使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
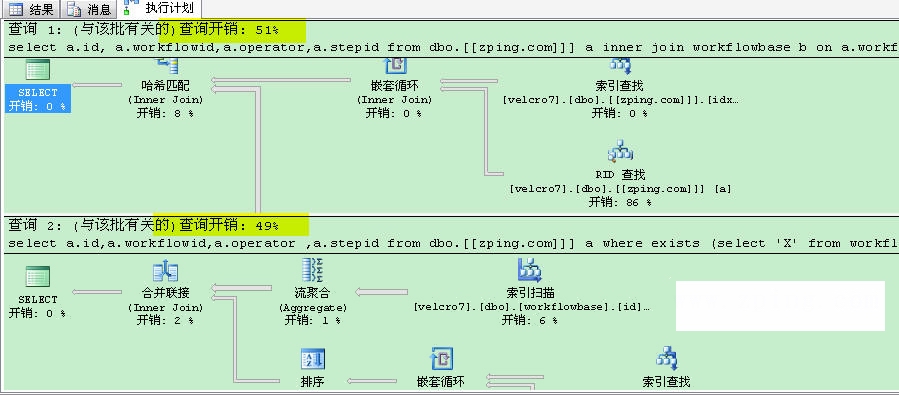
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:

(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
in和inner join在大多数情况下都是返回两表的交集,但是两者还是有区别的,如下例子
mysql> select * from a;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
MySQL> select * from b;
+------+------+
| id | name |
+------+------+
| 1 | d |
| 1 | g |
| 2 | e |
| 4 | f |
+------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 1 | a |
| 2 | b |
+------+------+
mysql> select * from a inner join b on (a.id = b.id);
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | 1 | d |
| 1 | a | 1 | g |
| 2 | b | 2 | e |
+------+------+------+------+
从查询结果中可以看出,in的结果是不会有重复的,对非主键进行join时,join的结果是有重复的。如果说还有另一个区别的话就是join会产生一个两表合并的临时表,in不会产生两表合并的临时表。
使用 EXISTS 代替 IN 和 inner join的更多相关文章
- MySql学习(三) —— 子查询(where、from、exists) 及 连接查询(left join、right join、inner join、union join)
注:该MySql系列博客仅为个人学习笔记. 同样的,使用goods表来练习子查询,表结构如下: 所有数据(cat_id与category.cat_id关联): 类别表: mingoods(连接查询时作 ...
- SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- Sql语句优化-查询两表不同行NOT IN、NOT EXISTS、连接查询Left Join
在实际开发中,我们往往需要比较两个或多个表数据的差别,比较那些数据相同那些数据不相同,这时我们有一下三种方法可以使用:1. IN或NOT IN,2. EXIST或NOTEXIST,3.使用连接查询(i ...
- 为什么 EXISTS(NOT EXIST) 与 JOIN(LEFT JOIN) 的性能会比 IN(NOT IN) 好
前言 网络上有大量的资料提及将 IN 改成 JOIN 或者 exist,然后修改完成之后确实变快了,可是为什么会变快呢?IN.EXIST.JOIN 在 MySQL 中的实现逻辑如何理解呢?本文也是比较 ...
- SQL语句 in和inner join各有什么优点
比如A1表 100W行 A2表50W行select a.* from A1 a where a.column1 in (select b.column1 from A2 b where b.colum ...
- MySQL中exists和in的区别及使用场景
exists和in的使用方式: 1 #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 1 select * from A where exists (select * fro ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
- in和exists
exists和in的使用方式: #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 select * from A where exists (select * from B ...
- MySQL中Exists和In的使用
Exists关键字: exists表示存在,是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避 ...
随机推荐
- Luogu P1113 杂务
终于没有打模板题了. 一道简单的拓扑题目(但记得以前第一次做的时候爆0了). 发现这个做事的过程是按一定顺序的,然后如果一个工作的前面没有任何事情的话,它一定先被完成(如果不的话就不能使时间最小化,其 ...
- 利用RMAN转移裸设备到文件系统
本文只是为了个人备忘. 参考eagyle的:http://www.eygle.com/archives/2005/12/oracle_howto_move_datafile_raw.html 我首先挂 ...
- 查看Oracle数据库中的,已经连接好的..当前用户状况
参考: http://stackoverflow.com/questions/1043096/how-to-list-active-open-connections-in-oracle 以sys身份连 ...
- python 23 种 设计模式
频率 所属类型 模式名称 模式 简单定义 5 创建型 Singleton 单件 保证一个类只有一个实例,并提供一个访问它的全局访问点. 4 创建型 Abstract Factory 抽象工厂 提供一个 ...
- [LOJ#6039].「雅礼集训 2017 Day5」珠宝[决策单调性]
题意 题目链接 分析 注意到本题的 \(C\) 很小,考虑定义一个和 \(C\) 有关的状态. 记 \(f(x,j)\) 表示考虑到了价格为 \(x\) 的物品,一共花费了 \(j\) 元的最大收益. ...
- 7、Docker监控方案(cAdvisor+InfluxDB+Grafana)
一.组件介绍 我们采用现在比较流行的cAdvisor+InfluxDB+Grafana组合进行Docker监控. 1.cAdvisor(数据采集) 开源软件cAdvisor(Container Adv ...
- 基于HTTPS的中间人攻击-BaseProxy
前言 在上一篇文章BaseProxy:异步http/https代理中,我介绍了自己的开源项目BaseProxy,这个项目的初衷其实是为了渗透测试,抓包改包.在知识星球中,有很多朋友问我这个项目的原理及 ...
- 利用链式队列(带头节点)解决银行业务队列简单模拟问题(c++)-- 数据结构
题目: 7-1 银行业务队列简单模拟 (30 分) 设某银行有A.B两个业务窗口,且处理业务的速度不一样,其中A窗口处理速度是B窗口的2倍 —— 即当A窗口每处理完2个顾客时,B窗口处理完1个顾客 ...
- PAT-1010 Radix
1010 Radix (25 分) Given a pair of positive integers, for example, 6 and 110, can this equation 6 = 1 ...
- 树形DP ---- Codeforces Global Round 2 F. Niyaz and Small Degrees引发的一场血案
Aspirations:没有结果,没有成绩,acm是否有意义?它最大的意义就是让我培养快速理解和应用一个个未知知识点的能力. ————————————————————————————————————— ...