Prompt
想要提高大模型在某些特定任务上的表现,除了微调模型以外,还可以通过设计 Prompt 来达成。从提高大模型在某些特定任务上的表现这方面来说,微调和 Prompt 是不同的方式,但是在作用上是互补关系。通俗点讲,微调是增强大模型处理特定任务的能力,而 Prompt 通常用于引导模型的输出,激发大模型在处理特定任务时的潜力。
Prompt 即提示词,是提供给模型的输入,也可以理解为问大模型的问题或者给大模型输入的任务描述。在 ChatGPT 网站中,用户向 ChatGPT 提出的问题即可被视为一个 Prompt。Prompt 设计在绝大多数自然语言处理(NLP)模型上都发挥着重要作用。
Prompt 要素
提示词可以包含下列任意的要素:
- 指令:想要模型执行的特定任务或指令。
- 上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据:用户输入的内容或问题。
- 输出指示:指定输出的类型或格式。
提示词所需的格式取决于想要语言模型完成的任务类型,并非所有以上要素都是必须的。
下面是一个提示词的例子,旨在按照要求自动生成 FlinkSQL 语句,并且仅返回 SQL 语句,不包含任何自然语言描述
指令:按要求生成 FlinkSQL
上下文:students 表建表语句是 `CREATE TABLE students (age INTEGER)`
输入数据:查询年龄小于18岁的学生的数量
输出提示:仅生成SQL语句不需要任何其他描述
大模型(QWEN 2.5)的输出为:
SELECT COUNT(*) FROM students WHERE age < 18;
样本提示
上述例子中不包含任何的样本提示,即(zero-shot),但是由于上例中提示词的任务描述已经足够完善,所以大模型的生成内容可以满足要求,但是某些场景下,需要给一些示例(one-shot, few-shot),启用大模型的上下文学习能力以完成更加复杂的任务。
比如有以下提示词:
“sssggg”是一种小型毛茸茸的动物。一个使用sssggg这个词的句子的例子是:
