基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习
课程:Q-Learning强化学习(李宏毅)、深度强化学习
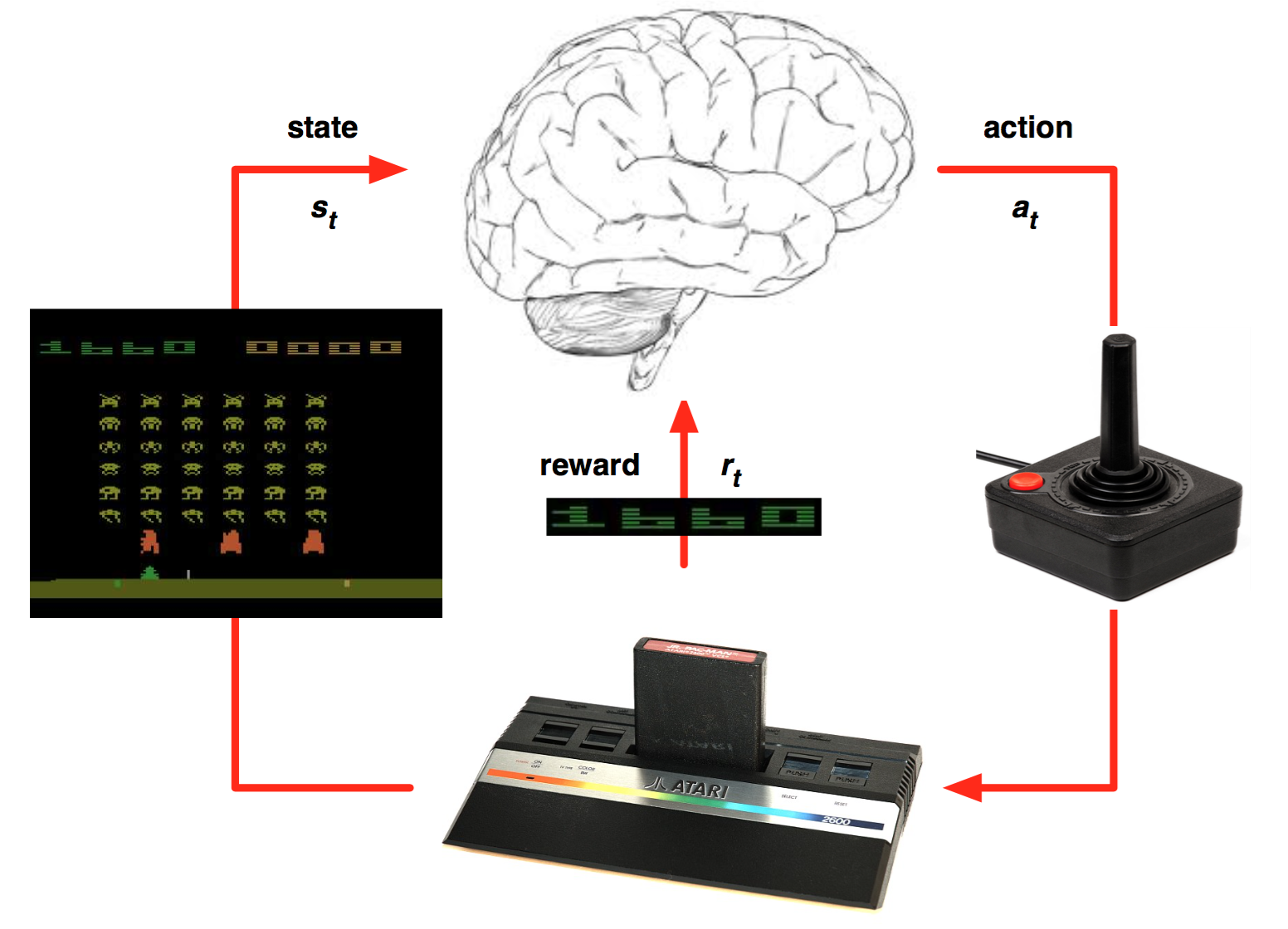
强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习。如上图所示,大脑代表AI Agent并在环境中活动。当每次行动过后,Agent接收到环境反馈。反馈包括回报Reward和环境的下个状态State,回报由模型设计者定义。如果类比人类学习自行车,可以将车从起始点到当前位置的距离定义为回报。
分类:
1)基于价值Value的强化学习算法 - Q-learning
基本思想:根据当前的状态,计算采取每个动作的价值,然后根据价值贪心地选择动作,即预测某个环境下所有Action的期望值(即Q值)
例如:Deep Q Network、Double DQN、Prioritised replay、Dueling Network、NatureDQN
2)基于策略梯度的强化学习算法 - Policy Gradients
基本思想:省略中间步骤,直接根据当前的状态来选择动作,即直接预测在某个环境下应该采取的Action
例如:Policy Network
一般来说,Q-learning方法只适合有少量离散取值的Action环境,而Policy Gradients方法适合有连续取值的Action环境。在与深度学习方法结合后,这两种算法就变成了Policy Network和DQN(Deep Q-learning Network)
对比:
(1)Policy Network可以处理连续的action,而DQN则只能处理离散问题,通过枚举的方式来实现,连续的action只能离散化后再处理。
(2)Policy Network通过输出的action概率值大小随机选择action,而DQN则通过贪婪选择法ε-greedy选择action。
(2)DQN的更新是一个一个的reward进行更新,即当前的reward只跟邻近的一个相关;Policy Network则将一个episode的reward全部保存起来,然后用discount的方式修正reward,标准化后进行更新。
深度强化学习
2013年,在DeepMind发表的论文Playing Atari with Deep Reinforcement Learning中,介绍了一种新算法——深度Q网络(DQN),展示了AI Agent如何在没有任何先验信息的情况下通过观察屏幕学习玩游戏。从而开启了所谓的“深度强化学习”新时代,其是混合了深度学习与强化学习的新算法。
在Q学习算法中,有一种函数被称为Q函数,它用来估计基于一个状态的回报。同样地,在DQN中,我们使用一个神经网络估计基于状态的回报函数。
使用Keras与Gym环境基于DQN玩CartPole游戏
Github:https://github.com/keon/deep-q-learning
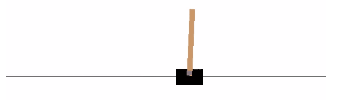
Cart-Pole车杆游戏
CartPole是OpenAI gym中最简单的一个环境,CartPole的目的就是杆子平衡在移动的小车上。游戏规则很简单,游戏里面有一个小车,上有竖着一根杆子。小车需要左右移动来保持杆子竖直。如果杆子倾斜的角度大于15°,那么游戏结束。同时,小车也不能移出一定范围(中间到两边各2.4个单位长度)。其中,除了像素信息,还有四种信息可以用作状态,例如:杆子的角度、车在滑轨的位置。Agent可以通过施加左(0)或右(1)的动作,使小车移动。
Gym
Gym 是 OpenAI 发布的用于开发和比较强化学习算法的工具包。使用它我们可以让 AI 智能体做很多事情,比如行走、跑动,以及进行多种游戏。
# 安装Gym pip install gym
# 基于Gym进行游戏环境交互 next_state, reward, done, info = env.step(action)
其中,action可以选择0或1,输入环境中将会反馈结果。env是游戏环境类。done为标记游戏结束与否的布尔量。当前状态“state”,“action”,“next_state”与“reward”是用于训练Agent的数据。
