RAG三件套运行的新选择 - GPUStack
GPUStack 是一个开源的大模型即服务平台,可以高效整合并利用 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种异构的 GPU/NPU 资源,提供本地私有部署大模型解决方案。
GPUStack 可以支持 RAG 系统中所需要的三种关键模型:Chat 对话模型(大语言模型)、Embedding 文本嵌入模型和 Rerank 重排序模型三件套,只需要非常简单的傻瓜化操作就能部署 RAG 系统所需要的本地私有模型。
下面介绍如何安装 GPUStack 和 Dify,并使用 Dify 来对接 GPUStack 部署的对话模型、Embedding 模型和 Reranker 模型。
安装 GPUStack
在 Linux 或 macOS 上通过以下命令在线安装,在安装过程中需要输入 sudo 密码:
curl -sfL https://get.gpustack.ai | sh -
如果环境连接不了 GitHub,无法下载一些二进制文件,使用以下命令安装,用 --tools-download-base-url 参数指定从腾讯云对象存储下载:
curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上以管理员身份运行 Powershell,通过以下命令在线安装:
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
如果环境连接不了 GitHub,无法下载一些二进制文件,使用以下命令安装,用 --tools-download-base-url 参数指定从腾讯云对象存储下载:
Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
接下来按照脚本输出的指引,拿到登录 GPUStack 的初始密码,执行以下命令:
在 Linux 或 macOS 上:
cat /var/lib/gpustack/initial_admin_password
在 Windows 上:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\initial_admin_password") -Raw
