【模板】dijkstra与floyd
(我永远喜欢floyd)
温馨提示:与SPFA一起食用效果更佳
传送门:https://www.cnblogs.com/Daz-Os0619/p/11388157.html
Floyd
大概思路:
对于某两个点来说,查找他们之间是否连通,若连通,是记录他们间的最短路。
这里的最短路有两个方向:一个是直接到,一个是通过另外一个点到。(十分单纯的最短路了)
不需要多讲上代码!
void floyd() {
for (int k = ; k <= n; ++k)
for (int i = ; i <= n; ++i)
for (int j = ; j <= n; ++j)
dis[i][j] = min(dis[i][j], dis[i][k] + dis[k][j]);
}
Dijkstra
大概思路:
(跟SPFA差不多??)
有一个集合P,一开始只有源点S在P中,每次更新都把集合之外路径值最小的一个放入集合中,更新与它相连的点,重复前面的操作直到集合外没有元素。
特殊要求:所有边权要是正的
这时的时间复杂度为O(n*n) (比较危险)
可以采用堆来优化 时间复杂度O(n*logn)
(蒟蒻发言:怎么用堆优化?)
堆
一颗完全二叉树。
这里用到的小根堆是最小值作为堆顶元素,大根堆反之。
大概长下面这样:
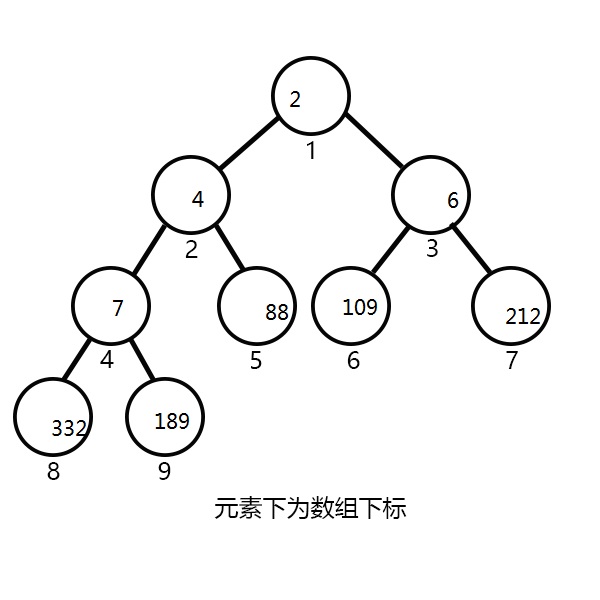
利用小根堆优化Dijkstra的理由与用SLF优化SPFA的理由相同,核心思想也相近,但是写法差异很大。
核心思想:因为每一次都会从队首开始遍历,当队首是最小值时,被更新的所以节点的值也会是最小值,这样可以节省很大一部分时间。
(这里就体现优先队列的好处)
下面是核心代码(可以先看注释,后面有图解):
struct edges {
int next, to, v;
edges() {}
edges(int _n, int _t, int _v) : next(_n), to(_t), v(_v) {}//next表示与这条边同起点的上一条边
} e[];
struct heap_node {
int v, to;
heap_node() {}
heap_node(int _v, int _to) : v(_v), to(_to) {}
};
inline bool operator < (const heap_node &a, const heap_node &b) {
return a.v > b.v; //这里实现的是小根堆,如果要大根堆,把 > 改成 < 即可
}
priority_queue <heap_node> h;
inline void add_to_heap(const int p) {
for (int x = first[p]; x; x = e[x].next)//first表示以first为头的最后一条边
if (dis[e[x].to] == -)//如果下一条边还没在堆里
h.push(heap_node(e[x].v + dis[p], e[x].to));//加上前一个点的最短路值(跟新),放入堆
}
void Dijkstra(int S) {
memset(dis, -, sizeof(dis));//清空(便于将数据放入堆里)
while (!h.empty()) h.pop();//清空堆
dis[S] = , add_to_heap(S);//现将所有与源点相连的点放入堆中