使用Gym实现Cart-Pole
# -*- coding: utf-8 -*-
import gym
import numpy as np
def try_gym():
# 使用gym创建一个CartPole环境
# 这个环境可以接收一个action,返回执行action后的观测值,奖励与游戏是否结束
env = gym.make('CartPole-v0')
# 重置游戏环境
env.reset()
# 游戏轮数
random_episodes = 0
# 每轮游戏的Reward总和
reward_sum = 0
count = 0
while random_episodes < 10:
# 渲染显示游戏效果
env.render()
# 随机生成一个action,即向左移动或者向右移动。
# 然后接收执行action之后的反馈值
observation, reward, done, _ = env.step(np.random.randint(0, 2))
reward_sum += reward
count += 1
# 如果游戏结束,打印Reward总和,重置游戏
if done:
random_episodes += 1
print("Reward for this episode was: {}, turns was: {}".format(reward_sum, count))
reward_sum = 0
count = 0
env.reset()
if __name__ == '__main__':
try_gym()
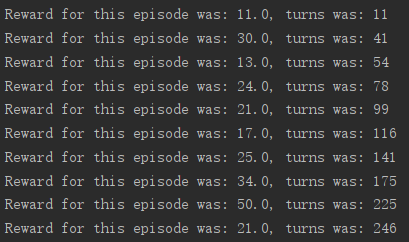
输出的是每一轮游戏从开始到结束得到的Reward的总和与操作次数
使用Keras实现简单神经网络
训练神经网络,从成对的输入与输出数据学习某种模式并且可以基于不可见的输入数据预测输出。

使用一个包含四种输入信息的输入层和三个隐藏层,以及两个节点的输出层 - 对应游戏中的两个按钮(0与1)
# Neural Net for Deep Q Learning # Sequential() creates the foundation of the layers. model = Sequential() # Dense is the basic form of a neural network layer # Input Layer 4 and Hidden Layer with 128 nodes model.add(Dense(64, input_dim=4, activation='tanh')) # Hidden layer with 128 nodes model.add(Dense(128, activation='tanh')) # Hidden layer with 128 nodes model.add(Dense(128, activation='tanh')) # Output Layer with 2 nodes model.add(Dense(2, activation='linear')) # Create the model based on the information above model.compile(loss='mse', optimizer=RMSprop(lr=self.learning_rate))
为了让模型可以基于环境数据理解与预测,需要传入数据。其中,fit()方法为模型提供“states”和“target_f”信息
model.fit(state, target_f, nb_epoch=1, verbose=0)
当模型调用predict()函数时,模型根据学习之前训练过的数据,来预测现在状态的回报函数
prediction = model.predict(state)
实现深度Q算法(DQN)
DQN算法最重要的特征是记忆(remember)与回顾(replay)方法
记忆:需要记录下先前的经验与观察值以便利用这些先前数据训练模型。将调用代表经验的数组数据memory和remember()函数来添加状态、动作、回报、下次状态到memory中
