SVM-支持向量机(三)SVM回归与原理
SVM回归
我们之前提到过,SVM算法功能非常强大:不仅支持线性与非线性的分类,也支持线性与非线性回归。它的主要思想是逆转目标:在分类问题中,是要在两个类别中拟合最大可能的街道(间隔),同时限制间隔侵犯(margin violations);而在SVM回归中,它会尝试尽可能地拟合更多的数据实例到街道(间隔)上,同时限制间隔侵犯(margin violation,也就是指远离街道的实例)。街道的宽度由超参数ϵ控制。下图展示的是两个线性SVM回归模型在一些随机线性数据上训练之后的结果,其中一个有较大的间隔(ϵ = 1.5),另一个的间隔较小(ϵ = 0.5)。
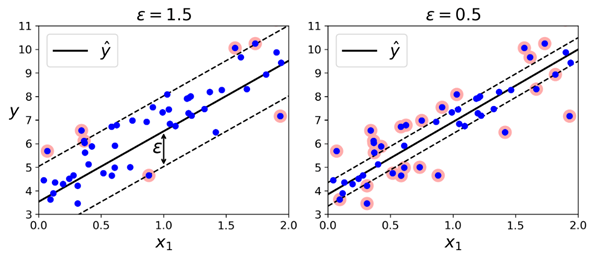
如果后续增加的训练数据包含在间隔内,则不会对模型的预测产生影响,所以这个模型也被称为是ϵ-insensitive。
我们可以使用sk-learn的LinearSVR类训练一个SVM回归,下面的代码对应的是上图中左边的模型(训练数据需要先做缩放以及中心化的操作,中心化又叫零均值化,是指变量减去它的均值。其实就是一个平移的过程,平移后所有数据的中心是(0, 0)):
from sklearn.svm import LinearSVR svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)
再处理非线性的回归任务时,也可以使用核化的SVM模型。例如,下图展示的是SVM回归在一个随机的二次训练集上的表现,使用的是二阶多项式核:
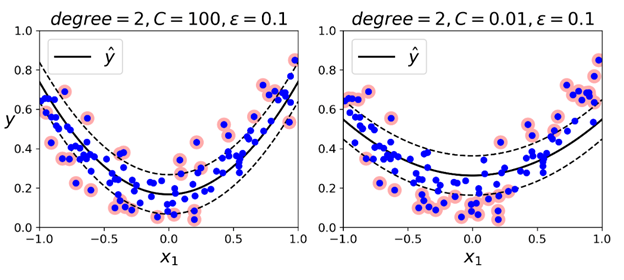
左边的图中有一个较小的正则(超参数C的值较大),而右边图中的正则较大(较小的C值)。
下面的代码上图中左边的图对应的模型,使用的是sk-learn SVR类(支持核方法)。SVR类等同于分类问题中的SVC类,并且LinearSVR类等同于分类问题中的LinearSVC类。LinearSVR类会随着训练集的大小线性扩展(与LinearSVC类一样);而SVR类在训练集剧增时,速度会严重下降(与SVC类一致):
from sklearn.svm import SVR svm_poly_reg = SVR(kernel='poly', degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
SVMs也可以用于异常点(值)检测,具体可以参考sk-learn文档。
原理解释
在这章我们会解释SVM如何做预测,以及训练算法是如何工作的,先从线性SVM分类器开始。
首先,我们将所有的模型参数放入一个向量θ,包括偏置项参数θ0以及输入特征的权重θ1 到 θn,并且给所有数据实例增加一个偏置项x0 = 1。这里偏置项称为b,特征权重向量称为w。
决策方法与预测
线性SVM分类器模型在做预测时,对于输入的实例x,它会计算决策函数wTx + b = w1x1 + ⋯ + wnxn + b:如果结果是正的,则预测的类别ŷ就属于正类(1),否则属于反类(0),如下公式所示:
