flink-cdc同步mysql数据到hbase
本文首发于我的个人博客网站 等待下一个秋-Flink
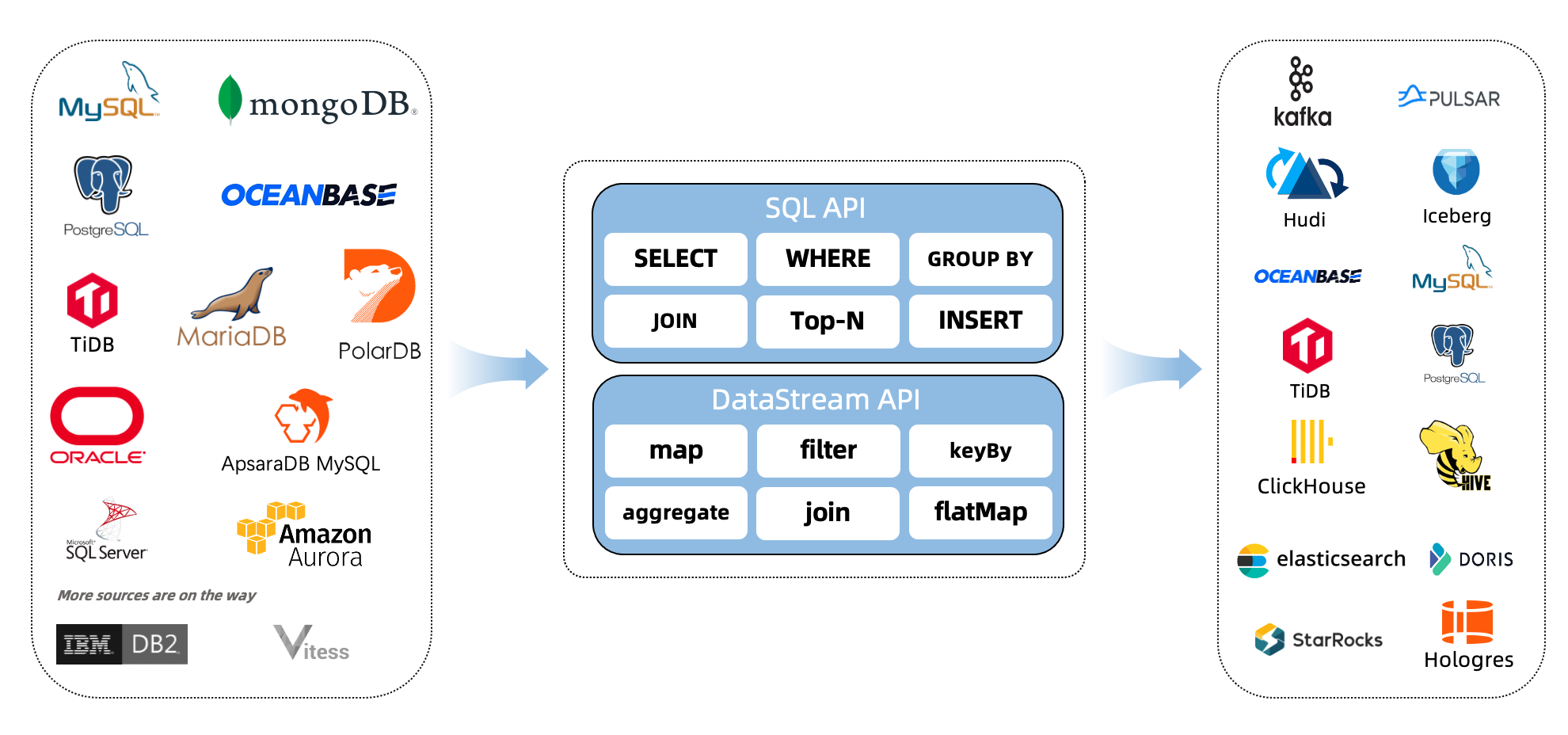
什么是CDC?
