MySQL(Innodb)索引的原理
引言
回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的
索引就像一本书的目录。而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点。这样就帮助用户有效地提高了查找速度。所以,使用索引可以有效地提高数据库系统的整体性能。
嗯,这么说其实也对。但是呢,大家看完这种说法,其实可能还是觉得太抽象了!因此呢,我还想再深入的细说一下,所以就有了此文!
需要说明的是,我说的内容只在Mysql的Innodb引擎中是成立的。在Sql Server、oracle、Mysql的Mysiam引擎中的正确性,不一定成立!
OK,废话不多说,开始啰嗦!
正文
索引的科普
先引进聚簇索引和非聚簇索引的概念!
我们平时在使用的Mysql中,使用下述语句
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name (index_col_name,...)
index_col_name:
col_name [(length)] [ASC | DESC]创建的索引,如复合索引、前缀索引、唯一索引,都是属于非聚簇索引,在有的书籍中,又将其称为辅助索引(secondary index)。在后文中,我们称其为非聚簇索引,其数据结构为B+树。
那么,这个聚簇索引,在Mysql中是没有语句来另外生成的。在Innodb中,Mysql中的数据是按照主键的顺序来存放的。那么聚簇索引就是按照每张表的主键来构造一颗B+树,叶子节点存放的就是整张表的行数据。由于表里的数据只能按照一颗B+树排序,因此一张表只能有一个聚簇索引。
在Innodb中,聚簇索引默认就是主键索引。
这个时候,机智的读者,应该要问我
如果我的表没建主键呢?
回答是,如果没有主键,则按照下列规则来建聚簇索引
- 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
- 如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
ps:大家还记得,自增主键和uuid作为主键的区别么?由于主键使用了聚簇索引,如果主键是自增id,,那么对应的数据一定也是相邻地存放在磁盘上的,写入性能比较高。如果是uuid的形式,频繁的插入会使innodb频繁地移动磁盘块,写入性能就比较低了。
索引原理介绍
先来一张带主键的表,如下所示,pId是主键
| pId | name | birthday |
|---|---|---|
| 5 | zhangsan | 2016-10-02 |
| 8 | lisi | 2015-10-04 |
| 11 | wangwu | 2016-09-02 |
| 13 | zhaoliu | 2015-10-07 |
画出该表的结构图如下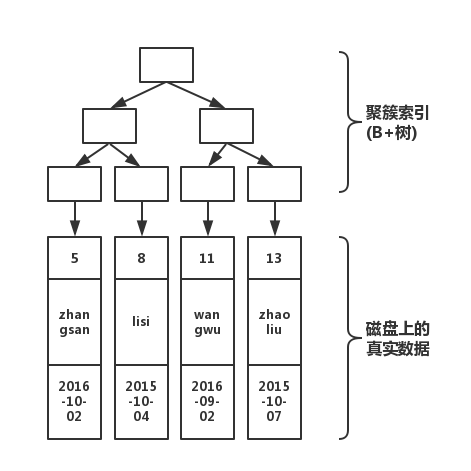
如上图所示,分为上下两个部分,上半部分是由主键形成的B+树,下半部分就是磁盘上真实的数据!那么,当我们, 执行下面的语句
select * from table where pId='11'那么,执行过程如下
如上图所示,从根开始,经过3次查找,就可以找到真实数据。如果不使用索引,那就要在磁盘上,进行逐行扫描,直到找到数据位置。显然,使用索引速度会快。但是在写入数据的时候,需要维护这颗B+树的结构,因此写入性能会下降!