# memory列表memory = [(state, action, reward, next_State)...]
# 存储def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
回放:基于存储在memory中的数据(经验)训练神经网络
# 从memory中抽出部分数据,给训练数据bathces batches = min(batch_size, len(self.memory)) # 打乱memory中的bathces的索引数,例如batchce为[1,5,2,7]- 样本在memory中的索引数为1,5,2,7 batches = np.random.choice(len(self.memory), batches)
# 为了使Agent在长期运行中表现得更好,不仅仅需要考虑即时回报(immediate rewards),还要考虑未来回报(future rewards)。为了实现这一目标,定义discount rate折扣因子(即gamma)。这样,Agent将学习已有的状态然后想方设法最大化未来回报for i in batches:
# Extract informations from i-th index of the memory
state, action, reward, next_state = self.memory[i]
# if done, make our target reward (-100 penality)
target = reward
if not done:
# predict the future discounted reward
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
# make the agent to approximately map
# the current state to future discounted reward
# We'll call that target_f
target_f = self.model.predict(state)
target_f[0][action] = target
# Train the Neural Net with the state and target_f
self.model.fit(state, target_f, nb_epoch=1, verbose=0)
Agent选择行为:Agent在最初一段时间会随机选择行为,由exploration rate或epsilon参数表征。这是因为在最初对Agent最好的策略就是在其掌握模式前尝试一切。当Agent没有随机选择行为,它会基于当前状态预测回报值选择能够实现回报最大化的行为
# np.argmax()函数可以取出act_values[0]中的最大值
def act(self, state):
if np.random.rand() <= self.epsilon:
# The agent acts randomly
return env.action_space.sample()
# Predict the reward value based on the given state
act_values = self.model.predict(state)
# Pick the action based on the predicted reward
return np.argmax(act_values[0])# act_values[0]中的数据类似[0.67, 0.2],每个数字分别代表0和1的回报,于是argmax()会取出更大数值所代表的的行为。比如在[0.67, 0.2]中,argmax()返回0因为0索引代表的数据的回报最大
超参数 - 强化学习Agent所必需的部分超参数:
·episodes:让Agent玩游戏的次数 ·gamma discount rate:折扣因子,以便计算未来的折扣回报 ·epsilon exploration rate:表征一个Agent随机选择行为的程度(比率) ·epsilon_decay:上述参数的衰减率,使得随着Agent更擅长游戏的同时减少它探索的次数 ·epsilon_min:希望Agent采取的最少的探索次数 ·learning_rata:决定神经网络在每次迭代时的学习率(学习程度)
设计深度Q学习Agent - DQNAgent
# Deep-Q learning Agent
class DQNAgent:
def __init__(self, env):
self.env = env
self.memory = []
self.gamma = 0.9 # decay rate
self.epsilon = 1 # exploration
self.epsilon_decay = .995
self.epsilon_min = 0.1
self.learning_rate = 0.0001
self._build_model()
def _build_model(self):
model = Sequential()
model.add(Dense(128, input_dim=4, activation='tanh'))
model.add(Dense(128, activation='tanh'))
model.add(Dense(128, activation='tanh'))
model.add(Dense(2, activation='linear'))
model.compile(loss='mse',
optimizer=RMSprop(lr=self.learning_rate))
self.model = model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return env.action_space.sample()
act_values = self.model.predict(state)
return np.argmax(act_values[0]) # returns action
def replay(self, batch_size):
batches = min(batch_size, len(self.memory))
batches = np.random.choice(len(self.memory), batches)
for i in batches:
state, action, reward, next_state, done = self.memory[i]
target = reward
if not done:
target = reward + self.gamma * \
np.amax(self.model.predict(next_state)[0])
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, nb_epoch=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
训练DQNAgent
if __name__ == "__main__":
# 为Agent初始化gym环境参数
env = gym.make('CartPole-v0')
agent = DQNAgent(env)
# 游戏的主循环
for e in range(episodes):
# 在每次游戏开始时复位状态参数
state = env.reset()
state = np.reshape(state, [1, 4])
# time_t 代表游戏的每一帧
# 我们的目标是使得杆子尽可能长地保持竖直朝上
# time_t 越大,分数越高
for time_t in range(5000):
# turn this on if you want to render
# env.render()
# 选择行为
action = agent.act(state)
# 在环境中施加行为推动游戏进行
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, 4])
# reward缺省为1
# 在每一个Agent完成了目标的帧Agent都会得到回报
# 并且如果失败得到-100
reward = -100 if done else reward
# 记忆先前的状态,行为,回报与下一个状态
agent.remember(state, action, reward, next_state, done)
# 使下一个状态成为下一帧的新状态
state = copy.deepcopy(next_state)
# 如果游戏结束done被置为ture
# 除非Agent没有完成目标
if done:
# 打印分数并且跳出游戏循环
print("episode: {}/{}, score: {}"
.format(e, episodes, time_t))
break
# 通过之前的经验训练模型
agent.replay(32)
结果
【探索】
Agent通过随机行为探索游戏环境
【训练】
算法会经过多个阶段训练Agent
1.小车操作Agent试图平衡杆子
2.但是出界,游戏结束
3.当它距离边界太近时它不得不移动小车,于是杆子掉了
4.Agent最后掌握了平衡并学会控制杆子
经过几百个episodes的训练后,它开始学习如何最大化分数
使用Keras与Gym环境基于Nature-DQN玩CartPole游戏
Blog:https://www.jianshu.com/p/e037d42ab6b1
Github:https://github.com/xiaochus/Deep-Reinforcement-Learning-Practice
Nature DQN
DQN使用单个网络来进行选择动作和计算目标Q值;Nature DQN使用了两个网络,一个当前主网络用来选择动作,更新模型参数,另一个目标网络用于计算目标Q值,两个网络的结构是一模一样的。目标网络的网络参数不需要迭代更新,而是每隔一段时间从当前主网络复制过来,即延时更新,这样可以减少目标Q值和当前的Q值相关性。Nature DQN和DQN相比,除了用一个新的相同结构的目标网络来计算目标Q值以外,其余部分基本是完全相同的。
实现流程:
(1)首先构建神经网络,一个主网络,一个目标网络,他们的输入都为obervation,输出为不同action对应的Q值。
(2)在一个episode结束时(游戏胜利或死亡),将env重置,即observation恢复到了初始状态observation,通过贪婪选择法ε-greedy选择action。根据选择的action,获取到新的next_observation、reward和游戏状态。将[observation, action, reward, next_observation, done]放入到经验池中。经验池有一定的容量,会将旧的数据删除。
(3)从经验池中随机选取batch个大小的数据,计算出observation的Q值作为Q_target。对于done为False的数据,使用reward和next_observation计算discount_reward。然后将discount_reward更新到Q_traget中。
(4)每一个action进行一次梯度下降更新,使用MSE作为损失函数。注意与DPG不同,参数更新不是发生在每次游戏结束,而是发生在游戏进行中的每一步。
(5)每个batch我们更新参数epsilon,egreedy的epsilon是不断变小的,也就是随机性不断变小。
(6)每隔固定的步数,从主网络中复制参数到目标网络。
使用keras实现Nature DQN
# -*- coding: utf-8 -*-
import os
import gym
import random
import numpy as np
from collections import deque
from keras.layers import Input, Dense
from keras.models import Model
from keras.optimizers import Adam
import keras.backend as K
class DQN:
def __init__(self):
self.model = self.build_model()
self.target_model = self.build_model()
self.update_target_model()
if os.path.exists('./model/ndqn_.h5'):
self.model.load_weights('./model/ndqn_.h5')
# 经验池
self.memory_buffer = deque(maxlen=2000)
# Q_value的discount rate,以便计算未来reward的折扣回报
self.gamma = 0.95
# 贪婪选择法的随机选择行为的程度
self.epsilon = 1.0
# 上述参数的衰减率
self.epsilon_decay = 0.995
# 最小随机探索的概率
self.epsilon_min = 0.01
self.env = gym.make('CartPole-v0')
def build_model(self):
"""基本网络结构.