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。
重新设置密码后,进入 GPUStack:
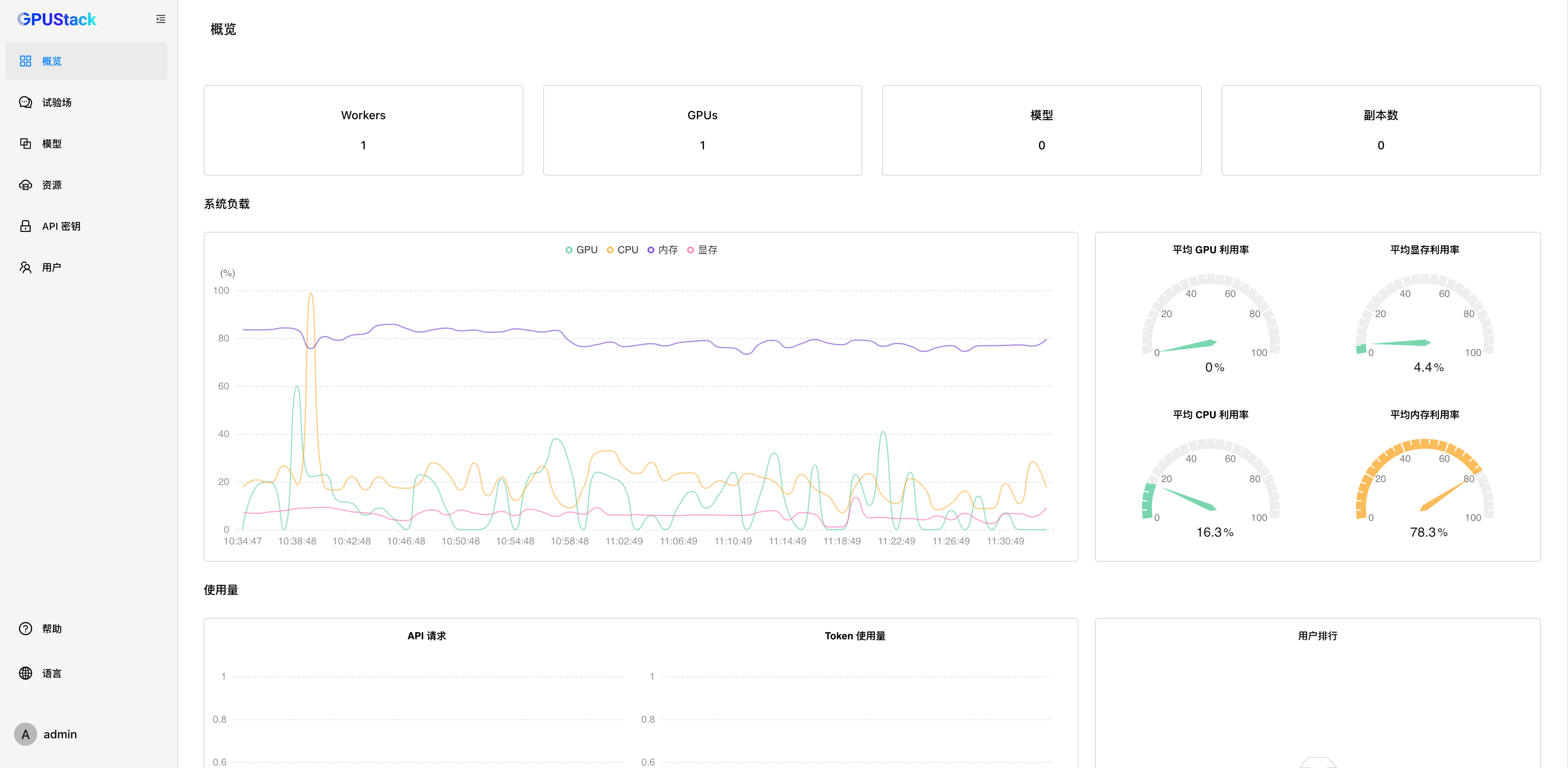
纳管 GPU 资源
GPUStack 支持纳管 Linux、Windows 和 macOS 设备的 GPU 资源,通过以下步骤来纳管这些 GPU 资源。
其他节点需要通过认证 Token 加入 GPUStack 集群,在 GPUStack Server 节点执行以下命令获取 Token:
在 Linux 或 macOS 上:
cat /var/lib/gpustack/token
在 Windows 上:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\token") -Raw
拿到 Token 后,在其他节点上运行以下命令添加 Worker 到 GPUStack,纳管这些节点的 GPU(将其中的 http://YOUR_IP_ADDRESS 替换为你的 GPUStack 访问地址,将 YOUR_TOKEN 替换为用于添加 Worker 的认证 Token):
在 Linux 或 macOS 上:
curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上:
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
通过以上步骤,我们已经创建了一个 GPUStack 环境并纳管了多个 GPU 节点,接下来可以使用这些 GPU 资源来部署私有大模型。
部署私有大模型
访问 GPUStack,在 Models 菜单中部署模型。GPUStack 支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型,国内网络建议从 ModelScope 部署。
GPUStack 支持 vLLM 和 llama-box 推理后端,vLLM 专门针对生产推理进行了优化,在并发和性能方面更能满足生产需求,但 vLLM 只支持 Linux 系统。llama-box 则是一个灵活、兼容多平台的推理引擎,是 llama.cpp 的优化版本,对性能和稳定性进行了针对性的优化,支持 Linux、Windows 和 macOS 系统,不止支持各种 GPU 环境,也支持在 CPU 环境运行大模型,更适合需要多平台兼容性的场景。