CDC是(Change Data Capture 变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的插入INSERT、更新UPDATE、删除DELETE等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
1. 环境准备
mysql
hbase
flink 1.13.5 on yarn
说明:如果没有安装hadoop,那么可以不用yarn,直接用flink standalone环境吧。
2. 下载下列依赖包
下面两个地址下载flink的依赖包,放在lib目录下面。
如果你的Flink是其它版本,可以来这里下载。
我是flink1.13,这里flink-sql-connector-mysql-cdc,需要1.4.0以上版本。
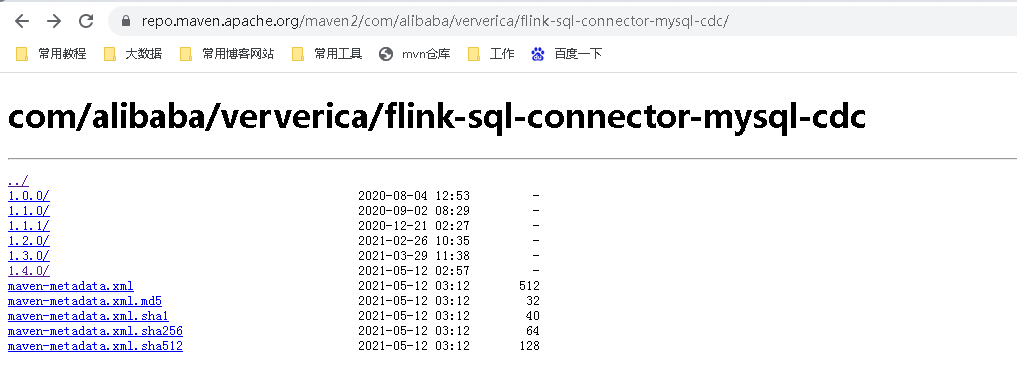
如果你是更高版本的flink,可以自行https://github.com/ververica/flink-cdc-connectors下载新版mvn clean install -DskipTests 自己编译。
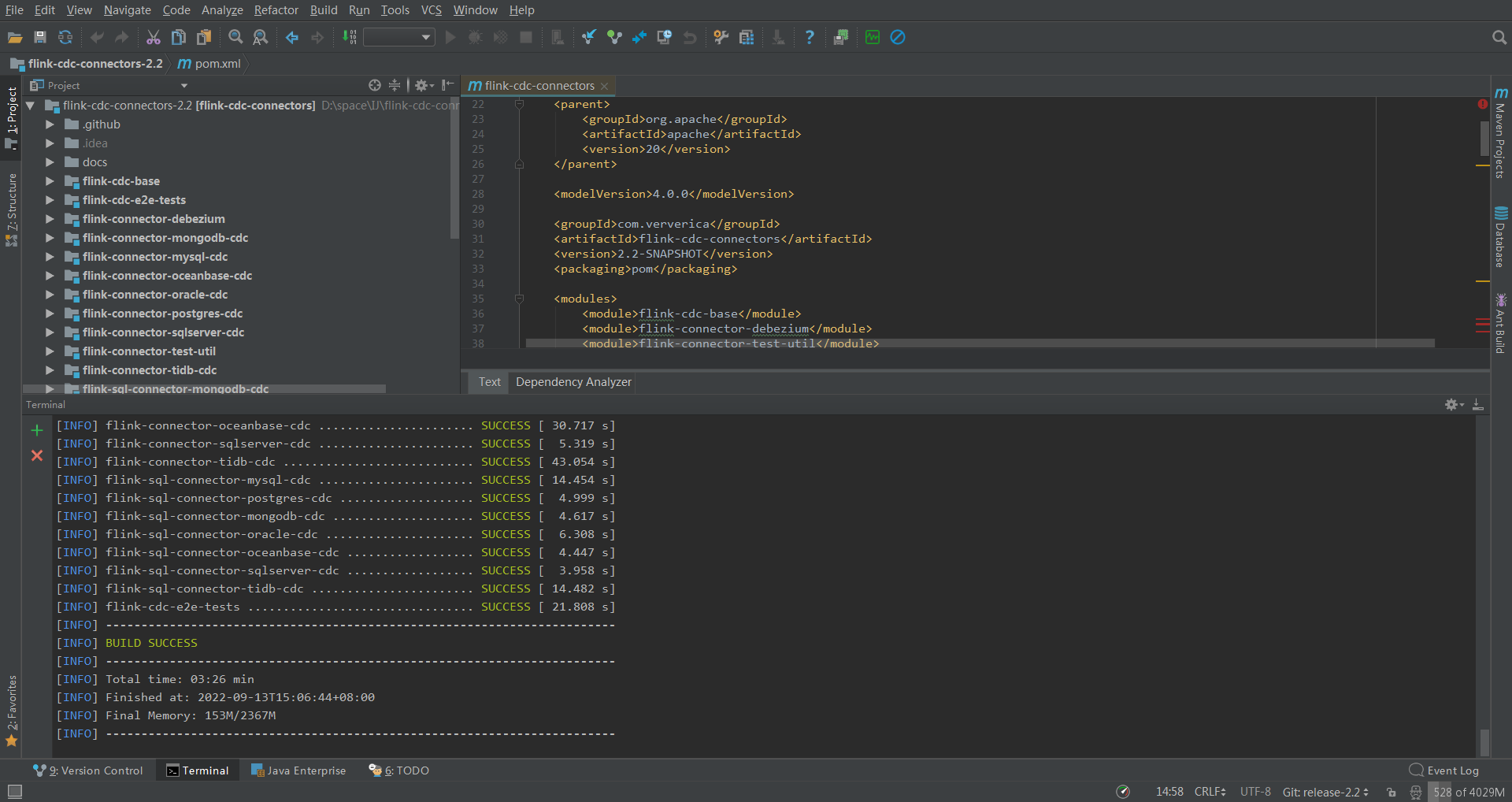
这是我编译的最新版2.2,传上去发现太新了,如果重新换个版本,我得去gitee下载源码,不然github速度太慢了,然后用IDEA编译打包,又得下载一堆依赖。我投降,我直接去网上下载了个1.4的直接用了。
我下载的jar包,放在flink的lib目录下面:
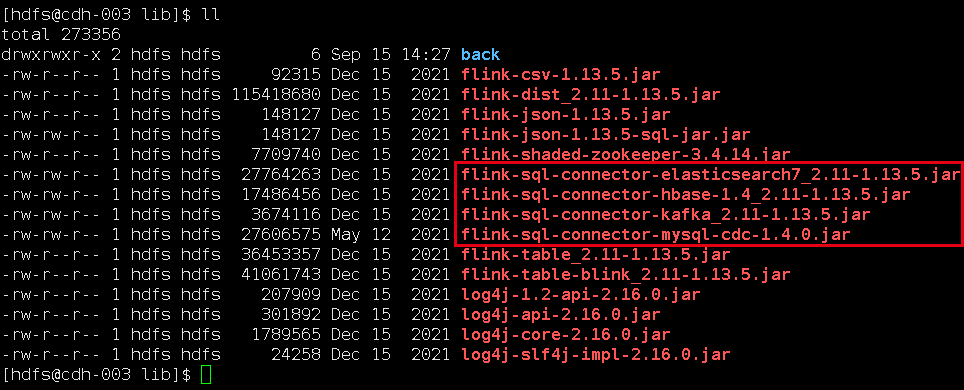
flink-sql-connector-hbase-1.4_2.11-1.13.5.jar
flink-sql-connector-mysql-cdc-1.4.0.jar
3. 启动flink-sql client
- 先在yarn上面启动一个application,进入flink13.5目录,执行:
bin/yarn-session.sh -d -s 2 -jm 1024 -tm 2048 -qu root.sparkstreaming -nm flink-cdc-hbase
- 进入flink sql命令行
bin/sql-client.sh embedded -s flink-cdc-hbase

4. 同步数据
这里有一张mysql表:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 样本数据