"""
inputs = Input(shape=(4,))
x = Dense(16, activation='relu')(inputs)
x = Dense(16, activation='relu')(x)
x = Dense(2, activation='linear')(x)
model = Model(inputs=inputs, outputs=x)
return model
def update_target_model(self):
"""更新target_model
"""
self.target_model.set_weights(self.model.get_weights())
def egreedy_action(self, state):
"""ε-greedy选择action
Arguments:
state: 状态
Returns:
action: 动作
"""
if np.random.rand() <= self.epsilon:
return random.randint(0, 1)
else:
q_values = self.model.predict(state)[0]
return np.argmax(q_values)
def remember(self, state, action, reward, next_state, done):
"""向经验池添加数据
Arguments:
state: 状态
action: 动作
reward: 回报
next_state: 下一个状态
done: 游戏结束标志
"""
item = (state, action, reward, next_state, done)
self.memory_buffer.append(item)
def update_epsilon(self):
"""更新epsilon
"""
if self.epsilon >= self.epsilon_min:
self.epsilon *= self.epsilon_decay
def process_batch(self, batch):
"""batch数据处理
Arguments:
batch: batch size
Returns:
X: states
y: [Q_value1, Q_value2]
"""
# 从经验池中随机采样一个batch
data = random.sample(self.memory_buffer, batch)
# 生成Q_target。
states = np.array([d[0] for d in data])
next_states = np.array([d[3] for d in data])
y = self.model.predict(states)
q = self.target_model.predict(next_states)
for i, (_, action, reward, _, done) in enumerate(data):
target = reward
if not done:
target += self.gamma * np.amax(q[i])
y[i][action] = target
return states, y
def train(self, episode, batch):
"""训练
Arguments:
episode: 游戏次数
batch: batch size
Returns:
history: 训练记录
"""
self.model.compile(loss='mse', optimizer=Adam(1e-3))
history = {'episode': [], 'Episode_reward': [], 'Loss': []}
count = 0
for i in range(episode):
observation = self.env.reset()
reward_sum = 0
loss = np.infty
done = False
while not done:
# 通过贪婪选择法ε-greedy选择action。
x = observation.reshape(-1, 4)
action = self.egreedy_action(x)
observation, reward, done, _ = self.env.step(action)
# 将数据加入到经验池。
reward_sum += reward
self.remember(x[0], action, reward, observation, done)
if len(self.memory_buffer) > batch:
# 训练
X, y = self.process_batch(batch)
loss = self.model.train_on_batch(X, y)
count += 1
# 减小egreedy的epsilon参数。
self.update_epsilon()
# 固定次数更新target_model
if count != 0 and count % 20 == 0:
self.update_target_model()
if i % 5 == 0:
history['episode'].append(i)
history['Episode_reward'].append(reward_sum)
history['Loss'].append(loss)
print('Episode: {} | Episode reward: {} | loss: {:.3f} | e:{:.2f}'.format(i, reward_sum, loss,
self.epsilon))
self.model.save_weights('./model/ndqn_.h5')
return history
def play(self):
"""使用训练好的模型测试游戏.
"""
observation = self.env.reset()
count = 0
reward_sum = 0
random_episodes = 0
while random_episodes < 10:
self.env.render()
x = observation.reshape(-1, 4)
q_values = self.model.predict(x)[0]
action = np.argmax(q_values)
observation, reward, done, _ = self.env.step(action)
count += 1
reward_sum += reward
if done:
print("Reward for this episode was: {}, turns was: {}".format(reward_sum, count))
random_episodes += 1
reward_sum = 0
count = 0
observation = self.env.reset()
self.env.close()
if __name__ == '__main__':
model = DQN()
history = model.train(600, 32)
model.play()
训练结果