int p;
while (!h.empty()) { //堆空时所有的点都更新完毕(与SPFA相反)
if (dis[h.top().to] != -)//如果与堆顶元素相连的点已经有了最短路值
{
h.pop();//弹掉堆顶 (此时堆顶不会被更新了)
continue;//一直找到可以被更新的点
}
p = h.top().to;//找到与堆顶相连且不在堆里的点
dis[p] = h.top().v;//更新最短路值(只是堆顶的)
h.pop();//弹掉
add_to_heap(p);//再更新与它相连的点,并将与它相连的点放入堆
}
}
好长的注释啊。。
再画个图解释一下
(这里的样例和SPFA的样例一样)
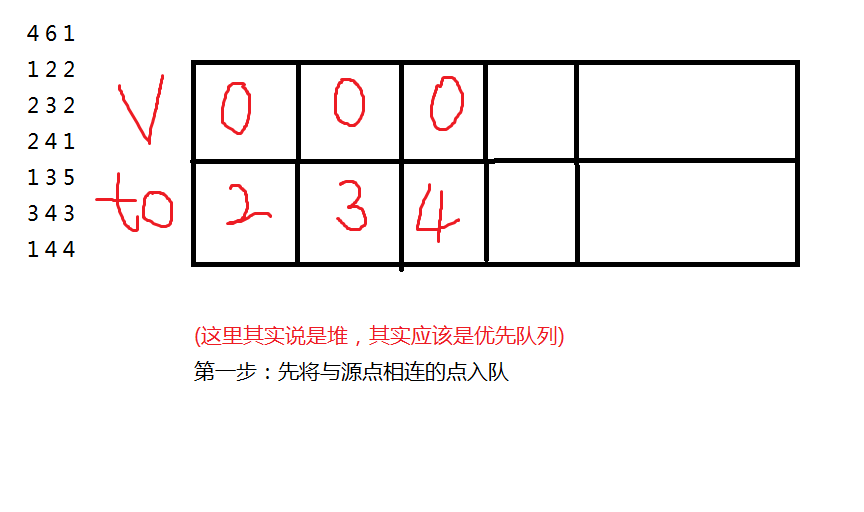
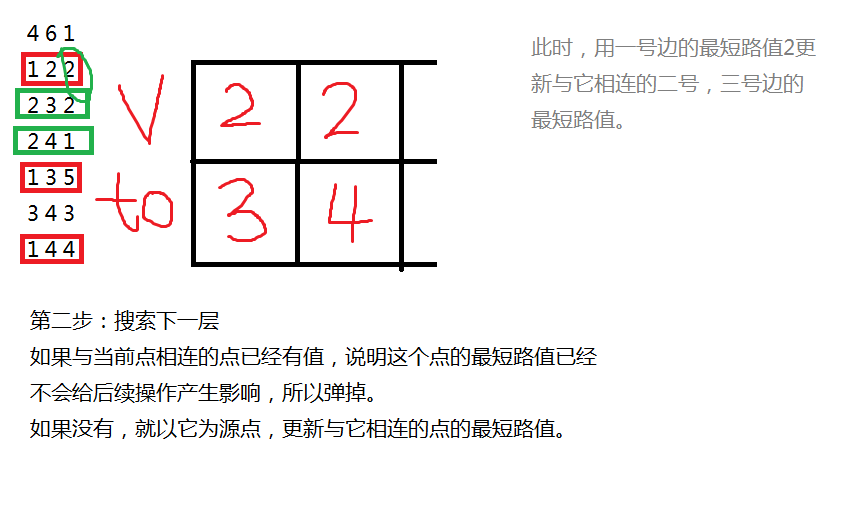

后面就这样一直循环直到队列为空。为空时所有最短路更新完毕。
完整代码:
#include<iostream>
#include<vector>
#include<queue>
#include<cstring>
#include<cstdio>
using namespace std;
struct edge
{
int next,to,v;
edge(){}
edge(int a,int b,int c)
{
next=a;
to=b;
v=c;
}
}E[];
int first[],n,dis[];
int S;
struct heap
{
int to,v;
heap(){}
heap(int a,int b)
{
to=a;
v=b;
}
};
inline bool operator< (const heap &a,const heap &b)
{
return a.v>b.v;
}
priority_queue<heap> h; void add_to_heap(int p)
{
for(int i=first[p];i;i=E[i].next)
{
if(dis[E[i].to]==-)
h.push(heap(E[i].to,dis[p]+E[i].v));
}
}
int tot;
void add_edges(int a,int b,int c)
{
E[++tot]=edge(first[a],b,c);
first[a]=tot;
}
void dijkstra(int S)
{
while(!h.empty())
h.pop();
memset(dis,-,sizeof(dis));
dis[S]=;
add_to_heap(S);
int p;
while(!h.empty())
{
if(dis[h.top().to]!=-)
{
h.pop();
continue;
}
p=h.top().to;
dis[p]=h.top().v;
h.pop();
add_to_heap(p);
}
}
int m;
int main()
{
cin>>n>>m>>S;
int A,B,C;
for(int i=;i<=m;i++)
{
cin>>A>>B>>C;
add_edges(A,B,C);
}
dijkstra(S);
for(int i=;i<=n;i++)
cout<<dis[i]<<endl;
return ;
}
结束!
今天也想放烟花!
