使用 EXISTS 代替 IN 和 inner join
在使用Exists时,如果能正确使用,有时会提高查询速度:
1,使用Exists代替inner join
2,使用Exists代替 in
1,使用Exists代替inner join例子:
在一般写sql语句时通常会遇到如下语句:
两个表连接时,取一个表的数据,一般的写法通过关联查询(inner join):
from dbo.[[zping.com]]] a
inner join workflowbase b on a.workflowid=b.id
and operator='4028814111ad9dc10111afc134f10041'
查询结果:
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 293 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
还有一种写法使用exists来取数据
from dbo.[[zping.com]]] a where exists
(select 'X' from workflowbase b where a.workflowid=b.id)
and operator='4028814111ad9dc10111afc134f10041'
执行结果:
表 '[zping.com]'。扫描计数 1,逻辑读取 1339 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 1,逻辑读取 291 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
这里两着的IO次数,EXISTS比inner join少 2个IO, 对比执行计划成本不一样, 看看两着的差异:
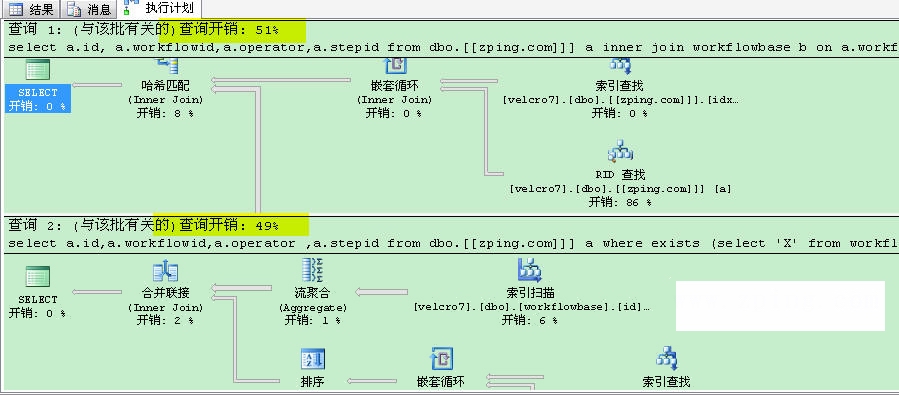
这时我们发现使用EXISTS要比inner join效率稍微高一下。
2,使用Exists代替 in
要求:编写workflowbase表中id不在表中dbo.[[zping.com]]]的行:
一般的写法:
where id not in (
select a.workflowid
from dbo.[[zping.com]]] a )
执行结果:

(1 行受影响)
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 5,逻辑读取 56952 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
使用Existsl来写:
where not exists(
select 'X'
from dbo.[[zping.com]]] a where a.workflowid=b.id )
看看执行结果
表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 '[zping.com]'。扫描计数 3,逻辑读取 18984 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
表 'workflowbase'。扫描计数 3,逻辑读取 1589 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
两个io的差距:56952+1589=58541次 (使用IN)
18984+1589=20573次 (使用Exists)
使用exists是in的2.8倍,查询性能提高很大。
EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果。
in和inner join在大多数情况下都是返回两表的交集,但是两者还是有区别的,如下例子
mysql> select * from a;
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
| 3 | c |
+------+------+
MySQL> select * from b;
+------+------+
| id | name |
+------+------+
| 1 | d |
| 1 | g |
| 2 | e |
| 4 | f |
+------+------+
mysql> select a.id, a.name from a where a.id in (select b.id from b);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 2 | b |
+------+------+
mysql> select a.id, a.name from a inner join b on (a.id = b.id);
+------+------+
| id | name |
+------+------+
| 1 | a |
| 1 | a |
| 2 | b |
+------+------+
mysql> select * from a inner join b on (a.id = b.id);
+------+------+------+------+
| id | name | id | name |
+------+------+------+------+
| 1 | a | 1 | d |
| 1 | a | 1 | g |
| 2 | b | 2 | e |
+------+------+------+------+
从查询结果中可以看出,in的结果是不会有重复的,对非主键进行join时,join的结果是有重复的。如果说还有另一个区别的话就是join会产生一个两表合并的临时表,in不会产生两表合并的临时表。
使用 EXISTS 代替 IN 和 inner join的更多相关文章
- MySql学习(三) —— 子查询(where、from、exists) 及 连接查询(left join、right join、inner join、union join)
注:该MySql系列博客仅为个人学习笔记. 同样的,使用goods表来练习子查询,表结构如下: 所有数据(cat_id与category.cat_id关联): 类别表: mingoods(连接查询时作 ...
