AC3 encoder flow
AC3 encoder flow 如下:
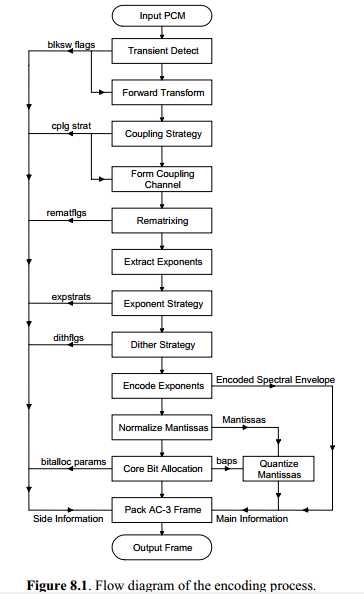
1.input PCM
PCM在进入encoder前会使用high pass filter来移除信号的DC部分来达到更有效的编码。
2.Transient detection
Transient detection用于决定在进行MDCT时是否需要switch到short block来减少pre-echo。
Transient detection 分为以下几个步骤:
1)High pass filter.使用二阶IIR filter (cutoff of 8kHz)。
2)Block Segmentation.
一个audio block(256 sample)通过HP filter后,segmented 到hierarchical tree的不同level上。
level 1为256 sample. level 2为2个长度为128 sample 的segment.level3 为4个长度为64 sample的segment.
3)Peak detection
在hierarchical tree的各个level的各个segment上找到最大PCM的最大幅值。
P[j][k] = max(x(n))
for n = (512 ×(k-1) / 2^j), (512 ×(k-1) / 2^j) + 1, ...(512 ×k / 2^j) - 1
and k = 1, ..., 2^(j-1) ;
其中x(n)为256 sample 的audio block 中第n个sample
j=1,2,3 为hierachical tree的level
k为level j的segment index.
4)Thread Comparison
首先用P[1][1]与“silence threshold”进行比较来check当前audio block中是否存在signifant signal level.
如果P[1][1]小于silence threshold则使用long block. silence threshold为100/32768
接下来,在每个level上比较相邻的segment的Peak.如果相邻的两个segment Peak的比值大于预设的threshold,就设置一个flag来标识当前audio block存在transient.
比较方法如下:
mag(P[j][k]) ×T[j] > mag(P[j][(k-1)])
T[j]是level j预设的threshold.T[1]=0.1,T[2]=0.075,T[3]=0.05.
3.Forward Transform
每个audio block在进行MDCT transform之前,需要乘以window function来减少transform的边界效应。
使用MDCT进行时频变换。
x[n]表示乘以window function之后的时域信号,如果使用long block,N=512.如果使用short block, N=256.
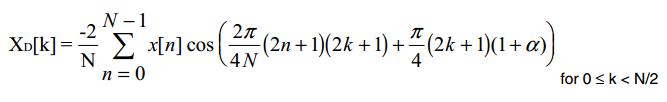

4.Coupling Strategy
1)basis encoder
basic encoder 使用static coupling strategy, couplig parameter 如下:

2)advanced encoder
更多的advanced encoder使用动态变化的coupling parameter. coupling frequecies根据psychoacoustic model 分析bit 的需求量来动态变化。
如果某个channel的信号在时间上变化剧烈,就从coupling中移除。在时间上变化缓慢的channel,其coupling coordinate传送bit少很多。
coupling band structure也会动态变化。
5.Form Coupling Channel
大部分basic encoder将所有individual channel的transform coefficients简单的相加,然后除以8(防止transform coefficients超过1溢出)形成coupling channel。
一些稍微复杂点的encoder在进行相加钱会改变individual channel的符号来避免phase cancellations.
在每个coupling band内,原始channel的能量除以coupling channel中对应coupling band内能量的比值形成coupling coordinates.
6.Rematrixing
Rematrixing只存在于2/0 mode.在每个rematrixing band内,计算L,R,L-R,L+R的能量,如果最大的能量是L or R,那当前band不设置rematrixing flag.如果最大的能量是L+R orL- R,那当前band设置rematrixing flag,并传送L+R,L-R.
7.Extract exponent
将transform coefficient表示成二进制后,leading zero的个数为初始的exponent.
每个transform coefficients计算出一个exponent,可以选择不同的exponent strategy将多个exponent group在一起。
8.Exponent Strategy
如果频谱变化平坦,则使用D25 or D45,如果变化不平坦,这是用频谱分辨率较高的exponent strategy D15 or D25.
如果频谱在一个frame的6个audio block内改变很小,则只在audio block 0传送exponents, block 1~5使用block 0的exponents.
对于basic encoder,check时间上exponents的变化,如果变化超过了一个threshold,那么就传送新的exponent。
9.Dither strategy
当transform coefficient被quantize为0bit时,在decoder端使用dither替代transform coefficients.
10.Encoder Exponents
对于exponent strategy D25,D45,一个exponent对应多个mantissa. exponent采用差分编码。两个相邻的exponent的差值被限定为+/-2内,如果相邻的exponent差值大于2,则减少较大的exponent到+/-2范围内,相应的mantissa经调整后包含leading zero.
11.Normalize mantissa
每个channel的transform coefficients根据exponents左移得到normalized mantissa.
12.Core Bit Allocation
Core bit allocation是通过不断调整corse SNR 和fine SNR offset直到一个frame内的所有可用的bit都分配完。
corse SNR offset调整时每次增加/减少3db,fine SNR offset 调整时每次增加/减少3/16db.