INSERT INTO `product_view` VALUES ('1', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('2', '1', '1', '1', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('3', '1', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('4', '1', '1', '2', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('5', '8', '1', '1', '120', '120', '2020-05-14 13:14:00');
INSERT INTO `product_view` VALUES ('6', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
INSERT INTO `product_view` VALUES ('7', '8', '1', '3', '120', '120', '2020-04-24 13:14:00');
INSERT INTO `product_view` VALUES ('8', '8', '1', '3', '120', '120', '2020-04-23 13:14:00');
INSERT INTO `product_view` VALUES ('9', '8', '1', '2', '120', '120', '2020-05-13 13:14:00');
- 创建数据表关联mysql
CREATE TABLE product_view_source (
`id` int,
`user_id` int,
`product_id` int,
`server_id` int,
`duration` int,
`times` string,
`time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.1.2',
'port' = '3306',
'username' = 'bigdata',
'password' = 'bigdata',
'database-name' = 'test',
'table-name' = 'product_view'
);
这样,我们在flink sql client操作这个表相当于操作mysql里面的对应表。
- 创建数据表关联hbase
CREATE TABLE product_view_hbase (
rowkey INT,
family1 ROW<user_id INT, product_id INT, server_id INT, duration INT>,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'product_view',
'zookeeper.quorum' = 'cdh-001:2181'
);
这里,需要提前在hbase里面创建好product_view这个主题。
- 同步数据

建立同步任务,可以使用sql如下:
insert into product_view_hbase select id as rowkey, ROW(user_id, product_id, server_id, duration) from product_view_source;
这个时候是可以退出flink sql-client的,然后进入flink web-ui,可以看到mysql表数据已经同步到hbase中了,对mysql进行插入,hbase都是同步更新的。
进入hbase shell,可以看到数据已经从mysql同步到hbase了:
hbase(main):009:0> scan 'product_view'
ROW COLUMN+CELL
\x00\x00\x00\x01 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x01 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x01 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x01 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x02 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x02 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x02 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x02 