Hadoop 部署之 Spark (六)
一、Spark 是什么
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用分布式并行计算框架。Spark拥有hadoop MapReduce所具有的优点,但和MapReduce 的最大不同之处在于Spark是基于内存的迭代式计算——Spark的Job处理的中间输出结果可以保存在内存中,从而不再需要读写HDFS,除此之外,一个MapReduce 在计算过程中只有map 和reduce 两个阶段,处理之后就结束了,而在Spark的计算模型中,可以分为n阶段,因为它内存迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。
因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。其不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。
Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。Spark的一个重要特点就是能够在内存中计算,因而更快。即使在磁盘上进行的复杂计算,Spark依然比MapReduce更加高效。
二、Scala的安装(所有节点)
下载安装包
wget https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
解压安装包
tar xf scala-2.11.7.tgz
mv scala-2.11.7 /usr/local/scala
配置scala环境变量/etc/profile.d/scala.sh
# Scala ENV
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
使scala环境变量生效
source /etc/profile.d/scala.sh
三、Spark 安装(所有节点)
1、下载安装
# 下载安装包
wget https://mirrors.aliyun.com/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
# 解压安装包
tar xf spark-2.3.1-bin-hadoop2.7.tgz
mv spark-2.3.1-bin-hadoop2.7 /usr/local/spark
2、配置 Spark 环境变量
编辑文件/etc/profile.d/spark.sh,修改为如下:
# Spark ENV
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:
生效环境变量
source /etc/profile.d/spark.sh
四、Spark 配置(namenode01)
1、配置 spark-env.sh
编辑文件/usr/local/spark/conf/spark-env.sh,修改为如下内容:
export JAVA_HOME=/usr/java/default
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=namenode01
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
2、配置 slaves
编辑文件/usr/local/spark/conf/slaves,修改为如下内容:
datanode01
datanode02
datanode03
3、配置文件同步到其他节点
scp /usr/local/spark/conf/* datanode01:/usr/local/spark/conf/
scp /usr/local/spark/conf/* datanode02:/usr/local/spark/conf/
scp /usr/local/spark/conf/* datanode03:/usr/local/spark/conf/
4、启动 Spark 集群
Spark服务只使用hadoop的hdfs集群。
/usr/local/spark/sbin/start-all.sh
五、检查
1、JPS
[root@namenode01 ~]# jps
14512 NameNode
23057 RunJar
14786 ResourceManager
30355 Jps
15894 HMaster
30234 Master
[root@datanode01 ~]# jps
3509 DataNode
3621 NodeManager
1097 QuorumPeerMain
9930 RunJar
15514 Worker
15581 Jps
3935 HRegionServer
[root@datanode02 ~]# jps
3747 HRegionServer
14153 Worker
3322 DataNode
3434 NodeManager
1101 QuorumPeerMain
14221 Jps
[root@datanode03 ~]# jps
3922 DataNode
4034 NodeManager
19186 Worker
19255 Jps
1102 QuorumPeerMain
4302 HRegionServer
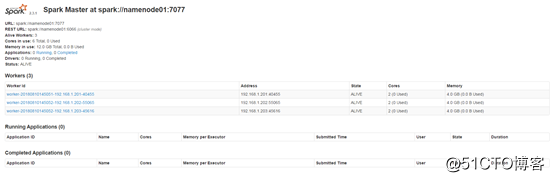
2、Spark WEB 界面
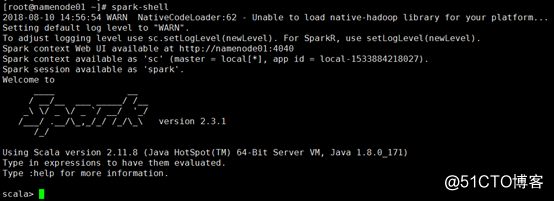
3、spark-shell