GPUStack 会在部署模型时自动根据模型文件的类型选择适当的推理后端,如果模型为 GGUF 格式,GPUStack 会使用 llama-box 作为后端运行模型服务,如果为非 GGUF 格式, GPUStack 会使用 vLLM 作为后端运行模型服务。
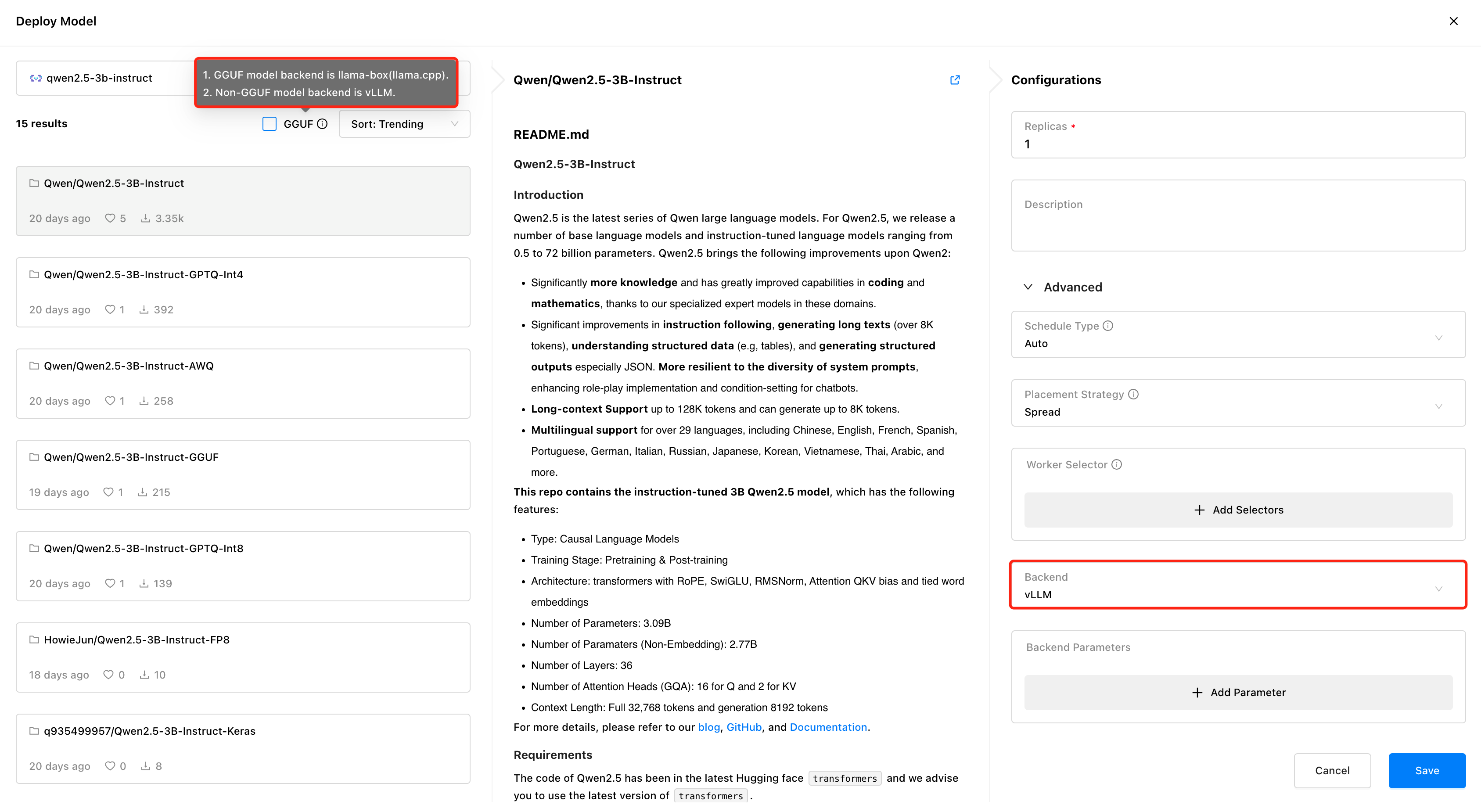
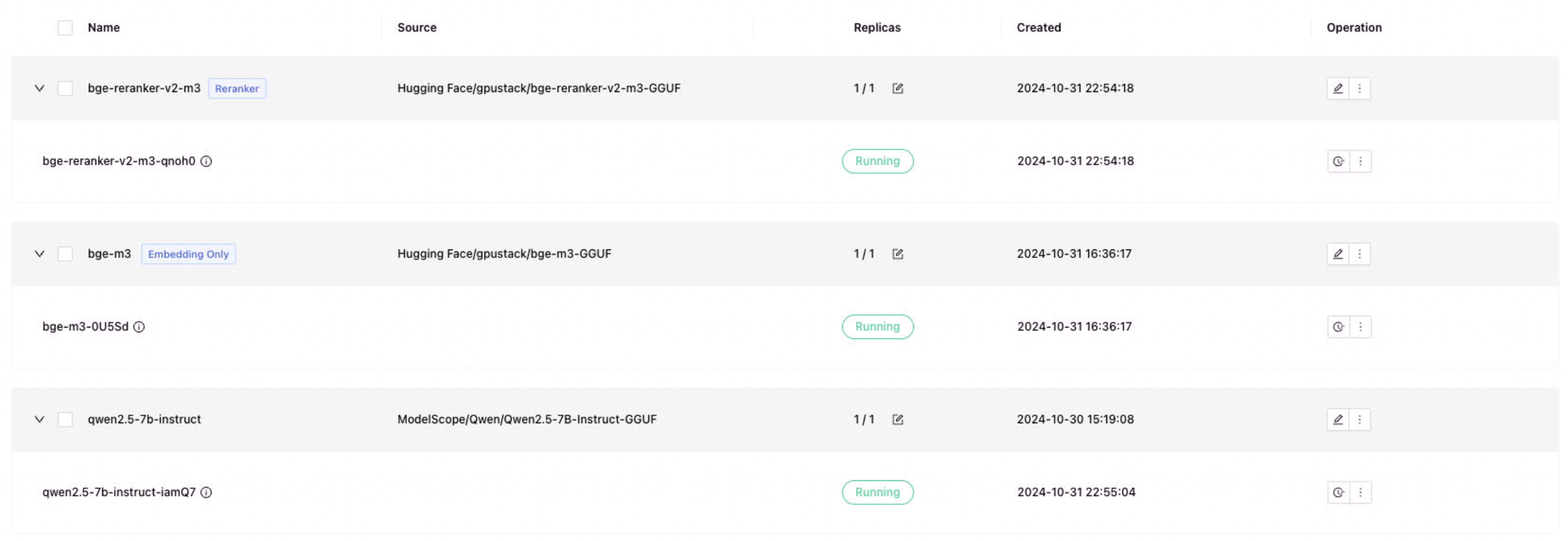
部署 Dify 对接所需要的文本对话模型、Embedding 文本嵌入模型、Reranker 模型,记得部署时勾选 GGUF 格式:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack 还支持 VLM 多模态模型,部署 VLM 多模态模型需要使用 vLLM 推理后端:
- Qwen2-VL-2B-Instruct

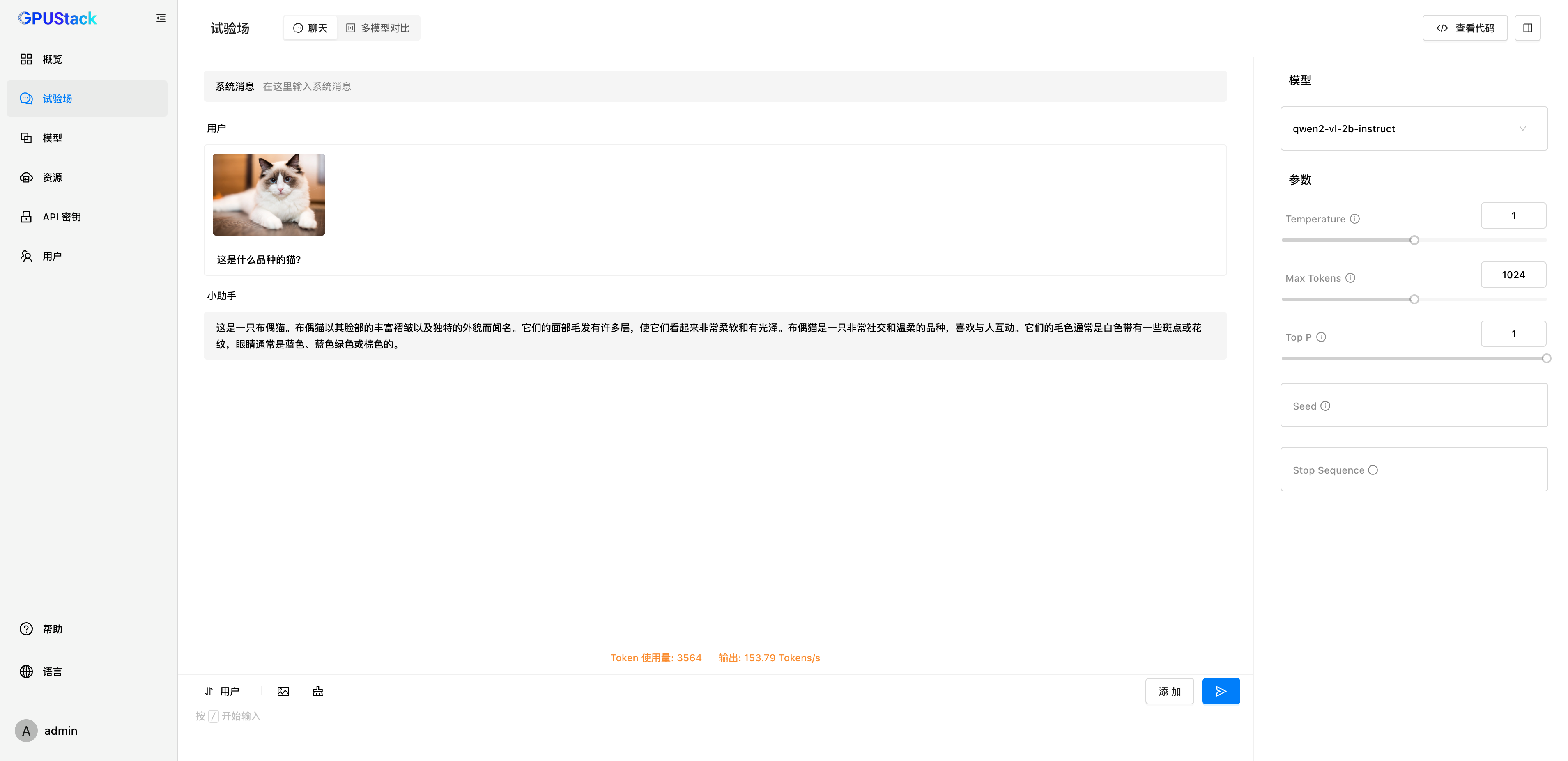
模型部署好后,RAG 系统或其他生成式 AI 应用可以通过 GPUStack 提供的 OpenAI / Jina 兼容 API 对接 GPUStack 部署的模型,接下来使用 Dify 来对接 GPUStack 部署的模型。
Dify 集成 GPUStack 模型
安装 Dify
采用 Docker 方式运行 Dify,需要准备好 Docker 环境,注意避免 Dify 和 GPUStack 的 80 端口冲突,使用其他主机或修改端口。执行以下命令安装 Dify:
git clone -b 0.11.1 https://github.com/langgenius/dify.git
cd dify/docker/
cp .env.example .env
docker compose up -d
访问 Dify 的 UI 界面 http://localhost,初始化管理员账户并登录。
集成 GPUStack 模型
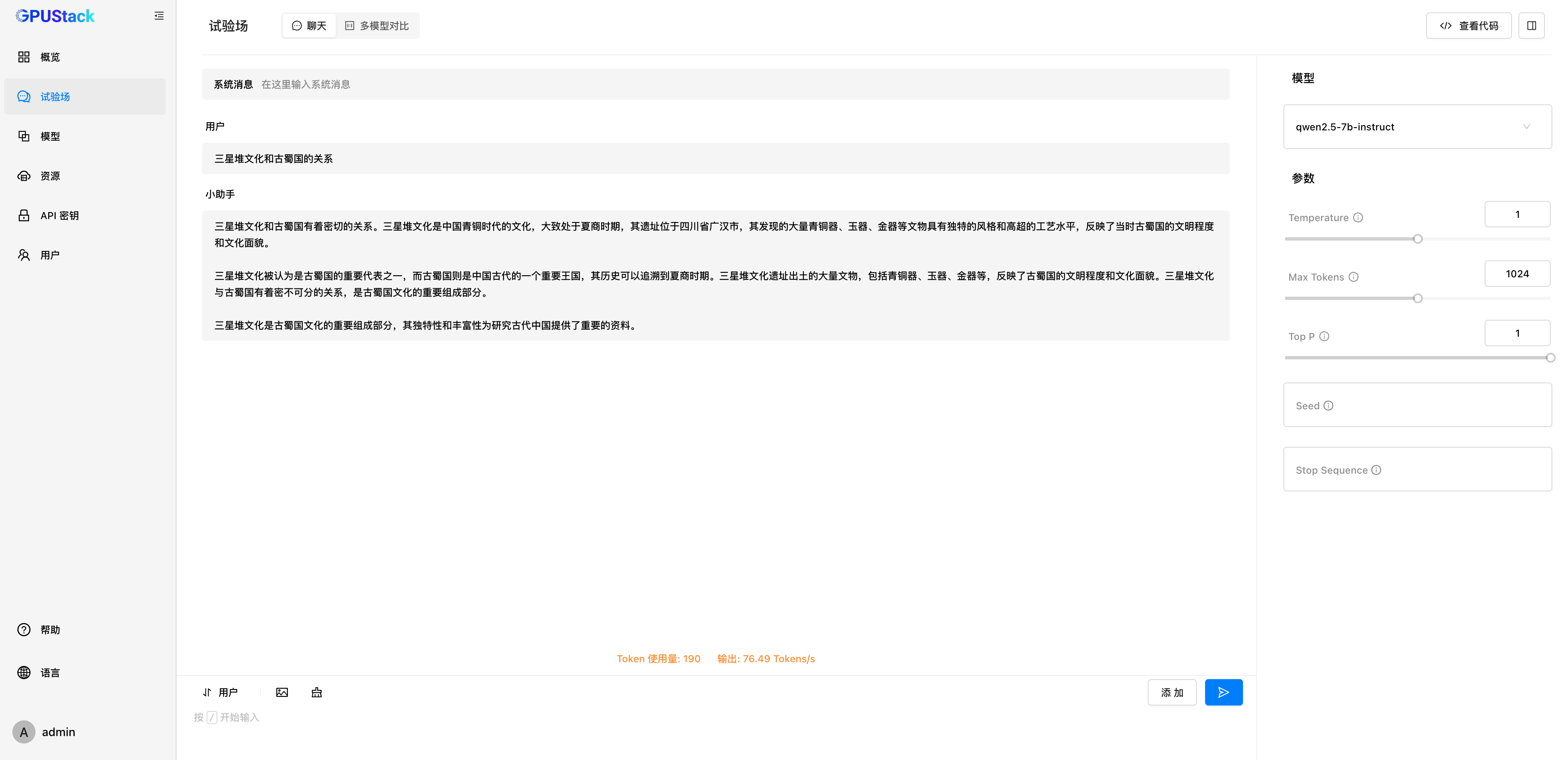
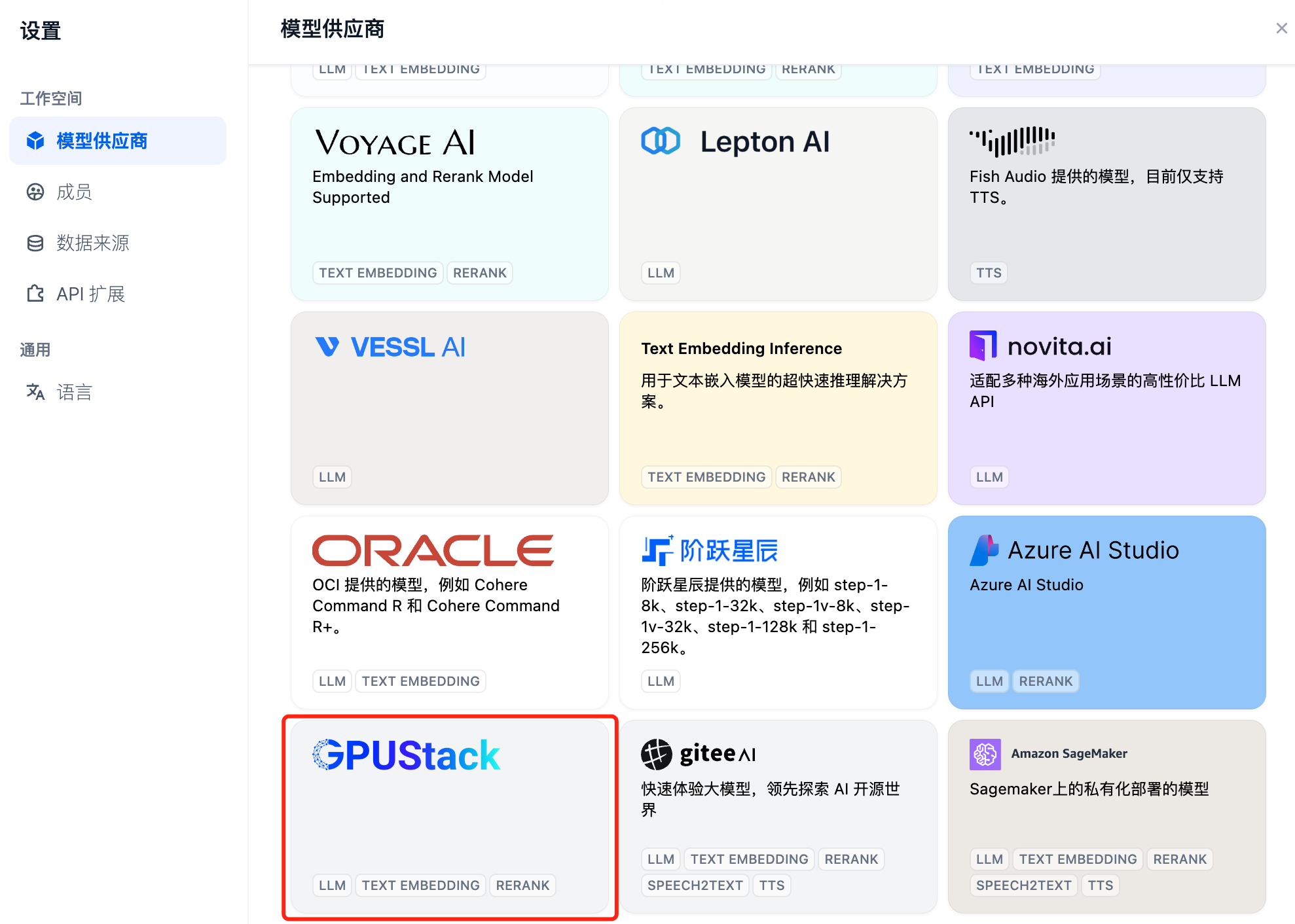