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x03 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x03 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x03 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x03
\x00\x00\x00\x03 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x04 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x04 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x04 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x02
\x00\x00\x00\x04 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x05 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x05 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x05 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x05 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x08
\x00\x00\x00\x06 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x06 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x06 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x02
\x00\x00\x00\x06 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x08
\x00\x00\x00\x07 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x07 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x07 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x03
\x00\x00\x00\x07 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x08
\x00\x00\x00\x09 column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x09 column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x09 column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x03
\x00\x00\x00\x09 column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x08
\x00\x00\x00\x0A column=family1:duration, timestamp=1663223736391, value=\x00\x00\x00x
\x00\x00\x00\x0A column=family1:product_id, timestamp=1663223736391, value=\x00\x00\x00\x01
\x00\x00\x00\x0A column=family1:server_id, timestamp=1663223736391, value=\x00\x00\x00\x02
\x00\x00\x00\x0A column=family1:user_id, timestamp=1663223736391, value=\x00\x00\x00\x08
9 row(s)
Took 0.1656 seconds
直接在flink-sql client里面查询hbase数据,也是可以的:
Flink SQL> select * from product_view_hbase ;
2022-09-15 15:38:23,205 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2022-09-15 15:38:23,207 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider [] - Failing over to rm72
2022-09-15 15:38:23,212 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface cdh-001:35225 of application 'application_1633924491541_7321'.
执行上面查询sql,就会进入界面,这就是hbase里面的数据了:
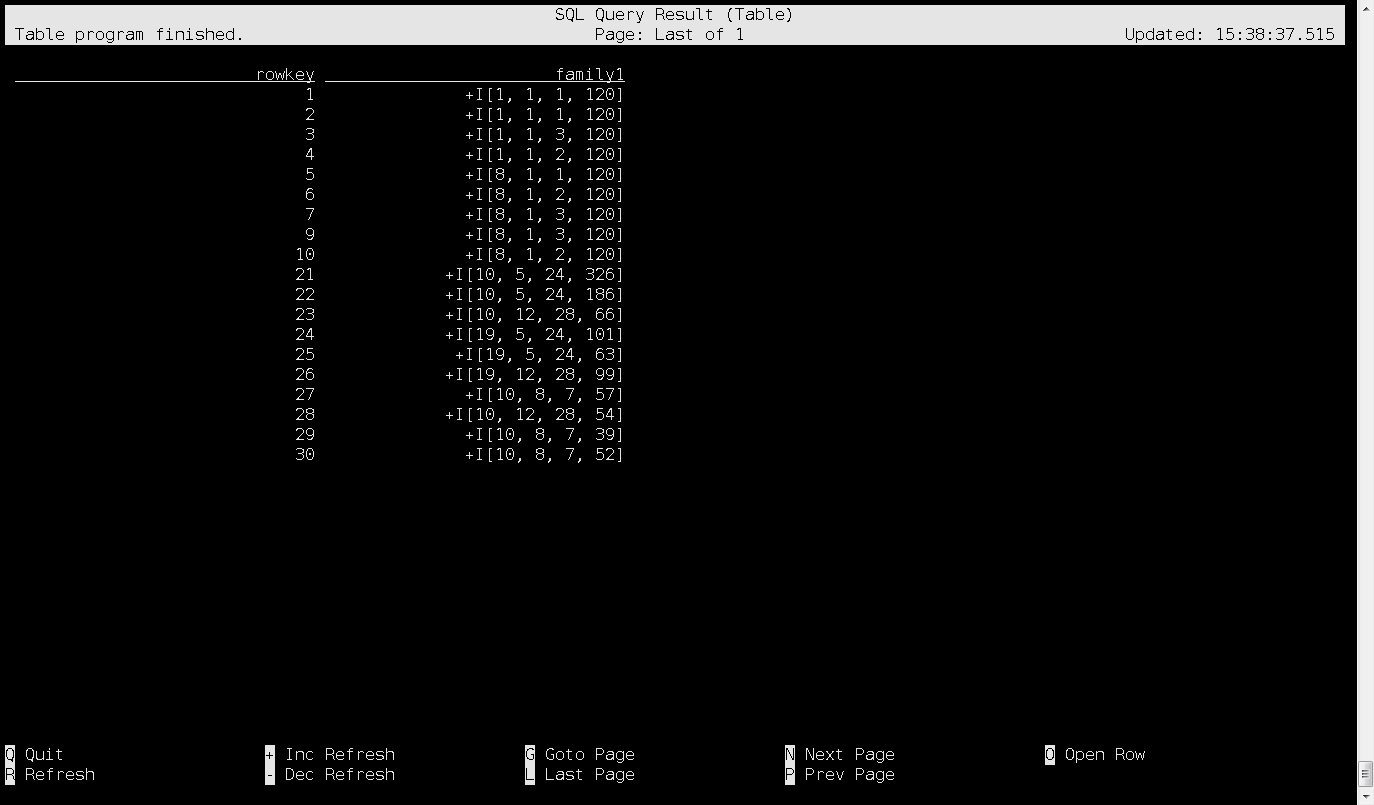
5. 关联查询
在这个flink-sql client环境中,这里有两张表:product_view_source(mysql的表)和product_view_hbase(hbase的表),后者是有前者查询导入的,这里为了简单,我没有再关联其它第三张表,就用这两张表,做关联查询,达到演示的目的。
select product_view_source.*, product_view_hbase.* from product_view_source
inner join product_view_hbase
on product_view_source.id = product_view_hbase.rowkey;
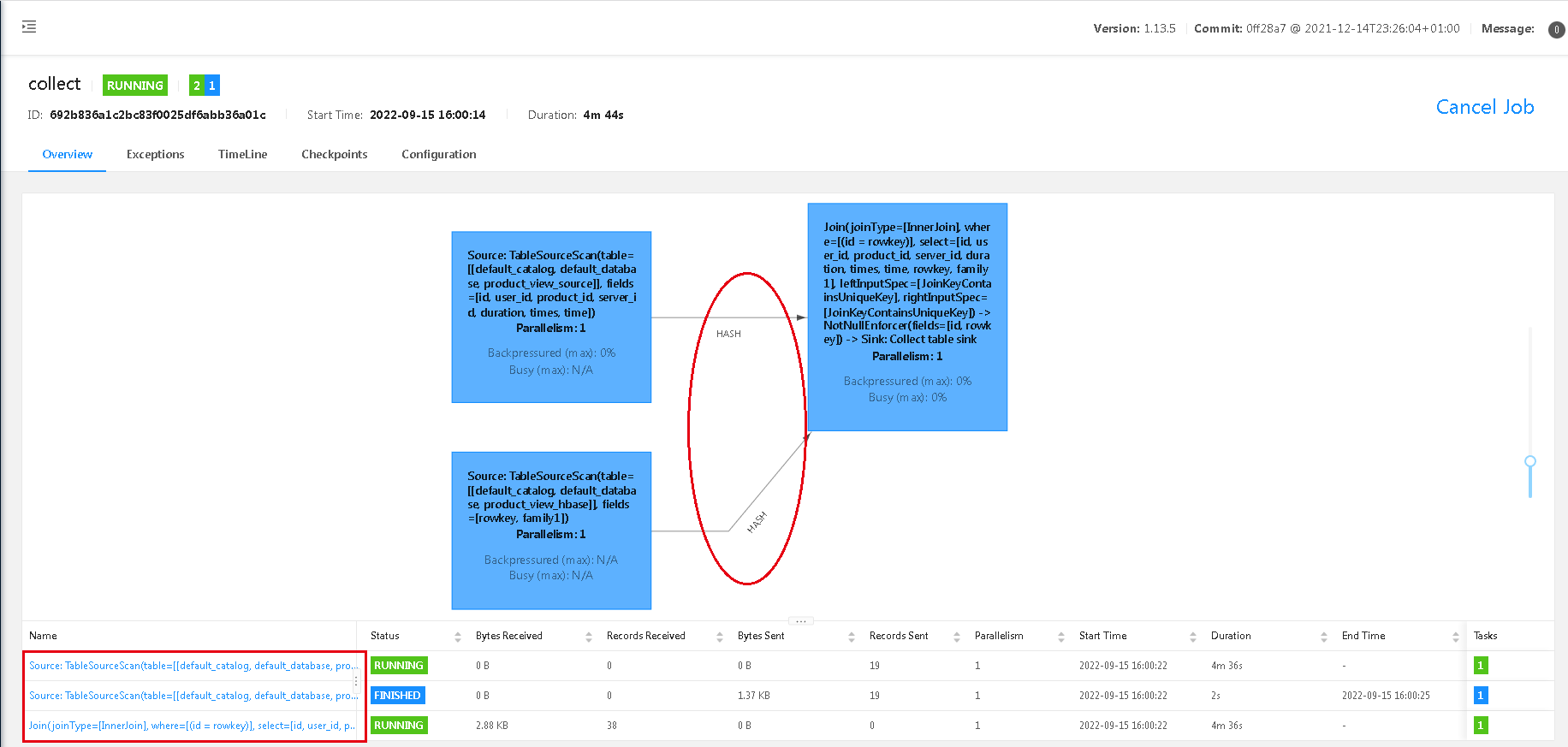
这里做了个简单的关联查询,通过id跟rowkey关联,然后打开web-ui,通过flink web-ui结果可以看出,这里是个hash join,两个source,到join,一共3个task。
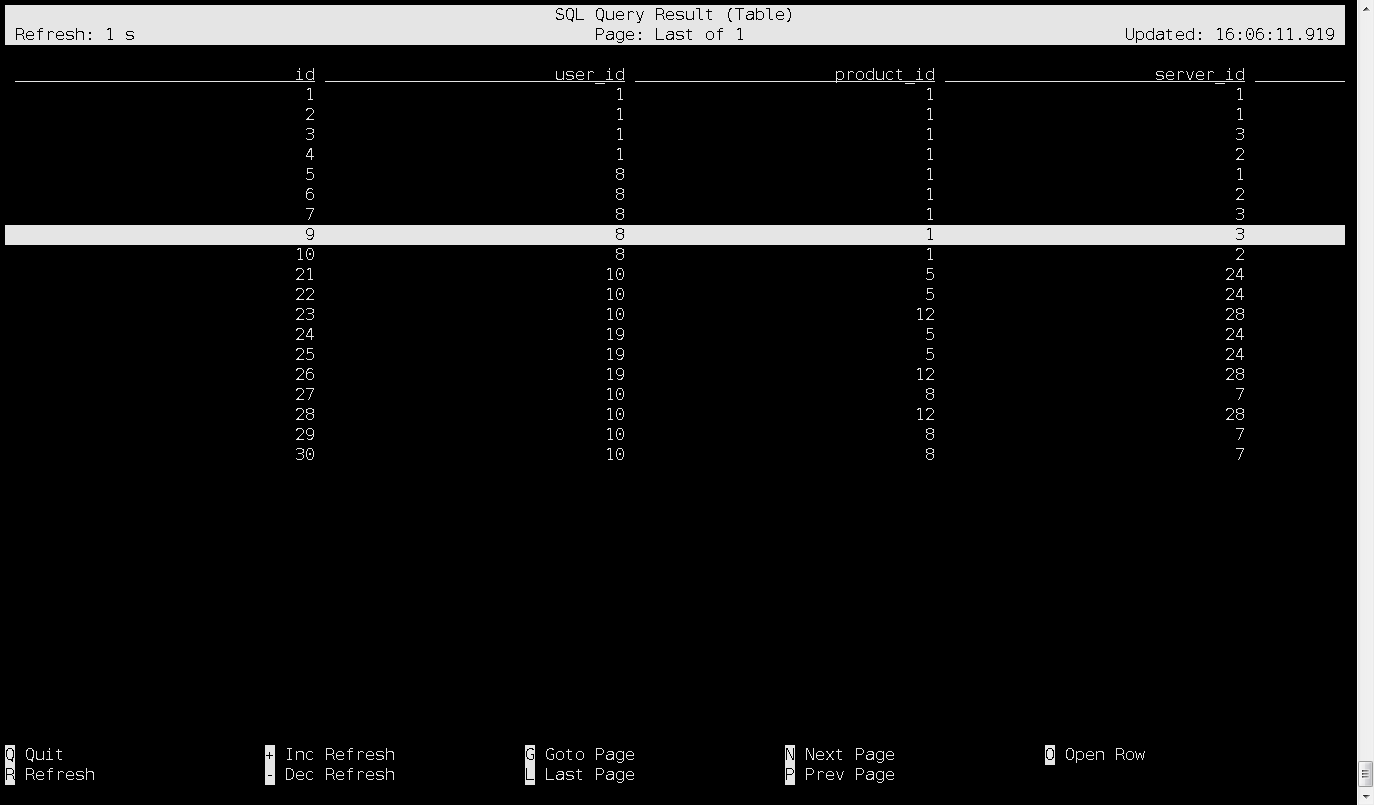
看看查出来的结果吧,这是flnk-sql client:
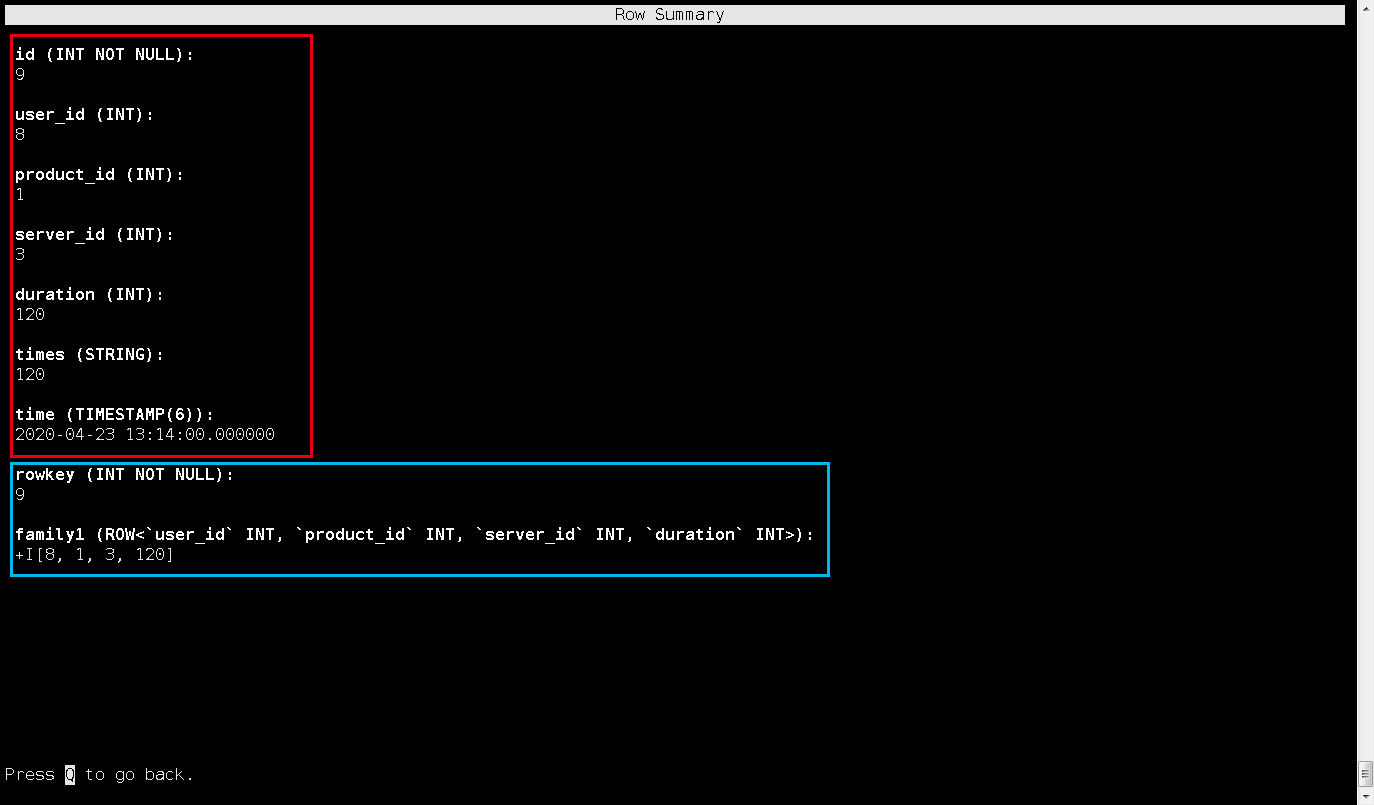
比如我选中这一行,进来后是这条数据的详细情况,是没有问题的:
参考资料
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/connectors/table/hbase/
flink-cdc同步mysql数据到hbase的更多相关文章
- Sqoop导入mysql数据到Hbase
sqoop import --driver com.mysql.jdbc.Driver --connect "jdbc:mysql://11.143.18.29:3306/db_1" ...
