【学习笔记】RNN算法的pytorch实现
一些新理解
之前我有个疑惑,RNN的网络窗口,换句话说不也算是一个卷积核嘛?那所有的网络模型其实不都是一个东西吗?今天又听了一遍RNN,发现自己大错特错,还是没有学明白阿。因为RNN的窗口所包含的那一系列带有时间序列的数据,他们再窗口内是相互影响的,这也正是RNN的核心,而不是像卷积那样直接选个最大值,RNN会引入新的参数以保证每个时刻的值都能参与进去,影响最终结果。而且这里的窗口大小,实质上是指你循环网络的层数
构造RNN
- 方式一:做自己的RNN cell,自己写处理序列的循环
- 方式二:直接使用RNN
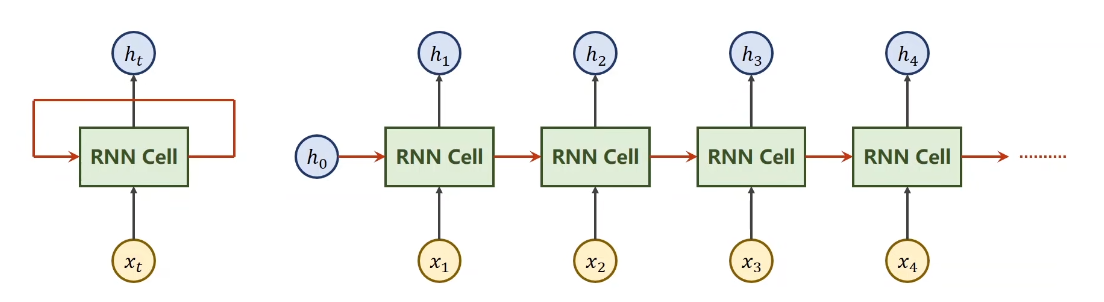
RNN cell
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
input_size这个是你输入的维度,hidden_size这个是你隐藏层的维度,只有你有了这两个值,你才能把权重和偏置的维度都确定下来
所以调用的时候不仅要给当前时刻的输入,再加上当前的hidden
hidden = cell(inpput, hidden)
比如input是x1,hidden是h0,经过cell后就算出了h1,这里有一个点很关键,就是这个input的维度和hidden的维度
input的维度包括batch和input_size,由于我们是批量输入x,所以应该是输入nx,因此batch是n,input_size就是x,而隐层的batch应该就是x乘以隐层的维度,输出维度也是相同
举例,代码和解释注释如下
import torch
batch_size = 1 # 数据量
seq_len = 3 # 序列的个数与
input_size = 4 # 输入数据的维度
hidden_size = 2 # 隐层维度
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size) # 确定cell维度
dataset = torch.rand(seq_len, batch_size, input_size) # 随便设置下数据集
hidden = torch.zeros(batch_size, hidden_size) #随便设置下隐层数据权重
for idx, input in enumerate(dataset):
print('='*20, idx, '='*20)
print('input size:', input.shape)
hidden = cell(input, hidden) //RNN计算
print('outputs size:', hidden.shape)
print(hidden)
直接使用RNN
cell = torch.nn.RNN(input_size=input_size,hidden_szie=hidden_size, num_layers=num_layers) ##num_layers代表RNN层数
out, hidden = cell(inputs, hidden) # inputs就是输入序列,hn给到out,所有的h序列给到hidden
这里输入维度要求有序列长度,batch,input_size,而隐层维度则多了一个numplayers,因为要考虑网络的层数
而输出的维度变成seqlen,batch和hidden_size,
代码如下
import torch
batch_size = 1
seq_len = 3
input_size = 4
hidden_size = 2
num_layers = 1
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
inputs = torch.randn(seq_len, batch_size, input_size)
hidden = torch.zeros(num_layers, batch_size, hidden_size)
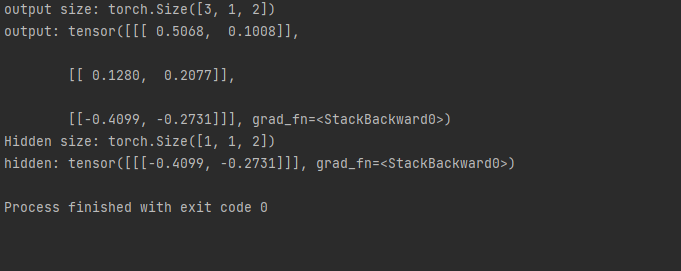
out, hidden = cell(inputs, hidden)
print('output size:', out.shape)
print('output:', out)
print('Hidden size:', hidden.shape)
print('hidden:', hidden)
这里就不同写循环了
其他参数batch_first:如果设置为Ture,就代表要把序列长度和样本数量维度进行交换
然后视频又介绍了如何使用词嵌入,写法如下
import torch
input_size = 4
hidden_size = 8
batch_size = 1
seq_len = 5
embedding_size = 3
num_class = 4
num_layers = 2
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [0, 0, 0, 0, 2]
inputs = torch.LongTensor(x_data).view(batch_size, seq_len)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('predicted :',''.join([idx2char[x] for x in idx]), end='')
print(',EPOCH[%d/100] loss=%.4f'% (epoch+1, loss.item()))
【学习笔记】RNN算法的pytorch实现的更多相关文章
- [ML学习笔记] XGBoost算法
[ML学习笔记] XGBoost算法 回归树 决策树可用于分类和回归,分类的结果是离散值(类别),回归的结果是连续值(数值),但本质都是特征(feature)到结果/标签(label)之间的映射. 这 ...