首先添加 Chat 对话模型,在 Dify 右上角选择“设置-模型供应商”,在列表中找到 GPUStack 类型,选择添加模型:
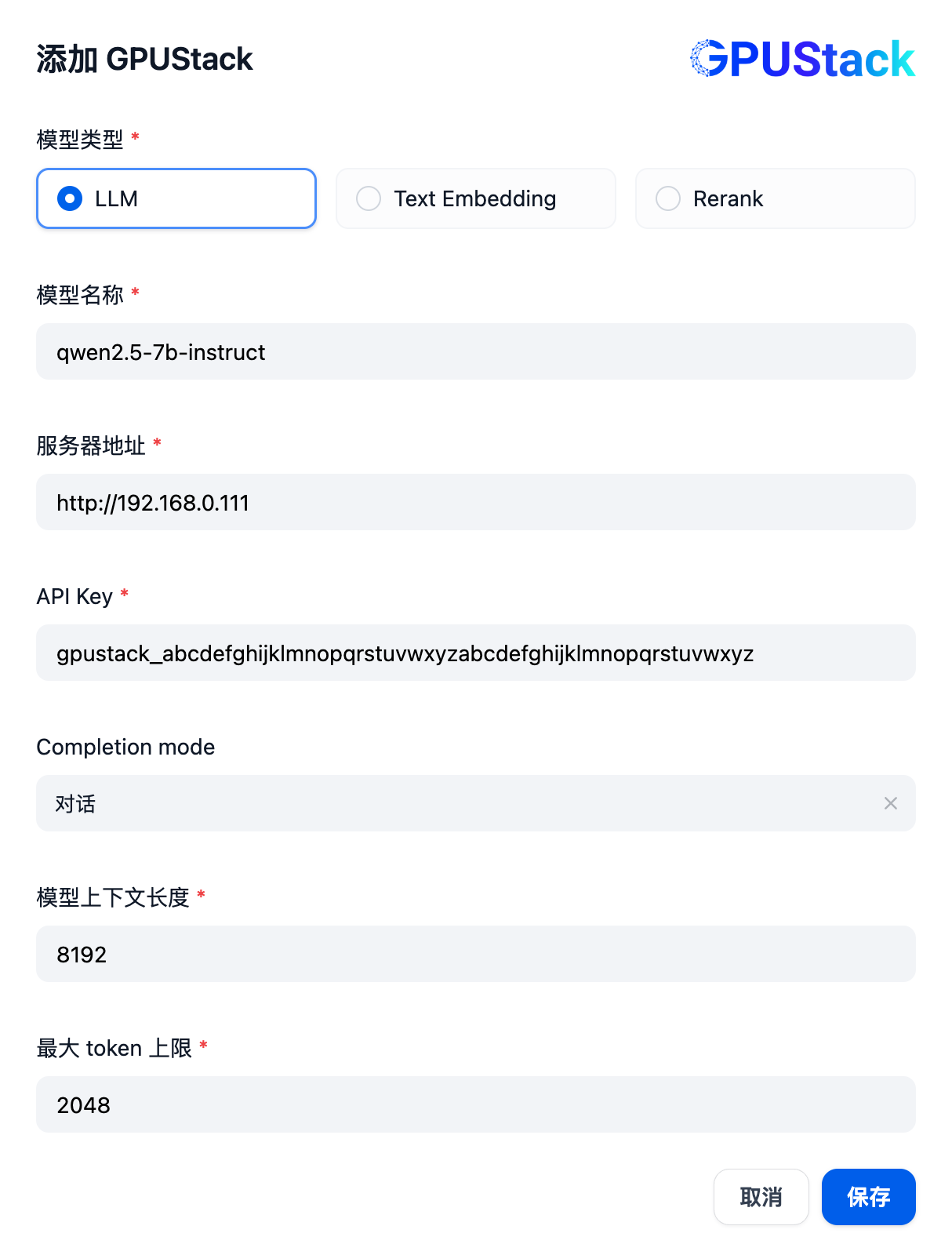
填写 GPUStack 上部署的 LLM 模型名称(例如 qwen2.5-7b-instruct)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192 和 max tokens 2048:
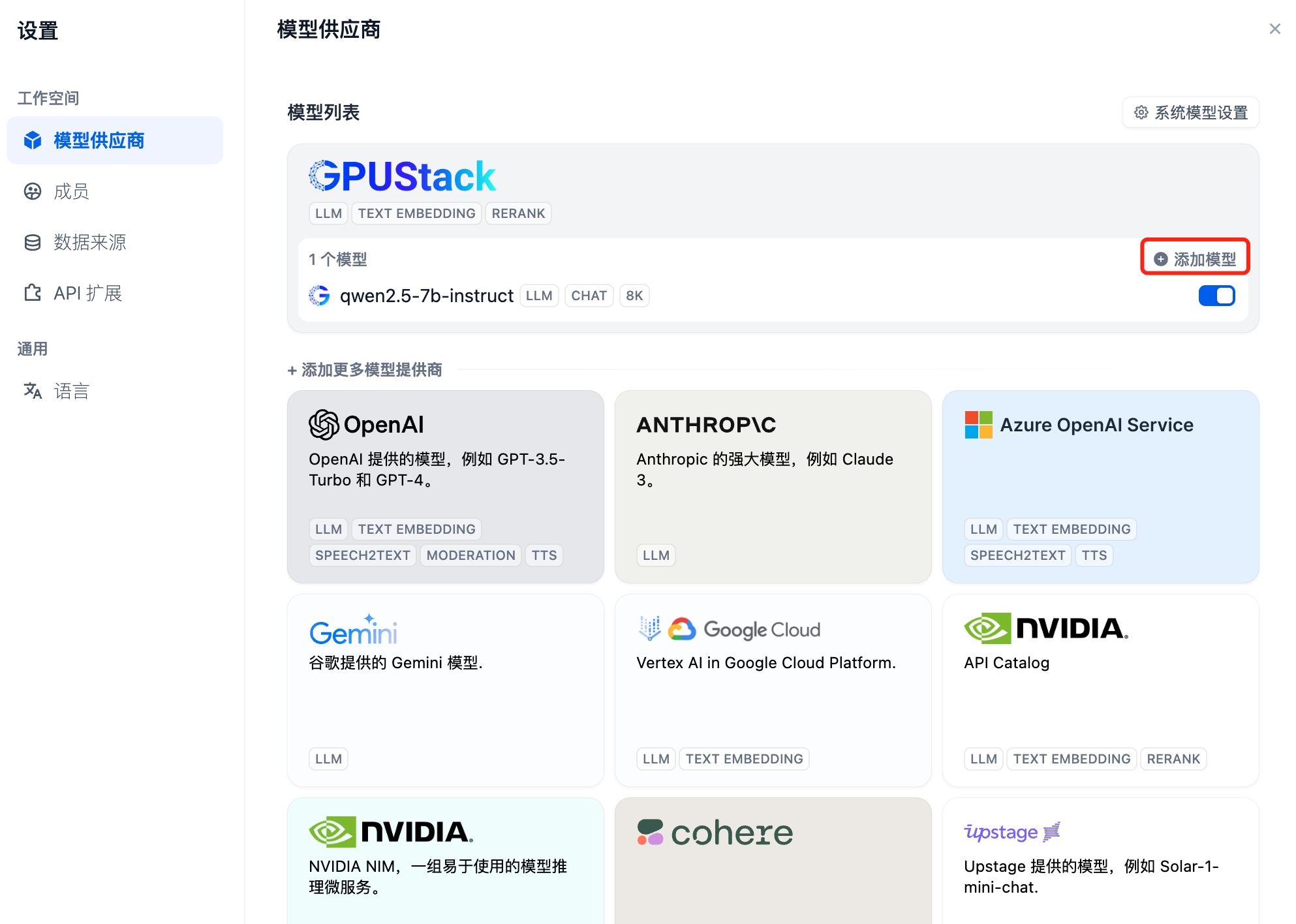
接下来添加 Embedding 模型,在模型供应商的最上方继续选择 GPUStack 类型,选择添加模型:
添加 Text Embedding 类型的模型,填写 GPUStack 上部署的 Embedding 模型名称(例如 bge-m3)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192:
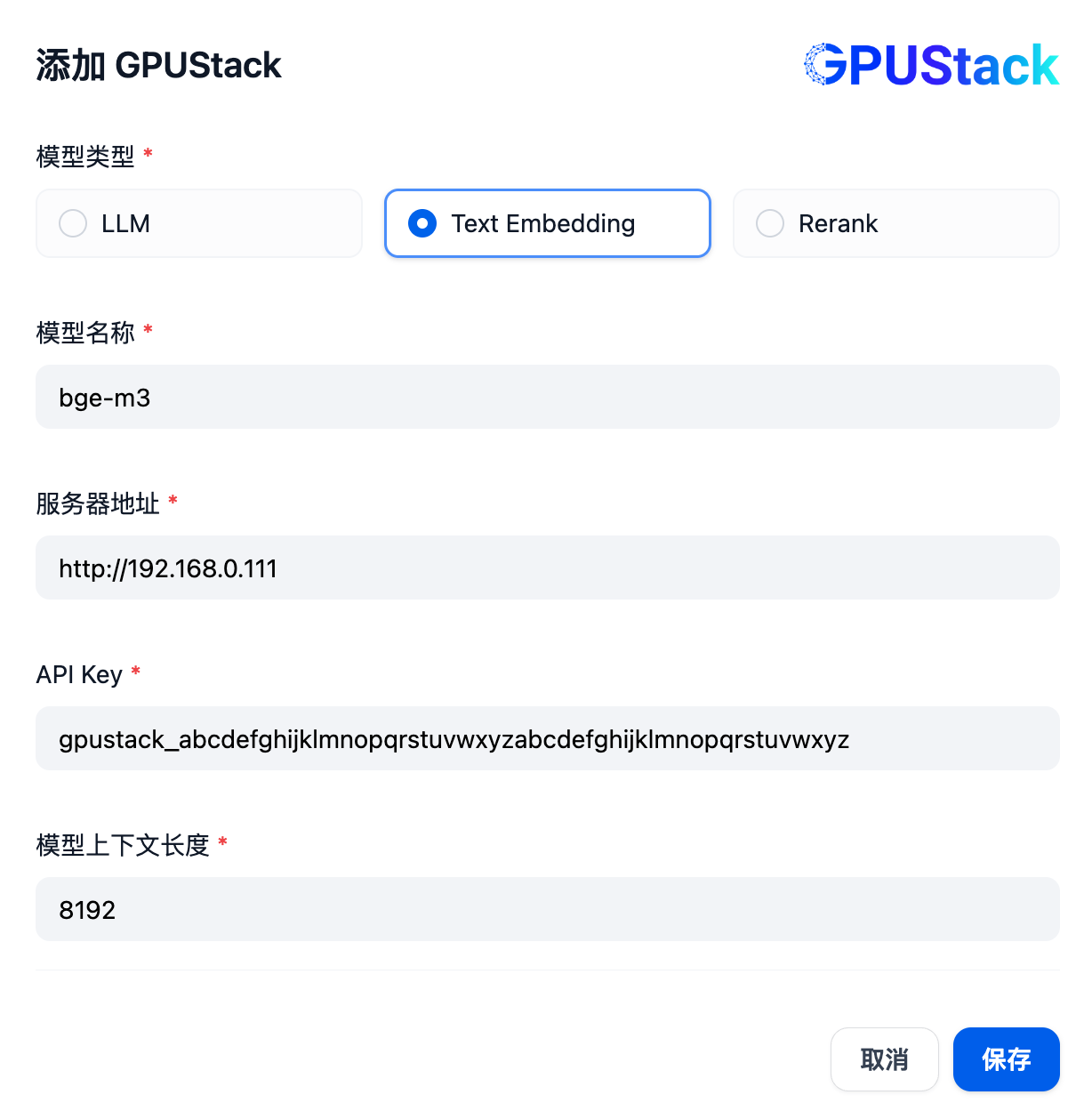
接下来添加 Rerank 模型,继续选择 GPUStack 类型,选择添加模型,添加 Rerank 类型的模型,填写 GPUStack 上部署的 Rerank 模型名称(例如 bge-reranker-v2-m3)、GPUStack 的访问地址(例如 http://192.168.0.111)和生成的 API Key,还有模型设置的上下文长度 8192:
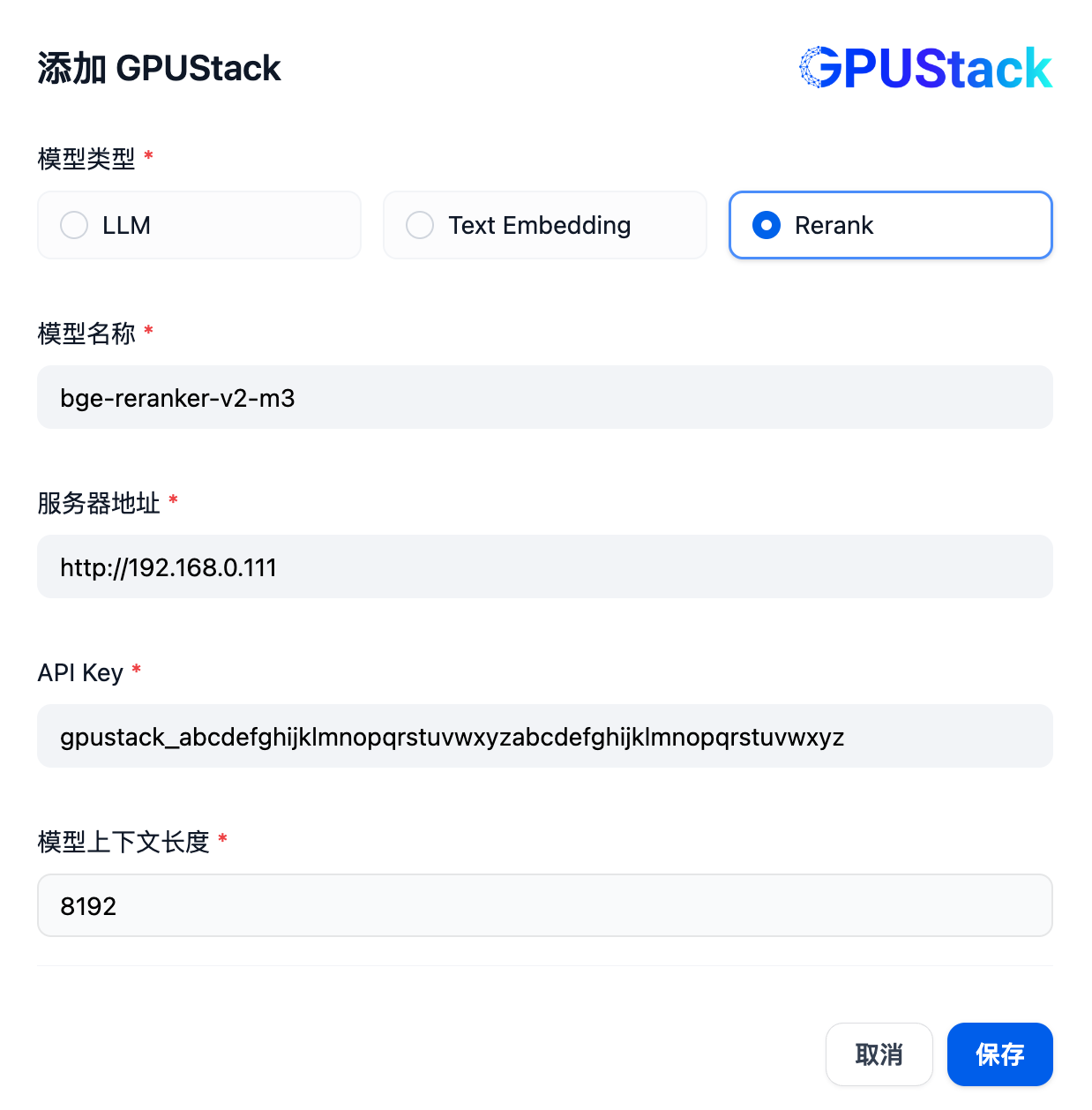
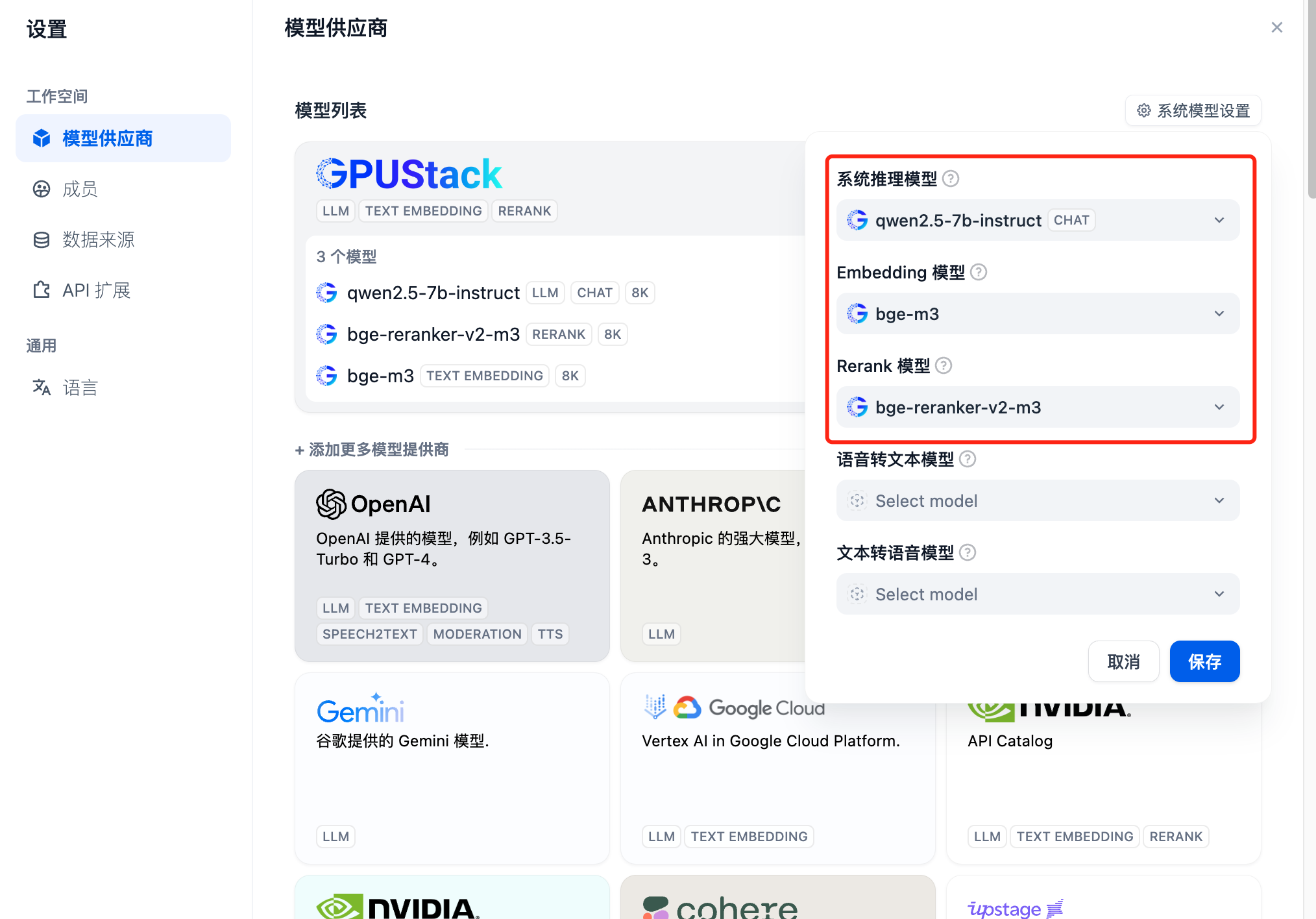
添加后重新刷新,然后在模型供应商确认系统模型配置为上面添加的三个模型:
在 RAG 系统使用模型
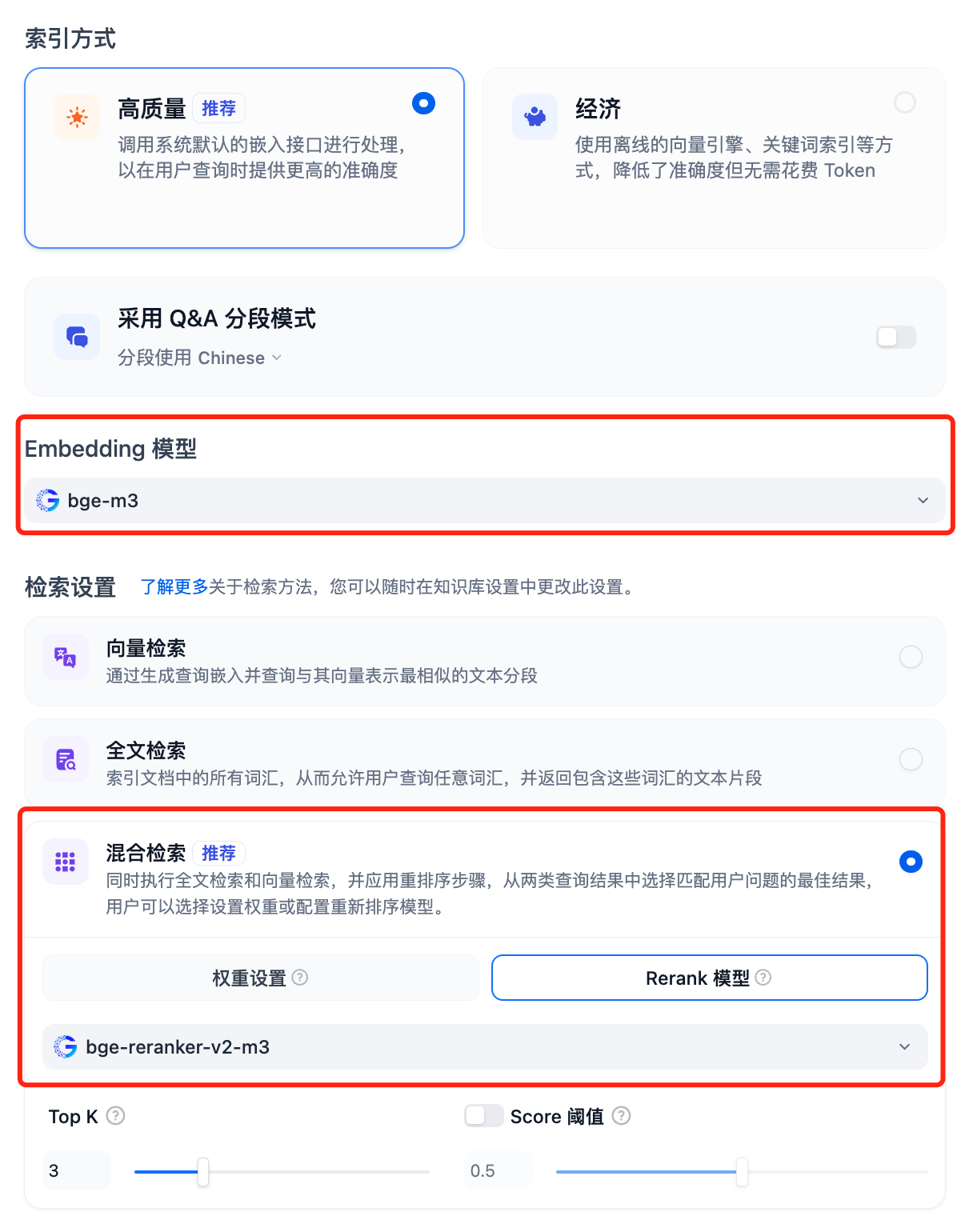
选择 Dfiy 的知识库,选择创建知识库,导入一个文本文件,确认 Embedding 模型选项,检索设置使用推荐的混合检索,并开启 Rerank 模型:
保存,开始将文档进行向量化过程,向量化完成后,知识库即可以使用了。

可以通过召回测试确认知识库的召回效果,Rerank 模型将进行精排以召回更有相关性的文档,以达到更好的召回效果:
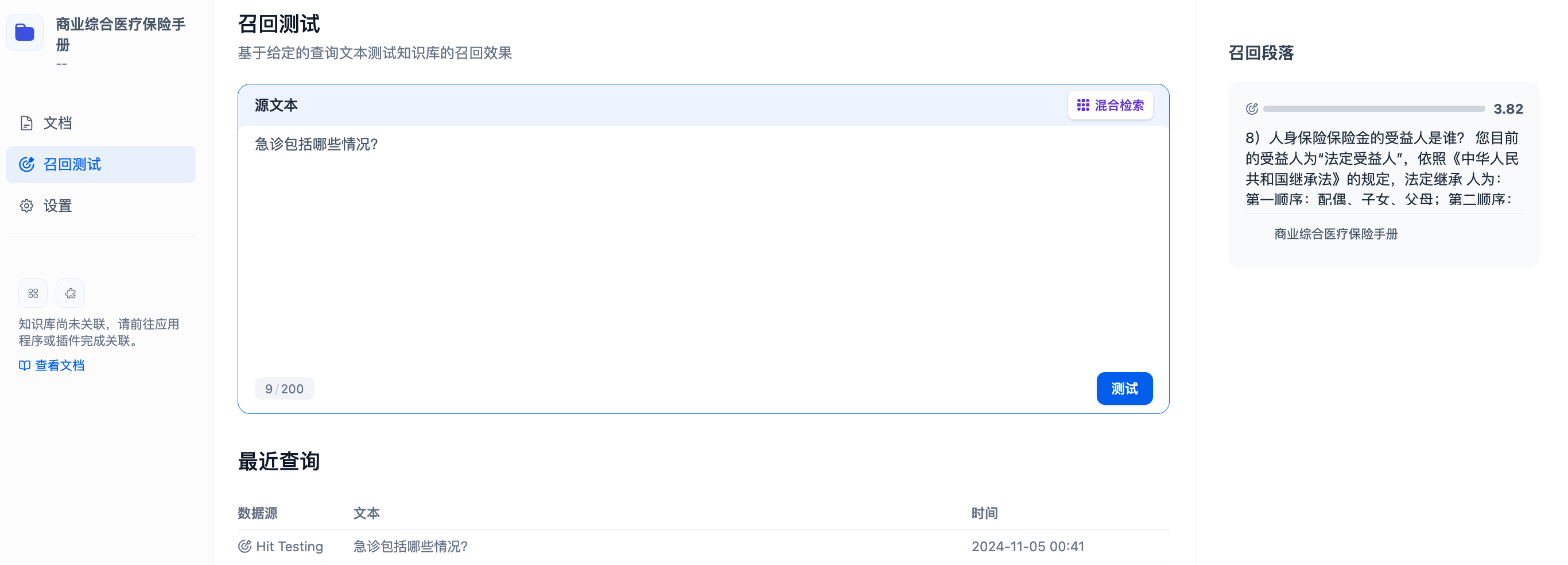
接下来在聊天室创建一个聊天助手应用:
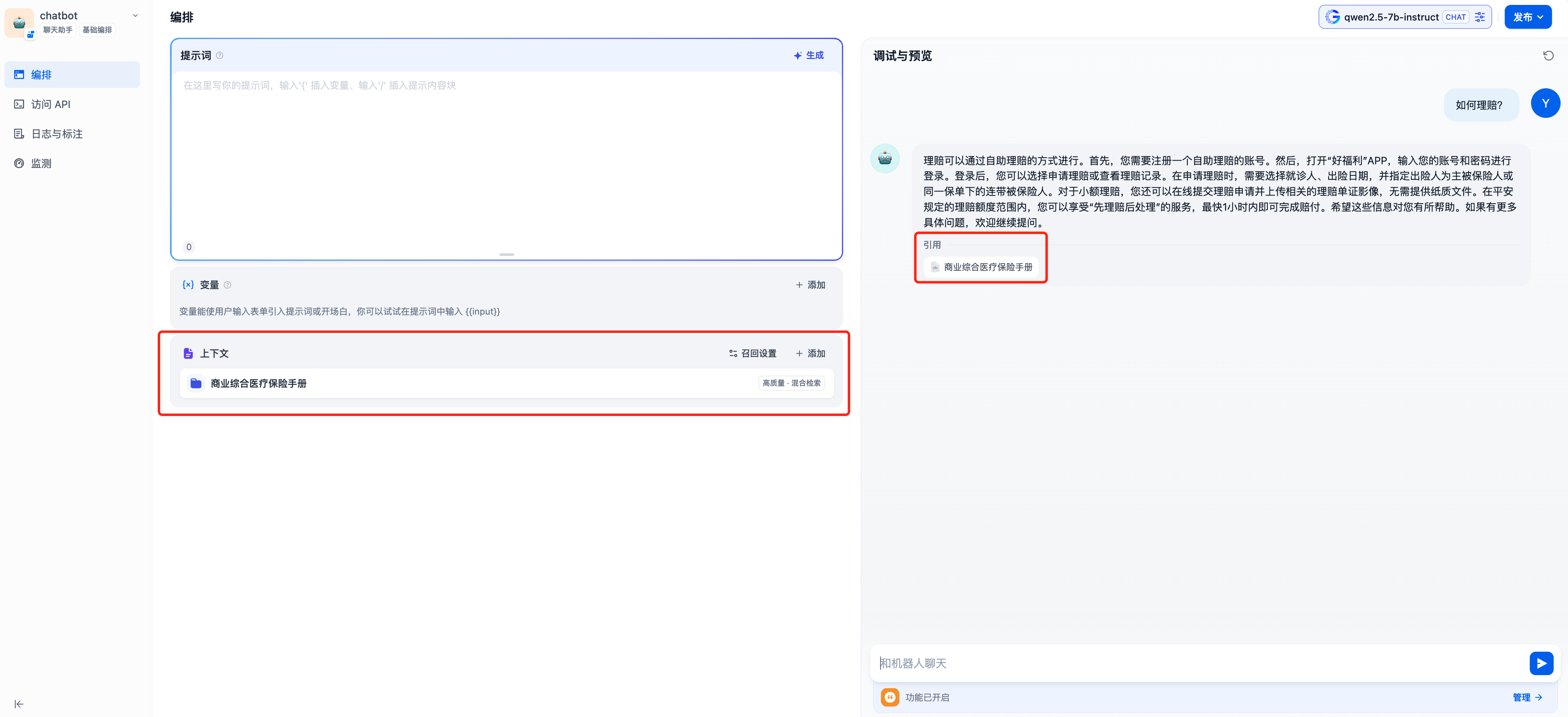
在上下文中添加相关知识库即可使用,此时 Chat 模型、Embedding 模型和 Reranker 模型将共同为 RAG 应用提供支撑,Embedding 模型负责向量化、 Reranker 模型负责对召回的内容进行精排,Chat 模型负责根据问题和召回的上下文内容进行回答:
以上为使用 Dify 对接 GPUStack 模型的示例,其他 RAG 系统也可以通过 OpenAI / Jina 兼容 API 对接 GPUStack,即可利用 GPUStack 平台部署的各种 Chat 模型、Embedding 模型和 Reranker 模型来支撑 RAG 系统。
以下为 GPUStack 功能的简单介绍。
GPUStack 功能介绍
异构 GPU 支持:支持异构 GPU 资源,当前支持 Nvidia、Apple Metal、华为昇腾和摩尔线程等各种类型的 GPU/NPU
多推理后端支持:支持 vLLM 和 llama-box (llama.cpp) 推理后端,兼顾生产性能需求与多平台兼容性需求
多平台支持:支持 Linux、Windows 和 macOS 平台,覆盖 amd64 和 arm64 架构
多模型类型支持:支持 LLM 文本模型、VLM 多模态模型、Embedding 文本嵌入模型 和 Reranker 重排序模型等各种类型的模型
多模型仓库支持:支持从 HuggingFace、Ollama Library、ModelScope 和私有模型仓库部署模型
丰富的自动/手动调度策略:支持紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等各种调度策略
分布式推理:如果单个 GPU 无法运行较大的模型,可以通过 GPUStack 的分布式推理功能,自动将模型运行在跨主机的多个 GPU 上
CPU 推理:如果没有 GPU 或 GPU 资源不足,GPUStack 可以用 CPU 资源来运行大模型,支持 GPU&CPU 混合推理和纯 CPU 推理两种 CPU 推理模式