我们在非洲旅行时看到了这些非常可爱的sssggg。
“dddkkk”是指快速跳上跳下。一个使用dddkkk这个词的句子的例子是:
注:这里的示例目的是展示大模型的上下文学习能力
大模型(QWEN 2.5)生成内容为:
那只小松鼠在树枝间dddkkk,看起来非常活泼。
可以看到,大模型已经展示了强大的上下文学习能力,仅通过提供一个示例(one-shot)已经学会了如何执行任务。对于更困难的任务,我们可以尝试增加示例即 few-shot(例如3-shot、5-shot、10-shot等)。
目前 Prompt 已经逐渐发展为一门学科,甚至早就已经出现了 Prompt 工程师的岗位,本文中仅通过一些说明和示例展示了 Prompt 工程的部分作用和重要性。
RAG(检索增强生成)
大模型的预训练通常使用公开数据和文档,这意味着,预训练后的大模型仅学会了最为通用和常见的知识,但是对于特定领域或者行业的知识,大模型并没有学习到。想要做到这一点,首先想到的就是上文中提到的微调,通过微调可以将特定的知识注入到大模型中。
但是对于对于一些任务,尤其是需要大范围的专业知识的任务,普通的微调模型可能无法很好地回答问题。RAG(Retrieval-augmented Generation)可以通过使用大规模的知识库,可以在需要的时候检索和提供相关的信息,从而解决传统微调模型无法解决的问题。 RAG 大体上可以分为两个部分:
知识向量化
第一部分是将知识文档落入向量数据库
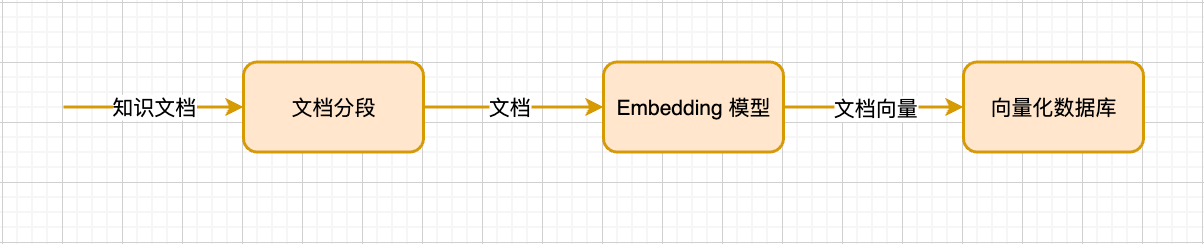
知识文档首先会被按照固定的切分规则切分为文本块,这些文本块被嵌入模型(Embedding 模型)转换为文本向量,再将文本向量存入向量数据库中。值得注意的是,原文档块仍然会被保留,并与其生成的文本向量呈关联关系。
检索召回
第二部分是,当用户问出问题时,先将用户的问题通过文本向量化模型转化为问题向量,并在上述提到的向量库中检索:

可以理解为知识向量化时,存入向量数据库的是知识块的语义,在检索时,向量数据库会根据 Prompt 向量(Prompt 的语义)在数据库中检索与 Prompt 语义相近的向量,然后返回其关联的文本块。