OK,接下来引入非聚簇索引!我们执行下面的语句
create index index_name on table(name);此时结构图如下所示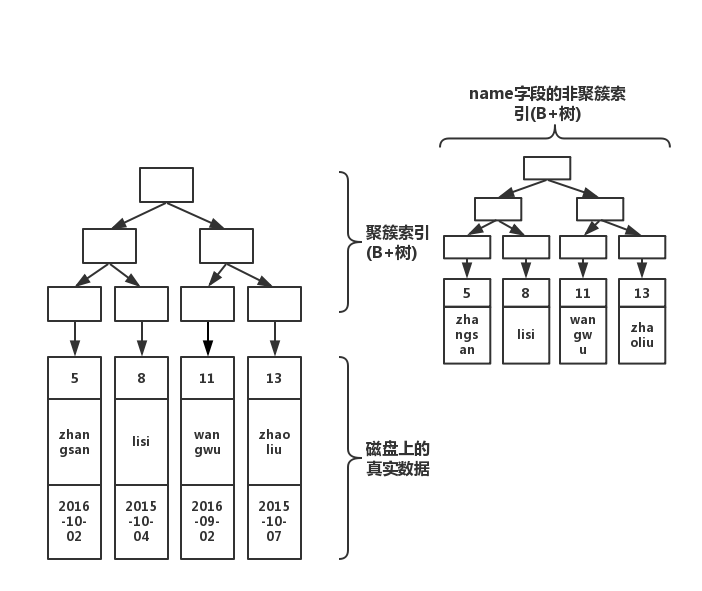
大家注意看,会根据你的索引字段生成一颗新的B+树。因此, 我们每加一个索引,就会增加表的体积, 占用磁盘存储空间。然而,注意看叶子节点,非聚簇索引的叶子节点并不是真实数据,它的叶子节点依然是索引节点,存放的是该索引字段的值以及对应的主键索引(聚簇索引)。
如果我们执行下列语句
select * from table where name='lisi'此时结构图如下所示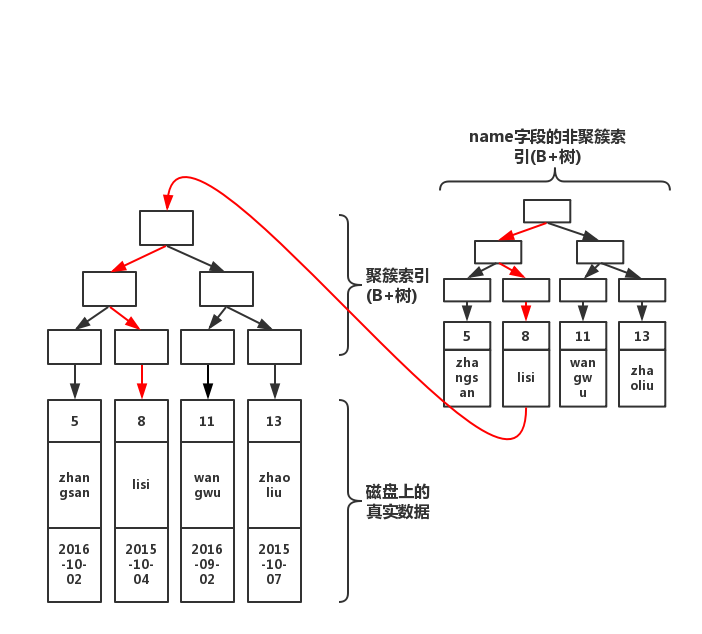
通过上图红线可以看出,先从非聚簇索引树开始查找,然后找到聚簇索引后。根据聚簇索引,在聚簇索引的B+树上,找到完整的数据!
那
什么情况不去聚簇索引树上查询呢?
