hive第二篇----hive中partition如何使用
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type
[COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
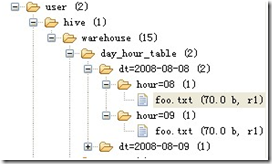
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD
partition_spec [ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ... partition_spec:
: PARTITION (partition_col = partition_col_value,
partition_col = partiton_col_value, ...)用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD
PARTITION (dt='2008-08-08', hour='08')
location '/path/pv1.txt'
PARTITION (dt='2008-08-08', hour='09')
location '/path/pv2.txt';7、删除分区语法:
ALTER TABLE table_name DROP
partition_spec, partition_spec,...用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:ALTER TABLE day_hour_table
DROP PARTITION (dt='2008-08-08', hour='09');8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08');
LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。9、基于分区的查询的语句:SELECT day_table.*
FROM day_table
WHERE day_table.dt>= '2008-08-08';10、查看分区语句:
hive> show partitions day_hour_table;
OK
dt=2008-08-08/hour=08
dt=2008-08-08/hour=09
dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
hive第二篇----hive中partition如何使用的更多相关文章
- 第二篇 Flask 中的 Render Redirect HttpResponse
第二篇 Flask 中的 Render Redirect HttpResponse 1.Flask中的HTTPResponse 在Flask 中的HttpResponse 在我们看来其实就是直接返 ...
- Flask最强攻略 - 跟DragonFire学Flask - 第二篇 Flask 中的 Render Redirect HttpResponse
1.Flask中的HTTPResponse 在Flask 中的HttpResponse 在我们看来其实就是直接返回字符串 2.Flask中的Redirect 每当访问"/redi" ...
- 【python游戏编程之旅】第二篇--pygame中的IO、数据
本系列博客介绍以python+pygame库进行小游戏的开发.有写的不对之处还望各位海涵. 在上一篇中,我们介绍了pygame的入门操作http://www.cnblogs.com/msxh/p/49 ...
- Android学习笔记(第二篇)View中的五大布局
PS:人不要低估自己的实力,但是也不能高估自己的能力.凡事谦为本... 学习内容: 1.用户界面View中的五大布局... i.首先介绍一下view的概念 view是什么呢?我们已经知道一个Act ...
- 第二篇 -- C#中对XML操作
一.XML文件操作中与.Net中对应的类 微软的.NET框架在System.xml命名空间提供了一系列的类用于Dom的实现. 以下给出XML文档的组成部分对应.NET中的类: XML文档组成部分 对应 ...
- hive第一篇----简介和使用客户端
摘要by crazyhacking:•Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能.•本质是将SQL转换为MapReduce程序的映射 ...
- 转义字符\(在hive+shell以及java中注意事项):正则表达式的转义字符为双斜线,split函数解析也是正则
转义字符 将后边字符转义,使特殊功能字符作为普通字符处理,或者普通字符转化为特殊功能字符. 各个语言中都用应用,如java.python.sql.hive.shell等等. 如sql中 "\ ...
- Hadoop入门第五篇:Hive简介以及部署
标签(空格分隔): Hadoop Hive hwi 1.Hive简介 之前我一直在Maxcompute上进行大数据开发,所以对数仓这块还算比较了解,在接受Hive的时候基本上没什么大的障碍.所以, ...
- 大数据学习day25------spark08-----1. 读取数据库的形式创建DataFrame 2. Parquet格式的数据源 3. Orc格式的数据源 4.spark_sql整合hive 5.在IDEA中编写spark程序(用来操作hive) 6. SQL风格和DSL风格以及RDD的形式计算连续登陆三天的用户
1. 读取数据库的形式创建DataFrame DataFrameFromJDBC object DataFrameFromJDBC { def main(args: Array[String]): U ...
随机推荐
- Head First - 01.策略模式(Strategy Pattern)
策略模式定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户. 当你需要给朋友留下深刻印象,或是影响关键主管的决策时,请使用“这个”定义! 设计原则: 1.找出 ...
- NavigationBar的显隐和颜色设置
[self.navigationController setNavigationBarHidden:NO animated:NO]; self.navigationController.navigat ...
- 通知传值 notification
@implementation ViewController - (void)viewDidLoad { [super viewDidLoad]; self.textF = [[UITextField ...
- 在MyEclipse中运行tomcat报错 严重: Error starting static Resources
严重: Error starting static Resourcesjava.lang.IllegalArgumentException: Document base E:\apache-tomca ...
- OpenGL-----深度测试,剪裁测试、Alpha测试和模板测试
片断测试其实就是测试每一个像素,只有通过测试的像素才会被绘制,没有通过测试的像素则不进行绘制.OpenGL提供了多种测试操作,利用这些操作可以实现一些特殊的效果.我们在前面的课程中,曾经提到了“深度测 ...
- 利用Fiddler抓取手机APP数据包
Fiddler是一个调试代理,下载地址http://www.telerik.com/download/fiddler 下载安装运行后,查出运行机器的IP,手机连接同一网域内的WIFI,手机WIFI连接 ...
- runtime基础知识
看到一篇不错的runtime方面博客: 引言 相信很多同学都听过运行时,但是我相信还是有很多同学不了解什么是运行时,到底在项目开发中怎么用?什么时候适合使用?想想我们的项目中,到底在哪里使用过运行时呢 ...
- 怎样将MySQL数据库上传到服务器
首先,需要将本地的数据库导出来,作为一个数据文件,以备稍后上传到服务器用,在本地登陆phpmyadmin控制面板: 登陆成功后,在左侧选择需要操作的数据库: 选择后,页面会自动刷新,然后再在右边点击[ ...
- 添加以及删除className
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- VIJOS P1081 野生动物园 SBT、划分树模板
[描述] cjBBteam拥有一个很大的野生动物园.这个动物园坐落在一个狭长的山谷内,这个区域从南到北被划分成N个区域,每个区域都饲养着一头狮子.这些狮子从北到南编号为1,2,3,…,N.每头狮子都有 ...