被检索出的文本块会作为上下文和用户输入的 Prompt 组合在一起,输入给大模型。上文中样本提示(few-shot) 中有提到,大模型拥有较强的上下文学习能力,RAG 也正是依靠这一点提升大模型在特定领域上的性能。
这里只是简单描述了 RAG 工作的基本原理,真实场景下的RAG应用要复杂的多,比如在知识文档向量化以前,可能需要进行清洗,再比如检索方式也分为多种如迭代检索,递归检索、自适应检索等。目前市面上已经出现了很多RAG应用,比如最为常见的 AI 知识库。
词嵌入
行文至此,仍有一些问题没有被说明,那就是大模型是如何“理解”人类语言的?向量库为什么可以检索出与 Prompt 语义相近的文本块?向量化又是什么?
机器理解人类语言是通过词与词之间的关联关系来做到的,这种关联关系即语义关系。比如在训练过程中,大模型会发现“苹果”与“橘子”的语义相近,“今天”和“天气怎么样”经常一起出现。
分词处理
要表达词与词的关联关系,第一步就是要对人类语言进行分词处理,分词处理的方式有很多种,比如按照字节分词,按照单词分词或者按照词根分词,经过分词处理后就形成了一个个 token 组成的词汇表。
独热编码
接着就要对这些 token 进行数字化处理,通常它们被使用独热编码(one-hot) 来进行编码,例如 “苹果”, “香蕉” 和 “华为” 等 token 使用独热编码可以表示为
- 苹果:[1, 0, 0, …0]
- 香蕉:[0, 1, 0, …0]
- 华为:[0, 0, 1, …0]
用独热编码表示这些 token,可以视作将所有的 token 都转化为相互正交且模长相等的向量,这些向量由于相互正交,内积为 0,所以每一个向量之间并不存在远近关系。
从另一个角度讲,使用独热编码,则每一个 token 都有自己的维度,每一个维度都代表着这个 token 的语义,但在在一个维度很高的语义空间中信息密度过于稀疏,所以也就无法体现 token 之间的语义关系。