还记得我们的非聚簇索引树上存着该索引字段的值么。如果,此时我们执行下面的语句
select name from table where name='lisi'此时结构图如下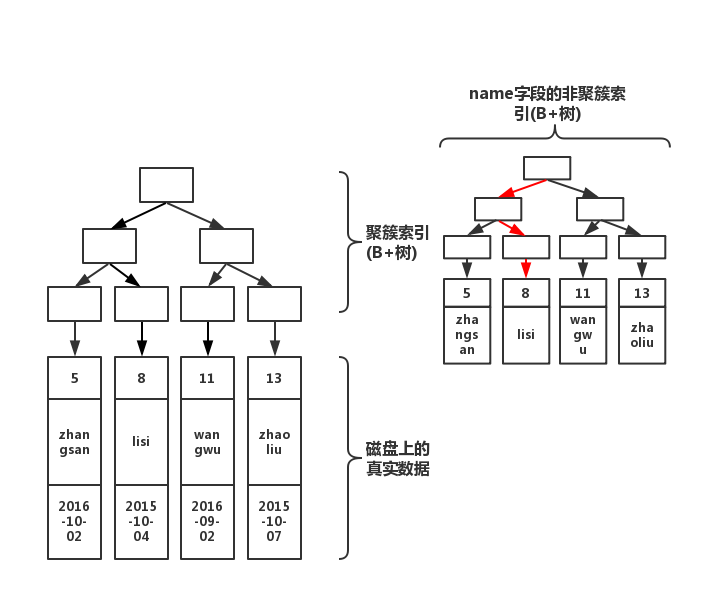
如上图红线所示,如果在非聚簇索引树上找到了想要的值,就不会去聚簇索引树上查询。还记得,博主在《select的正确姿势》提到的索引问题么:
当执行select col from table where col = ?,col上有索引的时候,效率比执行select * from table where col = ? 速度快好几倍!
看完上面的图,你应该对这句话有更深层的理解了。
那么这个时候,我们执行了下述语句,又会发生什么呢?
create index index_birthday on table(birthday);此时结构图如下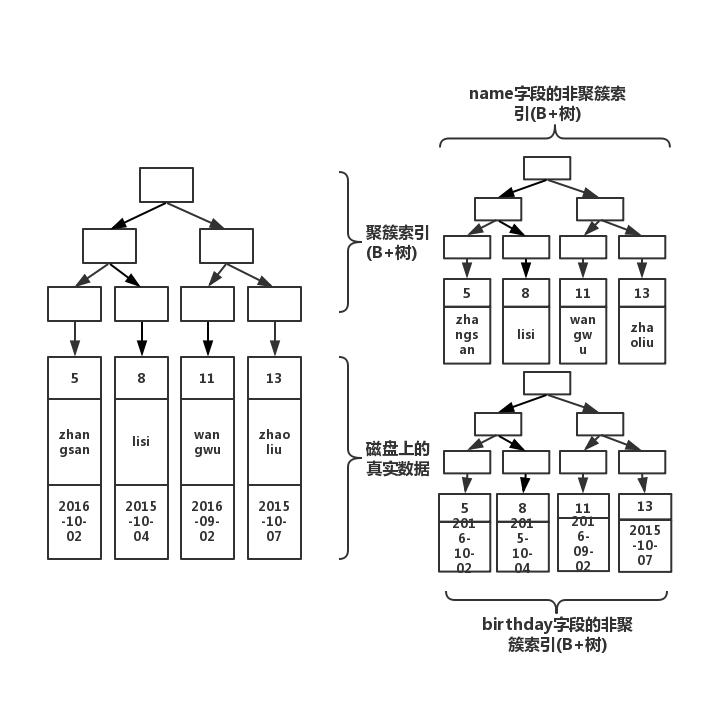
看到了么,多加一个索引,就会多生成一颗非聚簇索引树。因此,很多文章才说,索引不能乱加。因为,有几个索引,就有几颗非聚簇索引树!你在做插入操作的时候,需要同时维护这几颗树的变化!因此,如果索引太多,插入性能就会下降!
MySQL(Innodb)索引的原理的更多相关文章
- 【原创】MySQL(Innodb)索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有 ...
- MySQL InnoDB 索引 (INDEX) 页结构
MySQL InnoDB 索引 (INDEX) 页结构 InnoDB 为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做索引页 索引页内容 索引页分为以下部分: File Header:表 ...
- 为什么mysql innodb索引是B+树数据结构
1.文件很大,不可能全部存储在内存中,所以要存在磁盘上 2.索引的组织结构要尽量减少查找过程中磁盘I/O的存取次数(为什么用B-/+Tree,还跟磁盘存取原理有关) 3.B+树所有的data域在叶子节 ...