多模型对比:GPUStack 在 Playground 中提供了多模型对比视图,可以同时对比多个模型的问答内容和性能数据,以评估不同模型、不同权重、不同 Prompt 参数、不同量化、不同 GPU、不同推理后端的模型 Serving 效果
GPU 和 LLM 观测指标:提供全面的性能、利用率、状态监控和使用数据指标,以评估 GPU 和 LLM 的利用情况
GPUStack 提供了建设一个私有大模型即服务平台所需要的各项企业级功能,作为一个开源项目,只需要非常简单的安装设置,就可以开箱即用地构建企业私有大模型即服务平台。
总结
以上为安装 GPUStack 和使用 Dify 集成 GPUStack 模型的配置教程,项目的开源地址为:https://github.com/gpustack/gpustack。
GPUStack 作为一个低门槛、易上手、开箱即用的开源平台,可以帮助企业快速整合和利用异构 GPU 资源,在短时间内快速搭建起一个企业级的私有大模型即服务平台。
对 GPUStack 感兴趣的或者在使用过程中遇到问题,可以添加 GPUStack 微信小助手(微信号:GPUStack)入群交流。
如果觉得写得不错,欢迎点赞、转发、关注。
RAG三件套运行的新选择 - GPUStack的更多相关文章
- 前端工程师的新选择WebApp
作为新一代移动端应用分发入口,小程序的趋势明朗化,竞争也在急剧激烈化.战线从手机 QQ.QQ 浏览器.支付宝.手机淘宝,华为,小米等九家手机厂商推出“快应用”,再拉到了谷歌的 Instant App ...
- servers中添加server时,看不到运行环境的选择。
servers中添加server时,看不到运行环境的选择. 主要原因是tomcat目录中的配置文件格式不对.
- Mego(03) - ORM框架的新选择
前言 从之前的两遍文章可以看出ORM的现状. Mego(01) - NET中主流ORM框架性能对比 Mego(02) - NET主流ORM框架分析 首先我们先谈下一个我们希望的ORM框架是什么样子的: ...
- 运行django新的项目,页面总是显示以前的项目,问题解决
运行django新的项目,页面总是显示以前的项目 只需打开任务管理器,再进程中关闭python.exe 再次重新启动服务,python manage.py runserver.即可
- 微信小程序,创业新选择