我们期望的 token 数字化以后可以体现 token 之间的语义关系,比如苹果作为水果在水果这个维度上的值应该与香蕉相近,作为手机在电子产品这个维度上应该与华为相近。比如第一个维度代表水果语义,第二个维度作为电子产品语义,则“苹果”, “香蕉” 和 “华为” 的向量化表示就大概应该是这样:
- 苹果:[0.7, 0.6, 0, …0]
- 香蕉:[0.9, 0.05, 0, …0]
- 华为:[0.01, 0.8, 0, …0]
嵌入矩阵
独热编码产生的向量由于向量维度过高的原因,导致其信息密度过于稀疏,以至于无法表达向量间的关系,即无法体现词与词之间的语义关系,所以需要对其进行降维处理,这一点则是通过嵌入矩阵做到。
比如词汇表中有 N 个 token,那么每一个 token 就是一个 N 维向量,相应的嵌入矩阵就是则是一个 N X D 的矩阵,将 token 向量作为一个 1 X N 的矩阵与这个 N X D 的矩阵相乘,就得到了一个 1 X D 的矩阵,即一个 D 维向量。
这个 N X D 的矩阵就是嵌入矩阵,这个过程被称为词嵌入(Word Embedding)。嵌入的意思就是将一个向量丛某个空间嵌入到另一个空间, 词嵌入的过程就是将 one-hot 编码出的高维向量丛高维空间嵌入到低维空间。
通常情况下上面提到的 N 被称为词汇量,即词汇表的大小,而 D 被称为嵌入维度,我们也可以将 D 理解为语义维度。以 GPT3 为例,其词汇表中约有 50000 tokens,其最小的变体版本 GPT-3 Small的嵌入维度为 768,而最为常见的 GPT3 版本也就是上文中提到的参数量为 175B 的版本其嵌入维度为 12288。
词嵌入的过程,其实也是信息被压缩的过程,也就是说嵌入维度越小,信息被压缩的越厉害,相应的每个词向量能表达的语义越少,但是其好处是,在新的语义空间中,信息更加密集,更加容易体现词之间的关系,后续的计算和存储成本就越低。模型设计时需要在嵌入维度和资源利用之间找到平衡。
事实上,大模型的训练大部分时候都是在进行矩阵运算,这也就不难理解为什么AI对于显卡的要求很高,因为显卡在做图形处理时,也是在进行矩阵运算,属于是专业对口了。
