hbase高可用集群部署(cdh)
一、概要
本文记录hbase高可用集群部署过程,在部署hbase之前需要事先部署好hadoop集群,因为hbase的数据需要存放在hdfs上,hadoop集群的部署后续会有一篇文章记录,本文假设hadoop集群已经部署好,分布式hbase集群需要依赖zk,并且zk可以是hbase自己托管的也可以是我们自己单独搭建的,这里我们使用自己单独搭建的zk集群,我们的hadoop集群是用的cdh的发行版,所以hbase也会使用cdh的源。
二、环境
1、软件版本
centos6
zookeeper-3.4.5+cdh5.9.0+98-1.cdh5.9.0.p0.30.el6.x86_64
hadoop-2.6.0+cdh5.9.0+1799-1.cdh5.9.0.p0.30.el6.x86_64
hbase-1.2.0+cdh5.9.0+205-1.cdh5.9.0.p0.30.el6.x86_64
2、角色
a、zk集群
|
1
2
3
|
10.10.20.64:218110.10.40.212:218110.10.102.207:2181 |
b、hbase
|
1
2
3
4
5
|
10.10.40.212 HMaster10.10.20.64 HMaster10.10.10.114 HRegionServer10.10.40.169 HRegionServer10.10.30.174 HRegionServer |
三、部署
1、配置cdh的yum源
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
vim /etc/yum.repos.d/cloudera-cdh.repo[cloudera-cdh5]# Packages for Cloudera's Distribution for Hadoop, Version 5.4.4, on RedHat or CentOS 6 x86_64name=Cloudera's Distribution for Hadoop, Version 5.4.8baseurl=http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/5.9.0/gpgkey=http://archive.cloudera.com/cdh5/redhat/6/x86_64/cdh/RPM-GPG-KEY-cloudera gpgcheck=1[cloudera-gplextras5b2]# Packages for Cloudera's GPLExtras, Version 5.4.4, on RedHat or CentOS 6 x86_64name=Cloudera's GPLExtras, Version 5.4.8baseurl=http://archive.cloudera.com/gplextras5/redhat/6/x86_64/gplextras/5.9.0/gpgkey=http://archive.cloudera.com/gplextras5/redhat/6/x86_64/gplextras/RPM-GPG-KEY-cloudera gpgcheck=1 |
2、安装zk集群(所有zk节点都操作)
1、安装
|
1
|
yum -y install zookeeper zookeeper-server |
b、配置
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
vim /etc/zookeeper/conf/zoo.cfg tickTime=2000initLimit=10syncLimit=5dataDir=/data/lib/zookeeperclientPort=2181maxClientCnxns=0server.1=10.10.20.64:2888:3888server.2=10.10.40.212:2888:3888server.3=10.10.102.207:2888:3888autopurge.snapRetainCount=3autopurge.purgeInterval=1 |
|
1
|
mkdir -p /data/lib/zookeeper #建zk的dir目录 |
|
1
2
3
|
echo 1 >/data/lib/zookeeper/myid #10.10.20.64上操作echo 2 >/data/lib/zookeeper/myid #10.10.40.212上操作echo 3 >/data/lib/zookeeper/myid #10.10.102.207上操作 |
c、启动服务
|
1
|
/etc/init.d/zookeeper-server start |
3、安装配置hbase集群
a、安装
|
1
2
|
yum -y install hbase hbase-master #HMaster节点操作 yum -y install hbase hbase-regionserver #HRegionServer节点操作 |
b、配置(所有base节点操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
vim /etc/hbase/conf/hbase-site.xml <?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration> <property> <name>hbase.zookeeper.quorum</name> <value>10.10.20.64:2181,10.10.40.212:2181,10.10.102.207:2181</value> </property> <property> <name>hbase.zookeeper.property.clientPort</name> <value>2181</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/data/lib/zookeeper/</value> </property> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> <description>集群的模式,分布式还是单机模式,如果设置成false的话,HBase进程和Zookeeper进程在同一个JVM进程 </description> </property></configuration> |
|
1
2
|
echo "export HBASE_MANAGES_ZK=false" >>/etc/hbase/conf/hbase-env.sh#设置hbase使用独立的zk集群 |
|
1
2
3
4
5
|
vim /etc/hbase/conf/regionservers ip-10-10-30-174.ec2.internalip-10-10-10-114.ec2.internalip-10-10-40-169.ec2.internal#添加HRegionServer的主机名到regionservers,我没有在/etc/hosts下做主机名的映射,直接用了ec2的默认主机名 |
c、启动服务
|
1
2
|
/etc/init.d/hbase-master start #HMaster节点操作/etc/init.d/hbase-regionserver start #HRegionServer节点操作 |
4、验证
a、验证基本功能