随着训练次数的增加,DQN模型在游戏中获得Reward不断的增加,并且Loss不断降低。在batch=32的条件下600次Episode的训练后进行模型测试, DQN也有不错的表现,如果进一步训练应该能达到和Policy Network同样的效果。
相比Policy Network,DQN的训练过程更稳定一些,但是DQN有个问题,就是它并不一定能保证Q网络的收敛。也就是说,我们不一定可以得到收敛后的Q网络参数,这会导致我们训练出的模型效果很差,因此也需要反复尝试选取最好的模型。
测试结果

使用Keras与Gym环境基于Policy Gradient玩CartPole游戏
Github:https://github.com/princewen/tensorflow_practice/tree/master/Basic-Policy-Network
Policy Gradients
基本思想:直接根据状态输出动作或者动作的概率
实现:神经网络 - 输入当前的状态,输出当前状态下采取每个动作的概率
- 算法输出的是动作的概率,而不是Q值
- 损失函数的形式为:loss= -log(prob)*vt
- 需要一次完整的episode才可以进行参数的更新
算法&训练:

网络应该如何训练来实现最终的收敛呢? 一般在训练神经网络时,使用最多的方法就是反向传播算法,其需要一个误差函数,通过梯度下降来使损失最小。但对于强化学习来说,由于不知道动作的正确与否,只能通过奖励值来判断这个动作的相对好坏。 基于上面的想法,有个非常简单的想法:如果一个动作得到的reward多,那么就使其出现的概率增加,如果一个动作得到的reward少,就使其出现的概率减小。 根据这个思想,构造如下的损失函数:loss= -log(prob)*vt(Why we consider log likelihood instead of Likelihood in Gaussian Distribution)
log(prob):代表在状态 s 对所选动作 a 的吃惊度, 如果概率越小, 反向的log(prob) 反而越大 vt:代表的是当前状态s下采取动作a所能得到的奖励,这是当前的奖励和未来奖励的贴现值的求和。也就是说,该策略梯度算法必须要完成一个完整的eposide才可以进行参数更新,与‘基于价值Value的强化学习方法可以基于每一个(s,a,r,s')进行参数更新’不同 如果在prob很小的情况下, 得到了一个大的Reward, 也就是大的vt, 那么-log(prob)*vt就更大, 表示更吃惊(即选了一个不常选的动作, 且发现原来它能得到了一个好的reward, 那就得对这次的参数进行一个大幅修改)
Policy Gradient的核心思想是更新参数时有两个考虑:如果这个回合选择某一动作,下一回合选择该动作的概率大一些,然后再看奖惩值,如果奖惩是正的,那么会放大这个动作的概率,如果奖惩是负的,就会减小该动作的概率。
Policy Gradient算法实现
1)定义参数
首先定义一些模型的参数 - self.ep_obs,self.ep_as,self.ep_rs分别存储当前episode的状态、动作和奖励
self.n_actions = n_actions self.n_features = n_features self.lr = learning_rate self.gamma = reward_decay self.ep_obs,self.ep_as,self.ep_rs = [],[],[]
2)定义模型输入
模型的输入包括三部分,分别是观察值、动作和奖励值
with tf.name_scope('inputs'):
self.tf_obs = tf.placeholder(tf.float32,[None,self.n_features],name='observation')
self.tf_acts = tf.placeholder(tf.int32,[None,],name='actions_num')
self.tf_vt = tf.placeholder(tf.float32,[None,],name='actions_value')
3)构建模型
模型定义了两层的神经网络,网络的输入是每次的观测值,而输出是该状态下采取每个动作的概率,这些概率在最后会经过一个softmax处理
layer = tf.layers.dense(
inputs = self.tf_obs,
units = 10,
activation= tf.nn.tanh,
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.3),
bias_initializer= tf.constant_initializer(0.1),
name='fc1'
)
all_act = tf.layers.dense(
inputs = layer,
units = self.n_actions,
activation = None,
kernel_initializer=tf.random_normal_initializer(mean=0,stddev=0.3),
bias_initializer = tf.constant_initializer(0.1),
name='fc2'
)
self.all_act_prob = tf.nn.softmax(all_act,name='act_prob')
4)模型的损失
模型的损失函数计算公式为:loss= -log(prob)*vt,可以直接使用tf.nn.sparse_softmax_cross_entropy_with_logits来计算前面一部分,即-log(prob),不过为了更清楚地显示计算过程,可以使用了如下的方式:
with tf.name_scope('loss'):
#neg_log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.all_act_prob,labels =self.tf_acts)
neg_log_prob = tf.reduce_sum(-tf.log(self.all_act_prob) * tf.one_hot(indices=self.tf_acts,depth=self.n_actions),axis=1)
loss = tf.reduce_mean(neg_log_prob * self.tf_vt)
选择AdamOptimizer优化器进行参数的更新
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(self.lr).minimize(loss)
5)动作选择
动作的选择不再根据贪心的策略来选择,而是根据输出动作概率的softmax值
def choose_action(self,observation):
prob_weights = self.sess.run(self.all_act_prob,feed_dict={self.tf_obs:observation[np.newaxis,:]})
action = np.random.choice(range(prob_weights.shape[1]),p=prob_weights.ravel())
return action
6)存储经验
其是在一个完整的episode结束后才开始训练的,因此在一个episode结束前,要存储这个episode所有的经验即状态、动作和奖励。