【模板】dijkstra与floyd的更多相关文章
- (最短路径算法整理)dijkstra、floyd、bellman-ford、spfa算法模板的整理与介绍
这一篇博客以一些OJ上的题目为载体.整理一下最短路径算法.会陆续的更新... 一.多源最短路算法--floyd算法 floyd算法主要用于求随意两点间的最短路径.也成最短最短路径问题. 核心代码: / ...
- 最短路(Dijkstra,Floyd,Bellman_Ford,SPFA)
当然,这篇文章是借鉴大佬的... 最短路算法大约来说就是有4种——Dijkstra,Floyd,Bellman_Ford,SPFA 接下来,就可以一一看一下... 1.Dijkstra(权值非负,适用 ...
- 算法学习笔记(三) 最短路 Dijkstra 和 Floyd 算法
图论中一个经典问题就是求最短路.最为基础和最为经典的算法莫过于 Dijkstra 和 Floyd 算法,一个是贪心算法,一个是动态规划.这也是算法中的两大经典代表.用一个简单图在纸上一步一步演算,也是 ...
- 几个小模板:topology, dijkstra, spfa, floyd, kruskal, prim
1.topology: #include <fstream> #include <iostream> #include <algorithm> #include & ...
- dijkstra,bellman-ford,floyd分析比较
http://www.cnblogs.com/mengxm-lincf/archive/2012/02/11/2346288.html 其实我一直存在疑惑是什么导致dijkstra不能处理负权图? 今 ...
- hdu 1874 畅通工程续(模板题 spfa floyd)
题目:http://acm.hdu.edu.cn/showproblem.php?pid=1874 spfa 模板 #include<iostream> #include<stdio ...
- 最短路 dijkstra and floyd
二:最短路算法分析报告 背景 最短路问题(short-path problem):若网络中的每条边都有一个数值(长度.成本.时间等),则找出两节点(通常是源节点和阱节点)之间总权和最小的路径就是最短路 ...
- 最短路知识点总结(Dijkstra,Floyd,SPFA,Bellman-Ford)
Dijkstra算法: 解决的问题: 带权重的有向图上单源最短路径问题.且权重都为非负值.如果采用的实现方法合适,Dijkstra运行时间要低于Bellman-Ford算法. 思路: 如果存在一条从i ...
- Algorithm --> Dijkstra和Floyd最短路径算法
Dijkstra算法 一.最短路径的最优子结构性质 该性质描述为:如果P(i,j)={Vi....Vk..Vs...Vj}是从顶点i到j的最短路径,k和s是这条路径上的一个中间顶点,那么P(k,s)必 ...
随机推荐
- C#字符串和值转换 以及万能转换
2.使用万能转换器进行不同类型转换 Convert.ToXxx(object value) int iRet = Convert.ToInt32("201"); float fR ...
- 删除线性表中为x的元素的三种简单算法。
//删除线性表中不为x的元素. void delete_list(Sqlist &L,int x){ ; ;i < L.length;i++){ if(L.data[i] != x){ ...
- mounted里面this.$refs.xxx的内容是undefined
在mounted(){}钩子里面使用this.$refs.xxx,打印出来的却是undefined? DOM结构已经渲染出来了,但是如果在DOM结构中的某个DOM节点使用了v-if.v-show或者v ...
- 总结调试webview的方式(安卓)
参考文章: 移动端真机调试指南 Mac 平台 Android 使用 Charles 抓包方法 Charles使用Map Local和Rewrite提高开发效率 通过chrome直接进行调试 chrom ...
- Oracle用户被锁解决方法
.查看用户的proifle是哪个,一般是default: sql>SELECT username,PROFILE FROM dba_users; .查看指定概要文件(如default)的密码有效 ...
- 【零基础】快速入门爬虫框架HtmlUnit
迅速的HtmlUnit htmlunit是一款开源的web页面分析工具,理论上来说htmlunit应用于网页的自动化测试,但是相对来说更多人使用它来进行小型爬虫的快速开发.使用htmlunit进行爬虫 ...
- pytorch-VGG网络
VGG网络结构 第一层: 3x3x3x64, 步长为1, padding=1 第二层: 3x3x64x64, 步长为1, padding=1 第三层: 3x3x64x128, 步长为1, paddin ...
- Springboot整合 mybatis-generator
1.pom.xml文件中 生成依赖 <plugin> <groupId>org.mybatis.generator</groupId> <artifactId ...
- handler定义
Handler主要接收子线程发送的数据, 并用此数据配合主线程更新UI,用来跟UI主线程交互用.比如可以用handler发送一个message,然后在handler的线程中来接收.处理该消息,以避免直 ...
- docker 安装 jmeter
1.下载jmeterwget http://mirrors.tuna.tsinghua.edu.cn/apache//jmeter/binaries/apache-jmeter-5.1.1.tgz2. ...