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[root@ip-10-10-20-64 ~]# hbase shell 2017-05-10 16:31:20,225 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.availableHBase Shell; enter 'help<RETURN>' for list of supported commands.Type "exit<RETURN>" to leave the HBase ShellVersion 1.2.0-cdh5.9.0, rUnknown, Fri Oct 21 01:19:47 PDT 2016hbase(main):001:0> status1 active master, 1 backup masters, 3 servers, 0 dead, 1.3333 average loadhbase(main):002:0> listTABLE test test1 2 row(s) in 0.0330 seconds=> ["test", "test1"]hbase(main):003:0> describe 'test'Table test is ENABLED test COLUMN FAMILIES DESCRIPTION {NAME => 'id', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} {NAME => 'name', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} {NAME => 'text', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} 3 row(s) in 0.1150 secondshbase(main):004:0> |
b、验证HA功能
1、hbase默认的web管理端口是60010,两个HMaster谁先启动谁就是主active节点,10.10.40.212先启动,10.10.20.64后启动,web截图如下:
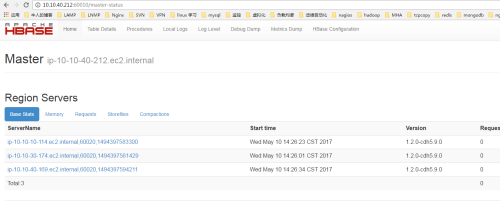
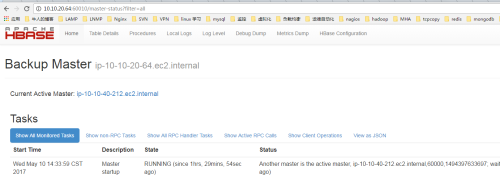
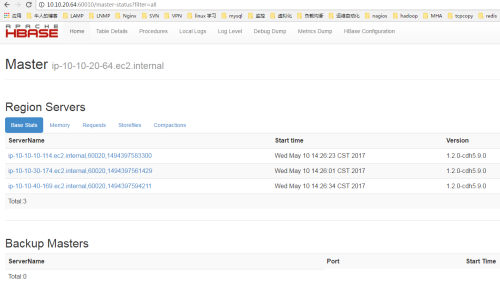
2、停止10.10.40.212的HMaster进程,查看10.10.20.64是否会提升为master
|
1
|
/etc/init.d/hbase-master stop |
hbase高可用集群部署(cdh)的更多相关文章
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- RocketMQ的高可用集群部署
RocketMQ的高可用集群部署 标签(空格分隔): 消息队列 部署 1. RocketMQ 集群物理部署结构 Rocket 物理部署结构 Name Server: 单点,供Producer和Cons ...
- RabbitMQ的高可用集群部署
RabbitMQ的高可用集群部署 标签(空格分隔): 消息队列 部署 1. RabbitMQ部署的三种模式 1.1 单一模式 单机情况下不做集群, 仅仅运行一个RabbitMQ. # docker-c ...
- rocketmq高可用集群部署(RocketMQ-on-DLedger Group)
rocketmq高可用集群部署(RocketMQ-on-DLedger Group) rocketmq部署架构 rocketmq部署架构非常多,都是为了解决一些问题,越来越高可用,越来越复杂. 单ma ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- Centos6.9下RocketMQ3.4.6高可用集群部署记录(双主双从+Nameserver+Console)
之前的文章已对RocketMQ做了详细介绍,这里就不再赘述了,下面是本人在测试和生产环境下RocketMQ3.4.6高可用集群的部署手册,在此分享下: 1) 基础环境 ip地址 主机名 角色 192. ...
- Hadoop部署方式-高可用集群部署(High Availability)
版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的高可用集群是建立在完全分布式基础之上的,详情请参考:https://www.cnblogs.com/yinzhengjie/p/90651 ...
- Kubernetes容器集群 - harbor仓库高可用集群部署说明
之前介绍Harbor私有仓库的安装和使用,这里重点说下Harbor高可用集群方案的部署,目前主要有两种主流的Harbor高可用集群方案:1)双主复制:2)多harbor实例共享后端存储. 一.Harb ...
- 【转】harbor仓库高可用集群部署说明
之前介绍Harbor私有仓库的安装和使用,这里重点说下Harbor高可用集群方案的部署,目前主要有两种主流的Harbor高可用集群方案:1)双主复制:2)多harbor实例共享后端存储. 一.Harb ...
随机推荐
- Java - 15 Java 正则表达式
Java 正则表达式 正则表达式定义了字符串的模式. 正则表达式可以用来搜索.编辑或处理文本. 正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别. Java正则表达式和Perl的是最为相似 ...
- Django中的视图
Django的View(视图) 一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应. 响应可以是一张网页的HTML内容,一个重定向,一个404错误, ...
- mybatis-plus 从2.x到3.x升级指南
Mybatis-Plus mybatis-plus 2.x 到 3.x 有以下改进 分页查询可以直接返回Ipage<T>的子类(下面会有详细使用说明) Wrapper<T> ...
- hive lateral view 与 explode详解
ref:https://blog.csdn.net/bitcarmanlee/article/details/51926530 1.explode hive wiki对于expolde的解释如下: e ...
- js 原生图片上传
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- python tkinter chk
视频过程中的练习, 可以在python2.7下运行. 001: hello,world: 1 2 3 4 5 6 from Tkinter import Label, Tk root = Tk() t ...
- 12.利用kakatips对网站数据信息监控
网站信息监控 kakatips软件 百度云链接:https://pan.baidu.com/s/1lNH8OGODbIvYeFTjz6kVEQ 密码:5qtz 这是我编辑好的具体详情如下: 有效标记需 ...
- mybatis一(常用配置信息和获取插入后id)
<!--配置文件--><?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE conf ...
- nslookup和dig命令
nslookup与dig两个工具功能类似,都可以查询制定域名所对应的ip地址,所不同的是dig工具可以从该域名的官方dns服务器上查询到精确的权威解答,而nslookup只会得到DNS解析服务器保存在 ...
- Nginx 服务器搭建
什么是Nginx ? Nginx与Apache IIS等软件一样,是一款服务器软件,为web站点提供服务 除此之外,Nginx 还是一款反向代理服务器,我们可以利用Nginx实现负载均衡 所谓负载均衡 ...