def store_transition(self,s,a,r):
self.ep_obs.append(s)
self.ep_as.append(a)
self.ep_rs.append(r)
7)计算奖励的贴现值
之前存储的奖励是当前状态s采取动作a获得的即时奖励,而当前状态s采取动作a所获得的真实奖励应该是即时奖励加上未来直到episode结束的奖励贴现之和
def _discount_and_norm_rewards(self):
discounted_ep_rs = np.zeros_like(self.ep_rs)
running_add = 0
# reserved 返回的是列表的反序,这样就得到了贴现求和值。
for t in reversed(range(0,len(self.ep_rs))):
running_add = running_add * self.gamma + self.ep_rs[t]
discounted_ep_rs[t] = running_add
discounted_ep_rs -= np.mean(discounted_ep_rs)
discounted_ep_rs /= np.std(discounted_ep_rs)
return discounted_ep_rs
8)模型训练
注意,输入给模型的并不是之前存储的奖励值,而是在经过上一步计算的奖励贴现之和。另外,需要在每一次训练之后清空经验池。
def learn(self):
discounted_ep_rs_norm = self._discount_and_norm_rewards()
self.sess.run(self.train_op,feed_dict={
self.tf_obs:np.vstack(self.ep_obs),
self.tf_acts:np.array(self.ep_as),
self.tf_vt:discounted_ep_rs_norm,
})
self.ep_obs,self.ep_as,self.ep_rs = [],[],[]
return discounted_ep_rs_norm
使用Keras与Gym环境基于DQN玩FlappyBird游戏
Github:https://github.com/yanpanlau/Keras-FlappyBird
使用Keras实现CNN
输入:使用了灰度图做输入,并在输入时连续拼接4帧动画 - 以便让CNN可以知道小鸟当前的速度信息
输出:两个神经元,分别表示两个动作(什么都不做 / 跳一下)对应的Q值。在游戏的每一步,选取Q值更高的动作作为Agent实际执行的动作。为了让游戏尽可能得到高分,目标则是让CNN逼近真实的状态-动作值函数
训练DQN
1)探索:首先定义一个列表 - 储存之前经历过的状态转移信息(St,At)→(St+1,Rt),分别为当前状态、当前执行动作、下一状态、当前动作带来的奖励。
D = deque()
最初一段时间,先让小鸟随机执行动作,并把所有的状态转移信息及奖励存入D
CNN对应状态-行为值函数Q(St,At),虽然神经网络输入只有S,但因为输出限定了各个维度代表对应的动作(只有两个动作,即两个维度),同时输出了Q(St, a1_t)和Q(St, a2_t),因此本质上还是Q(St,At)。
2)训练:达到指定次数之后,开始一边从D中随机采样训练神经网络(更新CNN参数),一边利用最新的CNN参数输出来指导小鸟行为,并把最新的状态转移信息存入D,这就是记忆回放机制。为了让动作依然具有一定随机性,定义了一个值epsilon来决定动作由网络指导还是随机采样。
if random.random() <= epsilon:
print("----------Random Action----------")
action_index = random.randrange(ACTIONS)
a_t[action_index] = 1
else:
q = model.predict(s_t) # input a stack of 4 images, get the prediction
max_Q = np.argmax(q)
action_index = max_Q
a_t[max_Q] = 1
其中之所以使用回放,是因为连续的状态S具有高度的相关性,如果总是使用最新的环境交互数据来训练会导致CNN很不稳定(类似于神经网络训练中的遗忘灾难问题),如果使用回放随机采样,则可以消除该不稳定性,让训练变得平滑。
minibatch = random.sample(D, BATCH) #1、从历史经验随机采样
inputs = np.zeros((BATCH, s_t.shape[1], s_t.shape[2], s_t.shape[3])) #32, 80, 80, 4
targets = np.zeros((inputs.shape[0], ACTIONS)) #32, 2
#Now we do the experience replay
for i in range(0, len(minibatch)):
state_t = minibatch[i][0]
action_t = minibatch[i][1]
reward_t = minibatch[i][2]
state_t1 = minibatch[i][3]
terminal = minibatch[i][4]
# if terminated, only equals reward
inputs[i:i + 1] = state_t #I saved down s_t
targets[i] = model.predict(state_t) # Hitting each buttom probability #2、预测的Q(St,At)值
Q_sa = model.predict(state_t1)#3、预测Q(St+1,At+1)
if terminal:
targets[i, action_t] = reward_t
else:
targets[i, action_t] = reward_t + GAMMA * np.max(Q_sa) #4、Rt + gamma*Qt+1 作为标签
# targets2 = normalize(targets)
loss += model.train_on_batch(inputs, targets) #5、训练CNN
贝尔曼方程:Qt = Rt + γRt+1 + γ2*Rt+2 + γ3*Rt+3 = ... = Rt + γ*Qt+1改进:1)实际执行训练的过程中,会发现小鸟非常容易在很长一段时间内连第一个柱子都过不去,这里可以考虑一些优化手段来获取更加高质量的样本。比如随机初始化大量小鸟同时运行,仅仅保留分数较高的作为样本加入记忆D。同样,当记忆容量达到上限时,可以优先删除R较低的样本。2)可以对每个样本增加采样权重,如果奖励更高,则使其被采样几率更大一些。
基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏的更多相关文章
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- gym强化学习入门demo——随机选取动作 其实有了这些动作和反馈值以后就可以用来训练DNN网络了