- 学习笔记 - Manacher算法
Manacher算法 - 学习笔记 是从最近Codeforces的一场比赛了解到这个算法的~ 非常新奇,毕竟是第一次听说 \(O(n)\) 的回文串算法 我在 vjudge 上开了一个[练习],有兴趣 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 学习笔记-KMP算法
按照学习计划和TimeMachine学长的推荐,学习了一下KMP算法. 昨晚晚自习下课前粗略的看了看,发现根本理解不了高端的next数组啊有木有,不过好在在今天系统的学习了之后感觉是有很大提升的了,起 ...
- Java学习笔记——排序算法之快速排序
会当凌绝顶,一览众山小. --望岳 如果说有哪个排序算法不能不会,那就是快速排序(Quick Sort)了 快速排序简单而高效,是最适合学习的进阶排序算法. 直接上代码: public class Q ...
- PyTorch学习笔记6--案例2:PyTorch神经网络(MNIST CNN)
上一节中,我们使用autograd的包来定义模型并求导.本节中,我们将使用torch.nn包来构建神经网络. 一个nn.Module包含各个层和一个forward(input)方法,该方法返回outp ...
- Java学习笔记——排序算法之进阶排序(堆排序与分治并归排序)
春蚕到死丝方尽,蜡炬成灰泪始干 --无题 这里介绍两个比较难的算法: 1.堆排序 2.分治并归排序 先说堆. 这里请大家先自行了解完全二叉树的数据结构. 堆是完全二叉树.大顶堆是在堆中,任意双亲值都大 ...
- Java学习笔记——排序算法之希尔排序(Shell Sort)
落日楼头,断鸿声里,江南游子.把吴钩看了,栏杆拍遍,无人会,登临意. --水龙吟·登建康赏心亭 希尔算法是希尔(D.L.Shell)于1959年提出的一种排序算法.是第一个时间复杂度突破O(n²)的算 ...
随机推荐
- (一)Linux环境的学习环境的搭建
我们使用VMWARE来安装Debian11系统来进行我们的LINUX学习 Debian虚拟机的安装 vmware-tools的安装 xShell的安装使用 samba的配置 gcc环境的配置 Debi ...
- 《Stepwise Metric Promotion for Unsupervised Video Person Re-identification》 ICCV 2017
Motivation: 这是ICCV 17年做无监督视频ReID的一篇文章.这篇文章简单来说基于两个Motivation. 在不同地方或者同一地方间隔较长时间得到的tracklet往往包含的人物是不同 ...
- Session会话 Cookie JSTL标签
Cookie 1) HTTP是无状态协议(连接结束后就自动断开),服务器不能记录浏览器的访问状态,也就是说服务器不能区分中两次请求是否由一个客户端发出.这样的设计严重阻碍的Web程序的设计.如:在我 ...
- labview从入门到出家9(进阶篇)--串口通讯
Labview在工控领域,如产线,实验室等环境用得较多,其中与仪器通讯控制的方式有串口(RS232,RS485,TTL),GPIB,网口,CAN等,其中串口在仪器还有单片机控制中用来调试居多.(很 ...
- 服务器配置IP
1.服务器系统一般有两个或多个网卡.在企业中一般给服务器网卡配一个可连外网的IP,如172.16.20.22 255.255.255.0 172.16.20.1 方便联网下载安装部分软件,若没有VPN ...
- Redis系列5:深入分析Cluster 集群模式
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) 1 背景 前面我们 ...
- Visual Studio Code 中文设置教程
本文仅供学习交流使用,如侵立删!demo下载见文末 Pycharm中文设置教程 1.首先打开VisualStudioCode,点击扩展:extensions. 2.搜索chinese. 3.选择需要的 ...
- 正则表达式实战:最新豆瓣top250爬虫超详细教程
检查网页源代码 首先让我们来检查豆瓣top250的源代码,一切网页爬虫都需要从这里开始.F12打开开发者模式,在元素(element)页面通过Ctrl+F直接搜索你想要爬取的内容,然后就可以开始编写正 ...
- Luogu3398 仓鼠找sugar (LCA)
第一发lg[]没开够RE了,下了数据本地一直停止运行,还以为是dfs死了,绝望一交,A了... 判断\(x\)是否在路径\(s-t\)上,只需满足 \(dep_{x} >= dep_{LCA(s ...
- 客户流失?来看看大厂如何基于spark+机器学习构建千万数据规模上的用户留存模型 ⛵
作者:韩信子@ShowMeAI 大数据技术 ◉ 技能提升系列:https://www.showmeai.tech/tutorials/84 行业名企应用系列:https://www.showmeai. ...