嵌入矩阵除了降维以外,另一项更为重要的工作就是,在通过该矩阵进行转换后,语义上相似的词向量距离较近。那么现在的问题就是,如何得到这个嵌入矩阵?
如何找到嵌入矩阵?
以 Word2Vec 为例, Word2Vec 是一种用于自然语言处理的技术,该技术的核心思想是通过深度学习的方法,将词语(单词)映射到一个连续的向量空间,使得在这个空间中,语义上相似的词语距离较近。Word2Vec 具体包括两种模型架构:连续词袋模型(CBOW,Continuous Bag-of-Words)和 Skip-Gram 模型。
CBOW 模型和 Skip-Gram 模型互为镜像:
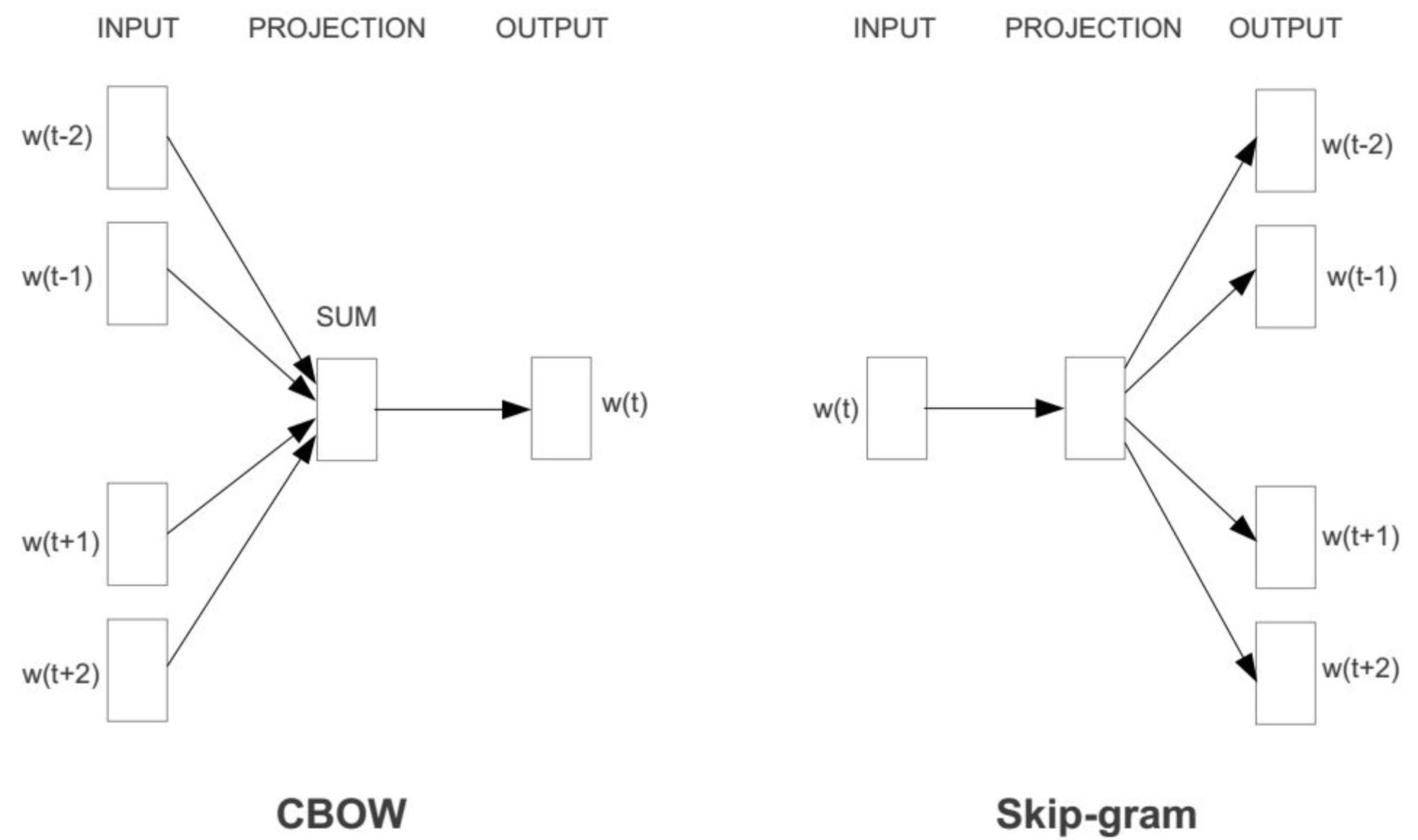
CBOW 模型训练(自监督训练)的大体思路是,将一个包含奇数个 token 的语句,拿掉中间的 token,然后将其他的 token 投入嵌入矩阵中,再将得到嵌入后的词向量加起来得到一个新向量,最后将这个token进行解码,看是否与被拿掉的 token 相同,然后根据对比结果的差异去调整矩阵参数。
CBOW 模型训练的原理类似于受力分析,语义关系都需要根据上下文来,如果只能从一段文本中才能理解一个token 的语义,那么也就是能且只能通过上下文来推断。反之,根据上下文也应该能推断出 token 语义 , 只是这种推断的方式在这里体现为向量相加。
Skip-gram 则与 CBOW 完全相反,它的训练思路是,通过一个token去推断其上下文的token。
Transformer
Word2vec 在现在的角度来看已经是比较旧的技术了,常见的大模型如 GPT、Llama、QWEN 都是基于更为先进的 Transformer 架构:
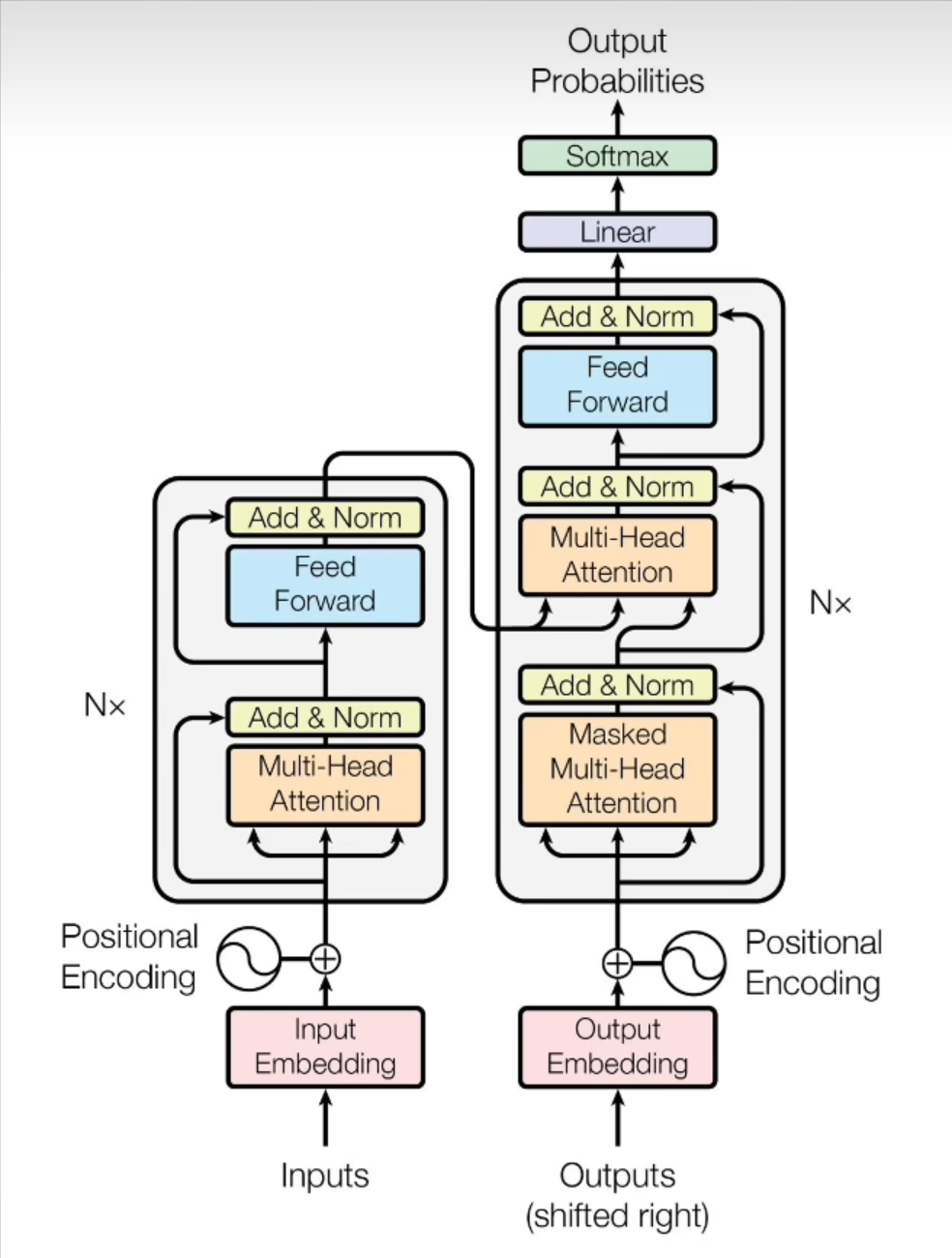
Transformer 架构中引入了位置编码以及自注意力机制,使得模型能够在理解文本语义的基础上,还能快速找到文本中的重点内容,同时其嵌入矩阵的训练方法也更为复杂。
后日谈
- 大语言模型是银弹吗?人类的思维是用语言为载体的吗?
- AI 目前还没有自我意识? ⇒ 如何测试 AI 有没有自我意识? ⇒ AI 有自我意识后产生的问题?