- MySQL的索引实现原理
MySQL数据库索引总结使用索引的原由数据结构Hash.平衡二叉树.B树.B+树区别机械硬盘.固态硬盘区别Myisam与Innodb B+树的区别MySQL中的索引什么数据结构B+树中的节点到底存放多 ...
- MySQL InnoDB索引介绍以及在线添加索引实例分析
引言:MySQL之所以能成为经典,不是没有道理的,B+树足矣! 一.索引概念 InnoDB引擎支持三种常见的索引:B+树索引,全文索引和(自适应)哈希索引.B+树索引是传统意义上的索引,构造类似二叉树 ...
- mysql InnoDB 索引小记
0.索引结构 1).MyISAM与InnoDB索引结构比较,如下: 2).MyISAM的索引结构 主键索引和二级索引结构很像,叶子存储的都是索引以及数据存储的物理地址,其他节点存储的仅仅是索引信息.其 ...
- MySQL InnoDB 索引组织表 & 主键作用
InnoDB 索引组织表 一.索引组织表定义 在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT). 在Inno ...
- 高性能MySQL之索引深入原理分析
一.背景 我们工作中经常打交道的就是索引,那么到底什么是索引呢?例如,当一个SQL查询比较慢的时候,你可能会说给“某个字段加个索引吧”之类的解决方案. 总的来说索引的出现其实就是为了提高数据查询的效率 ...
- MySQL-索引工作原理及使用注意事项
1.为什么需要索引(Why is it needed)? 当数据保存在磁盘类存储介质上时,它是作为数据块存放.这些数据块是被当作一个整体来访问的,这样可以保证操作的原子性.硬盘数据块存储结构类似于链表 ...
随机推荐
- Windows XP Professional产品序列号
BX6HT-MDJKW-H2J4X-BX67W-TVVFG产品密钥:FCKGW-RHQQ2-YXRKT-8TG6W-2B7Q8产品密钥:CCC64-69Q48-Y3KWW-8V9GV-TVKRM Wi ...
- LeetCode——18. 4Sum
一.题目链接:https://leetcode.com/problems/4sum/ 二.题目大意: 给定一个数组A和一个目标值target,要求从数组A中找出4个数来使之构成一个4元祖,使得这四个数 ...
- LeetCode——1. Two Sum
一.题目链接:https://leetcode.com/articles/two-sum/ 二.题目大意: 给定一个int型数组A和int值a,要求从A中找到两个数,使得这两个数值的和为a:返回结果为 ...
- 函数节流和防抖(todo)
一.什么是函数节流和函数防抖 函数节流和函数防抖目的都是避免同时多次执行函数. 函数防抖是将多次执行变成一次执行,函数节流是将多次执行变成每隔一定时间执行一次. 二.具体实现 三.什么时候需要节流,什 ...
- 函数,lambda函数,递归函数,内置函数(map,filter),装饰器
1. 集合 主要作用: 去重 关系测试, 交集\差集\并集\反向(对称)差集 2. 元组 只读列表,只有count, index 2 个方法 作用:如果一些数据不想被人修改, 可以存成元组,比如身份证 ...
- 廖雪峰Java5Java集合-5Queue-1使用Queue
Queue特性和基本方法 Queue实现一个先进先出(FIFO, First In First Out)的队列.如收银台排队支付. Java中LinkedList实现了Queue接口,可以直接把Lin ...
- grep简单用法
grep 常用参数: -c: 打印符合要求的行数 -i :忽略大小写 -n:输出行和行号 -v:打印不符合要求的行,即反选 -A:后跟数字(有无空格都可以),例如-A2 表示打印筛选行及前2行 -B: ...
- 拓扑试验划分简单的静态VLAN
拓扑图 说明: 把交换机连接到PC机的网口类型设置成为access 把交换机与交换机之间的网口类型设置成为truck 然后再给交换机每一个接口划分VLAN 操作如下: 交换机LSW1的配置: 进入输入 ...
- [UE4]嵌套Canvas
- keras训练和保存
https://cloud.tencent.com/developer/article/1010815 8.更科学地模型训练与模型保存 filepath = 'model-ep{epoch:03d}- ...