# -*- coding: utf-8 -*- import gym import time env = gym.make('CartPole-v0') observation = env.reset ...
- Ubuntu下常用强化学习实验环境搭建(MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2)
http://lib.csdn.net/article/aimachinelearning/68113 原文地址:http://blog.csdn.net/jinzhuojun/article/det ...
- 谷歌重磅开源强化学习框架Dopamine吊打OpenAI
谷歌重磅开源强化学习框架Dopamine吊打OpenAI 近日OpenAI在Dota 2上的表现,让强化学习又火了一把,但是 OpenAI 的强化学习训练环境 OpenAI Gym 却屡遭抱怨,比如不 ...
- 常用增强学习实验环境 I (MuJoCo, OpenAI Gym, rllab, DeepMind Lab, TORCS, PySC2) (转载)
原文地址:http://blog.csdn.net/jinzhuojun/article/details/77144590 和其它的机器学习方向一样,强化学习(Reinforcement Learni ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 李宏毅强化学习完整笔记!开源项目《LeeDeepRL-Notes》发布
Datawhale开源 核心贡献者:王琦.杨逸远.江季 提起李宏毅老师,熟悉强化学习的读者朋友一定不会陌生.很多人选择的强化学习入门学习材料都是李宏毅老师的台大公开课视频. 现在,强化学习爱好者有更完 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 深度强化学习资料(视频+PPT+PDF下载)
https://blog.csdn.net/Mbx8X9u/article/details/80780459 课程主页:http://rll.berkeley.edu/deeprlcourse/ 所有 ...
随机推荐
- 【知识库】-数据库_MySQL之高级数据查询:去重复、组合查询、连接查询、虚拟表
简书作者:seay 文章出处: 关系数据库SQL之高级数据查询:去重复.组合查询.连接查询.虚拟表 回顾:[知识库]-数据库_MySQL之基本数据查询:子查询.分组查询.模糊查询 Learn [已经过 ...
- Android学习_服务
一. 服务1. Android多线程 每一个Android应用程序都会分别运行在一个独立的Dalvik(或ART?)虚拟机中,而每个虚拟机在启动时会运行一个UI主线 ...
- Unity常用API备忘录
UnityEditor 复制文本到剪切板 GUIUtility.systemCopyBuffer 获取资源路径 AssetDatabase.GetAssetPath 选择节点 Selection.a ...
- django-rest-framework之 json web token方式完成用户认证
json web token的介绍:https://blog.csdn.net/kevin_lcq/article/details/74846723 1. 安装 $ pip install djang ...
- 【python / mxnet / gluoncv / jupyter notebook】变换场景的同一行人多重识别
程序环境为高性能集群:CPU:Intel Xeon Gold 6140 Processor * 2(共36核心)内存:512GB RAMGPU:Tesla P100-PCIE-16GB * 2 数 ...
- react源码之render
1.最近学习react源码,刚刚入门,看了render的原理,到了fiberRoot的创建 如图:
- add_header 'Cache-Control' 'no-store, no-cache, must-revalidate, proxy-revalidate, max-age=0'
发送一个报头,告诉浏览器当前页面不进行缓存,每次访问的时间必须从服务器上读取最新的数据 一般情况下,浏览器为了加快浏览速度会对网页进行缓存,在一定时间内再次访问同一页面的时候会有缓存里面读取而不是从服 ...
- WPF 键盘全局接收消息
1.========================================================================== 在c#中怎样禁用鼠标左键的使用,其实我们可以通 ...
- 阶段3 3.SpringMVC·_03.SpringMVC常用注解_6 CookieValue注解
演示 访问服务器会有session.它是一cookie的形式返回给客户端的 拿到的值
- Java连接Sap系统调并调用RFC函数
参考博客:https://blog.csdn.net/qq_36026747/article/details/81287462 https://www.cnblog ...