微信小程序,创业新选择 创业者们 总是站在时代的风口浪尖,他们踌躇满志无所畏惧,这大概就是梦想的力量.但是,如果没有把梦想拆解成没有可预期的目标和可执行的实现路径那么一切都只能叫做梦想. 小程序 张小 ...
- NOSQL—MongoDB之外的新选择
MongoDB之外的新选择 MongoDB拥有灵活的文档型数据结构和方便的操作语法,在新兴的互联网应用中得到了广泛的部署,但对于其底层的存储引擎一直未对外开放,虽说开源却有失完整.Mongo版本3中开 ...
- 破解“低代码”的4大误区,拥抱低门槛高效率的软件开发新选择 ZT
最近,每个人似乎都在谈论“低代码”.以美国的Outsystems.Kinvey,以及国内的活字格为代表的低代码开发平台,正在风靡整个IT世界.毕竟,能够以最少的编码快速开发应用的想法本身就很吸引人.但 ...
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- Laravel 从入门到精通 创建并运行一个新的 Laravel 项目
创建一个新的 Laravel 项目 正如官方文档所言,有两种方式可以创建一个新的 Laravel 项目,这两种创建方式都是从命令行执行的:第一种是通过全局的 Laravel 安装器,另一种是通过 Co ...
- Red5 1.0.0RC1 集成到tomcat6.0.35中运行&部署新的red5项目到tomcat中
1.下载red5-war-1.0-RC1.zip 解压之得到 ROOT.war 文件. 2.处理tomcat. 下载apache-tomcat-6.0.35-windows-x86.zip包,解压到你 ...
随机推荐
- Java——N以内累加求和
2024/07/15 1.题目 2.错误 3.分析 4.答案 1.题目 2.错误 import java.util.Scanner; public class Main { public static ...
- cnetos7.3离线安装vscode
1.从官网下载压缩包(话说下载下来解压就直接可以运行了咧,都不需要make) #下载vscode包 访问Visual Studio Code官网 https://code.visualstudio.c ...
- 几步轻松定制私人AI助手