- SQL优化--使用 EXISTS 代替 IN 和 inner join来选择正确的执行计划
在使用Exists时,如果能正确使用,有时会提高查询速度: 1,使用Exists代替inner join 2,使用Exists代替 in 1,使用Exists代替inner join例子: 在一般写s ...
- Sql语句优化-查询两表不同行NOT IN、NOT EXISTS、连接查询Left Join
在实际开发中,我们往往需要比较两个或多个表数据的差别,比较那些数据相同那些数据不相同,这时我们有一下三种方法可以使用:1. IN或NOT IN,2. EXIST或NOTEXIST,3.使用连接查询(i ...
- 为什么 EXISTS(NOT EXIST) 与 JOIN(LEFT JOIN) 的性能会比 IN(NOT IN) 好
前言 网络上有大量的资料提及将 IN 改成 JOIN 或者 exist,然后修改完成之后确实变快了,可是为什么会变快呢?IN.EXIST.JOIN 在 MySQL 中的实现逻辑如何理解呢?本文也是比较 ...
- SQL语句 in和inner join各有什么优点
比如A1表 100W行 A2表50W行select a.* from A1 a where a.column1 in (select b.column1 from A2 b where b.colum ...
- MySQL中exists和in的区别及使用场景
exists和in的使用方式: 1 #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 1 select * from A where exists (select * fro ...
- MySQL Execution Plan--NOT EXISTS子查询优化
在很多业务场景中,会使用NOT EXISTS语句来确保返回数据不存在于特定集合,部分场景下NOT EXISTS语句性能较差,网上甚至存在谣言"NOT EXISTS无法走索引". 首 ...
- in和exists
exists和in的使用方式: #对B查询涉及id,使用索引,故B表效率高,可用大表 -->外小内大 select * from A where exists (select * from B ...
- MySQL中Exists和In的使用
Exists关键字: exists表示存在,是对外表做loop循环,每次loop循环再对内表(子查询)进行查询,那么因为对内表的查询使用的索引(内表效率高,故可用大表),而外表有多大都需要遍历,不可避 ...
随机推荐
- Scala学习(二)练习
Scala控制结构和函数&练习 1. 一个数字如果为正数,则它的signum为1:如果是负数,则signum为-1:如果为0,则signum为0:编写一个函数来计算这个值 简单逻辑判断: 测试 ...
- 对 JavaScript 中的5种主要的数据类型进行值复制
定义一个函数 clone(),可以对 JavaScript 中的5种主要的数据类型(包括 Number.String.Object.Array.Boolean)进行值复制 使用 typeof 判断值得 ...
- .NetCore利用BlockingCollection实现简易消息队列
前言 消息队列现今的应用场景越来越大,常用的有RabbmitMQ和KafKa. 我们用BlockingCollection来实现简单的消息队列. 实现消息队列 用Vs2017创建一个控制台应用程序.创 ...
- ats 安全
Controlling Access ats可以配置为仅允许某些客户端使用代理缓存. 1. 为ip_allow.config添加一行,以获取允许访问ats的每个IP地址或IP地址范围; 2. traf ...
- Appium+Python3+ Android入门
前言: Appium 是一个自动化测试开源工具,支持 iOS 平台和 Android 平台上的原生应用,web 应用和混合应用. 一.环境配置 1.安装Node.js https://nodejs.o ...
- Beta冲刺——day7
Beta冲刺--day7 作业链接 Beta冲刺随笔集 github地址 团队成员 031602636 许舒玲(队长) 031602237 吴杰婷 031602220 雷博浩 031602134 王龙 ...
- Win7(及以后版本) 高级搜索 AND OR NOT 正则
http://www.cnblogs.com/include/archive/2011/08/23/2150594.html TIP:语法容易混淆,容易误用用C系列语法 & | !等,其实是S ...
- [CB] 支付宝区块链的应用- 区块链发票医保理赔.
全国第一单区块链理赔.发票开出:1分钟报销 区块链技术和概念随着比特币等虚拟电子货币的兴起而尽人皆知,但是区块链的用途可不仅仅只玩币,尤其是在“矿难”到来之后,区块链正在向更多应用领域渗透.最 ...
- memcache安装以及php_memcache.dll 扩展安装
php_memcache.dll扩展下载地址:http://windows.php.net/downloads/pecl/releases/memcache/3.0.8/ 下载注意事项:选择匹配自己环 ...
- 如何让搜索引擎抓取AJAX内容?
越来越多的网站,开始采用"单页面结构"(Single-page application). 整个网站只有一张网页,采用Ajax技术,根据用户的输入,加载不同的内容. 这种做法的好处 ...