对于所有channel,都是 从一个common bit pool来进行bit allocation。在encoder通过不断的迭代选择最优的csnroffst 和fineoffst,分配不超过frame size的最大bit 数。
对于某一次迭代,如果分配的bit数超过了bit pool,那么减小SNR offset来进行下一次迭代。如果分配的bit数小于bit pool,那么增加SNR offset来进行下一次迭代。当SNR offset已经是满足分配bit数不超过bit pool的最大值时,迭代结束。
bit allocation的最终结果是csnroffst,fineoffst和baps(bit allocation points)
13. Quantize mantissa
每个normallized mantissa使用对应bap的quantizer进行quantize.
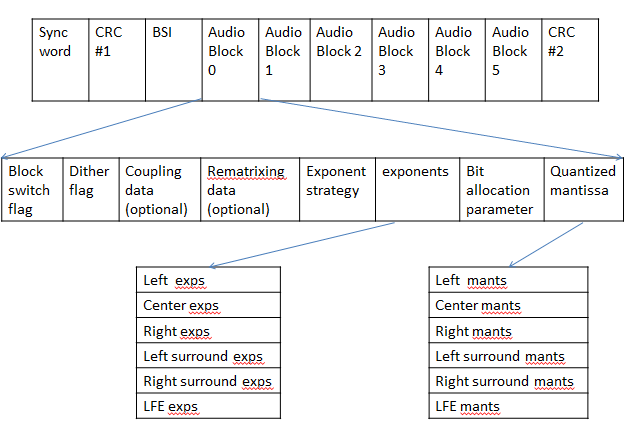
14.Pack AC-3 Frame
将上述过程产生的side info,exponents和quantized mantissa pack成AC-3 frame
AC3 encoder flow的更多相关文章
- AC3 IMDCT
AC3 encoder 在进行MDCT时,使用两种长度的block. 512 samples的block用于输入信号频谱是stationary,或者在时间上变化缓慢.在fs 为48k时,使用512 s ...
- AC3 Rematrix
当L R channel highly correlated时,AC3 encoder 使用rematrix技术压缩L/R的和和差. 原始信号为left,right,使用rematrix压缩信号为le ...
- AC3 overview
1.AC3 encode overview AC3 encoder的框图如下: AC3在频域采用粗量化(coarsely quantizing)来获取较高的压缩率. 1).输入PCM 经过MDCT变换 ...
- ffmpeg最全的命令参数
Hyper fast Audio and Video encoderusage: ffmpeg [options] [[infile options] -i infile]... {[outfile ...
- Motion control encoder extrapolation
Flying Saw debug Part1 Encoder extrapolation Machine introduction A tube cutting saw, is working for ...
- 光流法(optical flow)
光流分为稠密光流和稀疏光流 光流(optic flow)是什么呢?名字很专业,感觉很陌生,但本质上,我们是最熟悉不过的了.因为这种视觉现象我们每天都在经历.从本质上说,光流就是你在这个运动着的世界里感 ...
- Improved Variational Inference with Inverse Autoregressive Flow
目录 概 主要内容 代码 Kingma D., Salimans T., Jozefowicz R., Chen X., Sutskever I. and Welling M. Improved Va ...
- Improving Variational Auto-Encoders using Householder Flow
目录 概 主要内容 代码 Tomczak J. and Welling M. Improving Variational Auto-Encoders using Householder Flow. N ...
- Git 在团队中的最佳实践--如何正确使用Git Flow
我们已经从SVN 切换到Git很多年了,现在几乎所有的项目都在使用Github管理, 本篇文章讲一下为什么使用Git, 以及如何在团队中正确使用. Git的优点 Git的优点很多,但是这里只列出我认为 ...
随机推荐
- 树莓派环境下使用python将h264格式的视频转为mp4
个人博客 地址:https://www.wenhaofan.com/a/20190430144809 下载安装MP4Box 命令行下执行以下指令安装MP4Box sudo apt-get inst ...
- vue之项目打包部署到服务器
这是今年的第一篇博客.整理一下vue如何从项目打包到部署服务器,给大家做下分享,希望能给大家带来或多或少的帮助,喜欢的大佬们可以给个小赞,如果有问题也可以一起讨论下. 第一步:这是很关键的一步.打开项 ...
- [tensorflow] tf.gather使用方法
tf.gather:用一个一维的索引数组,将张量中对应索引的向量提取出来 import tensorflow as tf a = tf.Variable([[1,2,3,4,5], [6,7,8,9, ...
- 拦截器 Filter : js、css、jpg、png等静态资源不被拦截解决方案
方案一: web.xml配置文件拦截范围缩小 ,没有必要 /*的配置拦截项目下所有资源. <filter> <filter-name>Login</filter-name ...
- Verilog-异步FIFO
参考博文:https://blog.csdn.net/alangaixiaoxiao/article/details/81432144 1.概述 异步FIFO设计的关键是产生“写满”和“读空”信号,这 ...
- 微信小程序CSS之Flex布局
转载:https://blog.csdn.net/u012927188/article/details/83040156 相信刚开始学习开发小程序的初学者一定对界面的布局很困扰,不知道怎么布局,怎么摆 ...
- Public Key Retrieval is not allowed
链接MySQL数据库报错: 数据库连接url中添加对应属性的支持.allowPublicKeyRetrieval=true&useSSL=false url: jdbc:mysql://loc ...
- PP: Sequence to sequence learning with neural networks
From google institution; 1. Before this, DNN cannot be used to map sequences to sequences. In this p ...
- C++——动态内存分配2-创建对象数组
//创建对象数组 #include<iostream> using namespace std; class Point { public: Point() { ...
- RN开发-Linux开发环境搭建(Ubuntu 12.04)
1.首先安装JDK 2.安装Android开发环境 3.安装node.js 3.1 官网下载 : node-v6.9.1-linux-x64 3.2 添加环境变量 sudo vi /etc/profi ...