这两年大模型的发展持续火热,以至于许多资本和学者认为AI出现了泡沫,根本原因还是因为大模型目前还没有出现能够结合行业切实落地的应用. 我才不关注泡沫不泡沫呢,我只关注大模型能给我带来哪些帮助即可.大模 ...
- 鸿蒙(HarmonyOS)实现隐私政策弹窗
在实现用户协议弹窗时,通常我们会想到使用系统自定义弹窗,并在弹窗中点击跳转到Web页面.但在HarmonyOS中,由于系统弹窗的显示优先级高于其他组件,即使跳转到Web页面,弹窗依然会显示在最上层. ...
- 使用Vue3.5的onWatcherCleanup封装自动cancel的fetch函数
前言 在欧阳的上一篇 这应该是全网最详细的Vue3.5版本解读文章中有不少同学对Vue3.5新增的onWatcherCleanup有点疑惑,这个新增的API好像和watch API回调的第三个参数on ...
- Qml 实现水波进度动画条
[写在前面] 最近看到一个非常有趣的动画效果:水波进度动画. 学习了一下实现思路,觉得很有意思. 不过原版是 HTML + CSS,我这里用的是 Qml,有一些小技巧,分享给大家~ [正文开始] 老样 ...
- Java获取Object中Value的方法
在Java中,获取对象(Object)中的值通常依赖于对象的类型以及我们希望访问的属性.由于Java是一种静态类型语言,直接从一个Object类型中访问属性是不可能的,因为Object是所有类的超类, ...
- C++ STL set/multiset容器
set/multiset容器 简介 Set的特性是,所有元素都会根据元素的值自动被排序.Set不允许两个元素有相同的值. Set的迭代器iterator是一种const_iterator,不能通过迭代 ...
- 以太坊Rollup方案之 arbitrum(2)
上一期简单介绍了一下rollup的一些基本内容以及aritrun交易的执行流程,这一期将介绍一下aritrum的核心技术 -- 交互式单步证明 这一期主要涉及到的是arbitrum的验证节点 arbi ...
- RDK X5首发上手体验!真的太帅啦!!!
RDK X5首发上手体验!真的太帅啦!!! 本Blog同步发表于: 地瓜机器人开发者论坛: CSDN: 一年多以前无意中了解到了RDK X3,之后我便迅速的被地平线机器人开发者论坛(现在改名为了地瓜机 ...