解决UnicodeDecodeError: 'ascii' codec can't decode byte 0xcf in position 7: ordinal not in range(128)
在Windows下同时装了Python2和Python3,但是在使用命令给pip更新的时候,出现了以下错误:
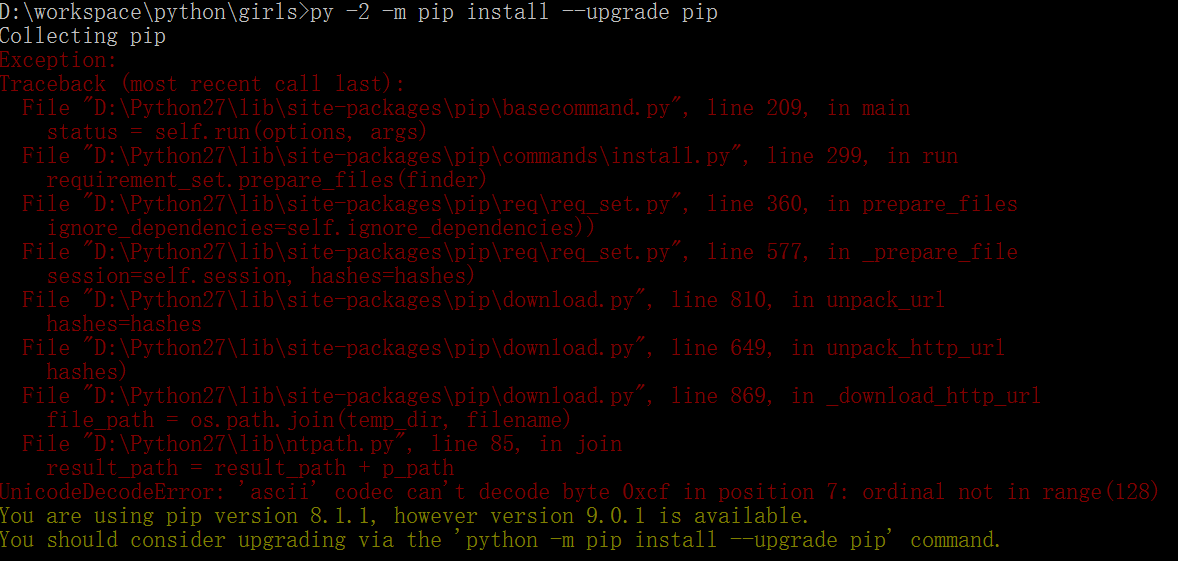
解决办法:修改mimetypes.py文件,路径位于python的安装路径下的Lib\mimetypes.py文件。在import下添加如下几行,将编码设置为‘gbk’:
if sys.getdefaultencoding() != 'gbk':
reload(sys)
sys.setdefaultencoding('gbk')
成功解决,如图:

解决UnicodeDecodeError: 'ascii' codec can't decode byte 0xcf in position 7: ordinal not in range(128)的更多相关文章
- 解决UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 12: ordinal not in range(128)的编码问题
当我在运行一个基于scrapy的爬虫时出现UnicodeDecodeError: 'ascii' codec can't decode byte 0xe7 in position 12: ordina ...
- HTMLTestRunner解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128)
其中HTML和数据库都是设置成utf-8格式编码,插入到数据库中是正确的,但是当读取出来的时候就会出错,原因就是python的str默认是ascii编码,和unicode编码冲突,就会报这个标题错误. ...
- 解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128
今天做网页到了测试和数据库交互的地方,其中HTML和数据库都是设置成utf-8格式编码,插入到数据库中是正确的,但是当读取出来的时候就会出错,原因就是python的str默认是ascii编码,和uni ...
- UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordinal not in range(128) 解决办法
最近在用Python处理中文字符串时,报出了如下错误: UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ...
- 解决Torch.load()错误信息: UnicodeDecodeError: 'ascii' codec can't decode byte 0x8d in position 0: ordinal not in range(128)
使用PyTorch跑pretrained预训练模型的时候,发现在加载数据的时候会报错,具体错误信息如下: File "main.py", line 238, in main_wor ...
- Python报错“UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ordinal not in range(128)”的解决办法
最近在用Python处理中文字符串时,报出了如下错误: UnicodeDecodeError: 'ascii' codec can't decode byte 0xe9 in position 0: ...
- 【Python】【解决】UnicodeDecodeError: 'ascii' codec can't decode byte 0xe5 in position 1: ordinal not in range(128)
1.问题描述 今天在升级Ubuntu到14.04,使用命令行启动软件更新器,进行版本升级,结果开始升级就异常退出了,具体打印如下: $update-manager -d 正在检查新版 Ubuntu 使 ...
- 解决python3读写中文txt时UnicodeDecodeError : 'ascii' codec can't decode byte 0xc4 in position 5595: ordinal not in range(128) on line 0的问题
今天使用python3读写含有中文的txt时突然报了如下错误,系统是MAC OS,iDE是pycharm: UnicodeDecodeError : 'ascii' codec can't decod ...
- python2.7 报错(UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 0: ordinal not in range(128))
报错: 原来用的python3.5版本后来改为2.7出现了这个错误里面的中文无法显示 UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 ...
随机推荐
- [Delphi]实现使用TIdHttp控件向https地址Post请求[转]
开篇:公司之前一直使用http协议进行交互(比如登录等功能),但是经常被爆安全性不高,所以准备改用https协议.百度了一下资料,其实使用IdHttp控件实现https交互的帖子并不少,鉴于这次成功实 ...
- Jmeter使用笔记之意料之外的
以下是在测试过程中按照以前loadrunner的思维来做的一点区别: 一.组织方式之setup 在用loadrunner做接口测试的时候如果不是针对login的测试,那么一般也会把login接口放到i ...
- 思维题练习专场-DP篇(附题表)
转载请注明原文地址http://www.cnblogs.com/LadyLex/p/8536399.html 听说今年省选很可怕?刷题刷题刷题 省选已经结束了但是我们要继续刷题刷题刷题 目标是“有思维 ...
- File类里的静态字段
我们都知道windows操作系统和Linux操作系统中的路径分隔符是不一样的,当我们直接使用绝对路径的时候,程序会报错误:No such file or diretory”的异常 File类有几个类似 ...
- 高阶函数map(),filter(),reduce()
接受函数作为参数,或者把函数作为结果返回的函数是高阶函数,官方叫做 Higher-order functions. map()和filter()是内置函数.在python3中,reduce()已不再是 ...
- Django入门项目实践(上)
项目结构 1.建立项目 File -->> New Project... 第一个Location是项目所在的目录,第二个Location是项目独立的Python运行环境,我们称之为Virt ...
- SQL Server手把手教你使用profile进行性能监控
介绍 经常会有人问profile工具该怎么使用?有没有方法获取性能差的sql的问题.自从转mysql我自己也差不多2年没有使用profile,忽然profile变得有点生疏不得不重新熟悉一下.这篇文章 ...
- Vue实例的生命周期(钩子函数)
Vue实例的生命钩子总共有10个 先上官方图: 下面时一个vue实例定义钩子函数的例子: var app=new Vue({ el:'#app', beforeCreate:function(){ c ...
- 样本标准差分母为何是n-1
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- PAM认证机制详情
PAM(Pluggable Authentication Modules)认证机制详情 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.介绍PAM PAM(Plugga ...