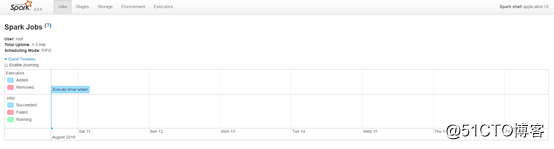
同时,因为shell在运行,我们也可以通过192.168.1.200:4040访问WebUI查看当前执行的任务。
Hadoop 部署之 Spark (六)的更多相关文章
- hadoop进阶----hadoop经验(一)-----生产环境hadoop部署在超大内存服务器的虚拟机集群上vs几个内存较小的物理机
生产环境 hadoop部署在超大内存服务器的虚拟机集群上 好 还是 几个内存较小的物理机上好? 虚拟机集群优点 虚拟化会带来一些其他方面的功能. 资源隔离.有些集群是专用的,比如给你三台设备只跑一个 ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Hadoop集群+Spark集群搭建(一篇文章就够了)
本文档环境基于ubuntu16.04版本,(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢) 一.准备 1.1 软件版本 Ub ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- hadoop部署小结的命令
hadoop部署总结的命令 学习笔记,转自:hadoop部署总结的命令http://www.aboutyun.com/thread-5385-1-1.html(出处: about云开发)
- Hadoop和Apache Spark的异同
谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生.但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,下面不妨跟我一块看下它们究竟有什么异同. 1.解决问 ...
- Hadoop 部署文档
Hadoop 部署文档 1 先决条件 2 下载二进制文件 3 修改配置文件 3.1 core-site.xml 3.2 hdfs-site.xml 3.3 mapred-site.xml 3.4 ya ...
- Hadoop部署方式-完全分布式(Fully-Distributed Mode)
Hadoop部署方式-完全分布式(Fully-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本博客搭建的虚拟机是伪分布式环境(https://w ...
- Hadoop部署方式-本地模式(Local (Standalone) Mode)
Hadoop部署方式-本地模式(Local (Standalone) Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop总共有三种运行方式.本地模式(Local ...
随机推荐
- throttle(节流函数) 与 debounce(防抖动函数)理解与实现
我们会对一些触发频率较高的事件进行监听,(如:resize scroll keyup事件) 如果在回调里执行高性能消耗的操作(如反复操作dom, 发起ajax请求等),反复触发时会使得性能消耗提高,浏 ...
- intelij idea 常用插件下载
本文,给大家推荐几款我私藏已久的,自己经常使用的,可以提升代码效率的插件.IDEA插件简介常见的IDEA插件主要有如下几类:常用工具支持Java日常开发需要接触到很多常用的工具,为了便于使用,很多工具 ...
- [Number]js中数字存储(0.1 + 0.2 !== 0.3)
和其他编程语言(如 C 和 Java)不同,JavaScript 不区分整数值和浮点数值, 所有数字在 JavaScript 中均用浮点数值表示,遵循IEEE754标准,在进行数字运算的时候要特别注意 ...
- springboot2.0最精简的配置yml
https://blog.csdn.net/yu_hongrun/article/details/81708762
- MAC 下视频转换格式软件 之 handbrake
下载地址: https://handbrake.fr/
- 关于slf4j log4j log4j2的jar包配合使用的那些事
由于java日志框架众多(common-logging,log4j,slf4j,logback等),引入jar包的时候,就要为其添加对应的日志实现.. 不同的jar包,可能用了不同的日志框架,那引用了 ...
- C语言中内存对齐规则讨论(struct)
C语言中内存对齐规则讨论(struct) 对齐: 现代计算机中内存空间都是按着byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地 ...
- elasticsearch _create api创建一个不存在的文档
https://www.elastic.co/guide/cn/elasticsearch/guide/current/create-doc.html当我们索引一个文档, 怎么确认我们正在创建一个完全 ...
- Qt for Android (二) Qt打开android的相册
以下有一个可以用的Demo https://files.cnblogs.com/files/wzxNote/Qt-Android-Gallery-master.zip 网盘地址: https://pa ...
- LDA线性分析推广到多分类
感谢皮果提的文章: http://blog.csdn.net/itplus/article/details/12038441 http://blog.csdn.net/itplus/article 皮 ...