- 人类是计算的吗? 我们这个世界是计算的吗? 是否分为计算的和非计算的部分,AI 在尝试算尽人类, 但是目前数学界或者物理界还无法确认宇宙万物是不是都遵从可以用数学方法描述的各种法则
- 大模型基于现有的人类知识,依赖概率统计和线性代数,那么概率统计和线性代数能够产生思维吗?
最后
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
- 大数据分布式任务调度系统——Taier
- 轻量级的 Web IDE UI 框架——Molecule
- 针对大数据领域的 SQL Parser 项目——dt-sql-parser
- 袋鼠云数栈前端团队代码评审工程实践文档——code-review-practices
- 一个速度更快、配置更灵活、使用更简单的模块打包器——ko
- 一个针对 antd 的组件测试工具库——ant-design-testing
AI 大模型科普-概念向的更多相关文章
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- 阿里开源新一代 AI 算法模型,由达摩院90后科学家研发
最炫的技术新知.最热门的大咖公开课.最有趣的开发者活动.最实用的工具干货,就在<开发者必读>! 每日集成开发者社区精品内容,你身边的技术资讯管家. 每日头条 阿里开源新一代 AI 算法模型 ...
- 搭乘“AI大数据”快车,肌肤管家,助力美业数字化发展
经过疫情的发酵,加速推动各行各业进入数据时代的步伐.美业,一个通过自身技术.产品让用户变美的行业,在AI大数据的加持下表现尤为突出. 对于美妆护肤企业来说,一边是进入存量市场,一边是疫后的复苏期,一边 ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
随机推荐
- uniapp去修改vuex中state中的值
修改state中的值 修改state中的值,方法 (1) 在mutations中写修改state的api. (2)写好之后,直接store.commit("changeValue" ...
- 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位)
九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) @ 目录 九. Redis 持久化-RDB(详细讲解说明,一个配置一个说明分析,步步讲解到位) 1. RDB 概述 ...
- WitAwards 2024荣耀登榜!AOne载誉而归!
近日,FCIS 2024网络安全创新大会在上海举办.本次大会以"迈向安全服务化时代"为主题,邀请来自全球的网安精英.技术专家.CISO/CSO.白帽子.创业者等展开深度对话,分享与 ...
- 俄罗斯方块-shell脚本写的,学习学习
#!/bin/bash APP_NAME="${0##*[\\/]}" APP_VERSION="1.0" #颜色定义 iSumColor=7 #颜色总数 cR ...
- 什么是Lambda架构?
一.简介 Lambda架构(Lambda Architecture)是由Twitter工程师南森·马茨(Nathan Marz)提出的大数据处理架构. 这一架构的提出基于马茨在BackType和Twi ...
- 同步一下在notion上写的内容
之前在notion上写了一些内容,但因为notion上的编辑器和博客园的不太一样,所以不好直接搬运过来,这里同步一下链接: 之前看MIT线性代数网课做的笔记:重温线性代数 算法课笔记之一:分而治之 算 ...
- JAVA基础环境配置指南(简洁版)
1.安装JDK 官网下载后直接安装 配置环境变量: 添加 JAVA_HOME 变量名:JAVA_HOME 变量值:C:\Program Files (x86)\Java\jdk1.8.0_91 // ...
- 这期没有 AI 开源项目「GitHub 热点速览」
最近 GitHub 上的 AI 开源项目扎堆,几乎到了"刷屏"的程度.所以这次我们换个口味,来看看那些非 AI.有趣的开源项目! Rust 不好学呀!尤其是所有权和生命周期这些概念 ...
- STM32的SYSTICK 定时器(系统滴答定时器)
什么是SysTick? 这是一个24位的系统节拍定时器system tick timer,SysTick,具有自动重载和溢出中断功能,所有基于Cortex_M3处理器的微控制器都可以由这个定时器获得一 ...
- 【Unity】URP中的UGUIShader实现
[Unity]URP 中的 UGUIShader 实现 参考官方 Shader 代码实现: https://github.com/TwoTailsGames/Unity-Built-in-Shader ...