- Sqoop将mysql数据导入hbase的血与泪
Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天) 版权声明:本文为yunshuxueyuan原创文章.如需转载请标明出处: https://my.oschina.net/yunsh ...
- 使用Logstash来实时同步MySQL数据到ES
上篇讲到了ES和Head插件的环境搭建和配置,也简单模拟了数据作测试 本篇我们来实战从MYSQL里直接同步数据 一.首先下载和你的ES对应的logstash版本,本篇我们使用的都是6.1.1 下载后使 ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- Logstash使用jdbc_input同步Mysql数据时遇到的空时间SQLException问题
今天在使用Logstash的jdbc_input插件同步Mysql数据时,本来应该能搜索出10条数据,结果在Elasticsearch中只看到了4条,终端中只给出了如下信息 [2017-08-25T1 ...
- 推荐一个同步Mysql数据到Elasticsearch的工具
把Mysql的数据同步到Elasticsearch是个很常见的需求,但在Github里找到的同步工具用起来或多或少都有些别扭. 例如:某记录内容为"aaa|bbb|ccc",将其按 ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- flink-cdc同步mysql数据到hive
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
随机推荐
- 入门Python数据分析最好的实战项目(一)分析篇
数据初探 首先导入要使用的科学计算包numpy,pandas,可视化matplotlib,seaborn,以及机器学习包sklearn. python学习交流群:660193417### import ...
- Object类中wait带参方法和notifyAll方法和线程间通信
notifyAll方法: 进入到Timed_Waiting(计时等待)状态有两种方式: 1.sleep(long m)方法,在毫秒值结束之后,线程睡醒,进入到Runnable或BLocked状态 2. ...
- Etcd 使用场景:通过分布式锁思路实现自动选主
分布式锁?选主? 分布式锁可以保证当有多台实例同时竞争一把锁时,只有一个人会成功,其他的都是失败.诸如共享资源修改.幂等.频控等场景都可以通过分布式锁来实现. 还有一种场景,也可以通过分布式锁来实现, ...
- SpringBoot接口 - API接口有哪些不安全的因素?如何对接口进行签名?
在以SpringBoot开发后台API接口时,会存在哪些接口不安全的因素呢?通常如何去解决的呢?本文主要介绍API接口有不安全的因素以及常见的保证接口安全的方式,重点实践如何对接口进行签名.@pdai ...
- HTTP协议之Expect爬坑
前言 今天,在对接一个第三方平台开放接口时遇到一个很棘手的问题,根据接口文档组装好报文,使用HttpClient发起POST请求时一直超时,对方服务器一直不给任何响应. 发起请求的代码如下: usin ...
- 算法竞赛进阶指南0x41并查集
并查集简介 并查集的两类操作: Get 查询任意一个元素是属于哪一个集合. Merge 把两个集合合并在一起. 基本思想:找到代表元. 注意有两种方法: 使用一个固定的值(查询方便,但是在合并的时候需 ...
- 浅谈hooks——useEffect
react 16.8发布以来,函数式写法逐渐取代class的写法,在react函数式写法中,最重要是就是react所推出的新特性:hook,今天就来简单谈谈最基础的hook--useEffect 在r ...
- PHP几个工具函数
移除XSS攻击脚本 function RemoveXSS($val) { // remove all non-printable characters. CR(0a) and LF(0b) and T ...
- 别无分号只此一家,Python3接入支付宝身份认证接口( alipay.user.certify)体系(2021年最新攻略)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_184 目前国内身份认证体系做的比较不错的大抵就是支付宝和微信两家了,支付宝的身份验证基于支付宝app的实人认证能力,采用多因子认证 ...
- P4983忘情
今天挺开心的\(\sim\),省选加油\(!\) \(P4893\)忘情 我能说今晚我才真正学会\(wqs\)和斜率优化吗\(?\) 恰好选几个,必然需要\(wqs\)二分一下 那么考虑不考虑次数情况 ...