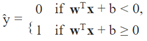
下面我们看一下SVM在之前iris数据集上训练后的决策函数图:
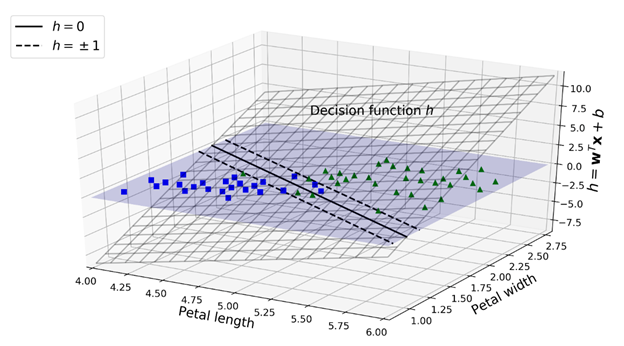
这是一个二维平面,因为数据集有两个特征(petal width与petal length)。决策边界是由那些让决策函数等于0的点组成:也就是两个平面的交线(由上图中实线表示)。
虚线代表的是令决策函数等于1或-1的点:这两条虚线平行且距决策边界的距离相等,组成了一个间隔。训练线性SVM分类器就是找到一对w与b的值,让这个间隔尽可能的宽的同时,还要避免或是限制间隔侵犯(margin violation)。避免间隔侵犯的结果就是硬间隔(hard margin),限制间隔侵犯的结果就是软间隔(soft margin)。
训练目标
上图的例子中我们看到这个决策函数的图像是一个平面,并且有一个坡度。这个坡度等同的是权重向量w的范数(norm):∥ w ∥。如果我们将这个坡度除以2,则那些令决策函数等于±1 的点会离决策边界两倍远。换句话说,坡度除以2会让间隔增加2倍。如下图所示:
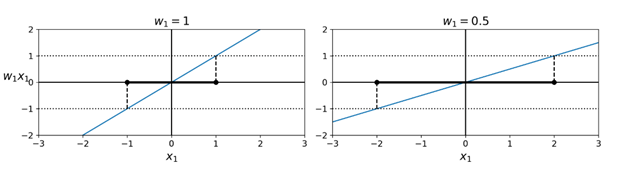
所以我们希望最小化 ∥ w ∥ 的值以获取一个更大的间隔。不过,如果我们同时也希望避免间隔入侵(硬间隔),则我们需要让决策函数对所有训练数据中的“正”训练实例计算结果大于1,而对所有“负”训练实例的计算结果小于-1。如果我们对负实例(也就是y(i) = 0)定义t(i) = –1,对正实例(y(i) = 1)定义t(i) = 1,则我们可以使用约束t(i)(wT x(i) + b) ≥ 1 定义所有实例。
所以我们接下来可以将硬间隔SVM分类器目标表示为一个带约束的优化问题,如下公式:
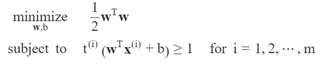
这里可以看到,我们优化的不是∥ w ∥,而是½wTw,它等同于½∥ w ∥2。因为½∥ w ∥2的导数非常简单(也就是w),而∥ w ∥ 在w=0时不可微。优化算法在可微函数上工作效果更好。
为了达到软间隔(soft margin)目标,我们需要为每个实例i引入一个松弛变量ζ(i) ≥ 0,这个变量衡量的是第ith个实例被允许入侵间隔的程度。我们现在有两个冲突的目标:让松弛变量尽可能的小,以减少间隔入侵;同时还要让 ½∥ w ∥2 尽可能的小,以增加间隔。所以这就是为什么算法中引入超参数C:这个参数可以让我们定义这两个目标之间的权衡(tradeoff)。对应的带约束优化问题为:
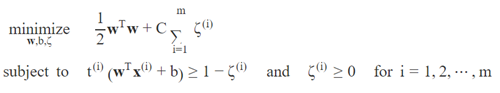
二次规划
硬间隔与软间隔问题都是带线性约束的凸二次优化问题,这种就是常说的二次规划(Quadratic Programming,QP)问题。有很多现成的解决办法用于解决QP问题,在这不会深入讨论。这种常规问题的公式如下所示:

需要注意的是表达式Ap ≤ b 定义了nc的约束:p⊺ a(i) ≤ b(i) for i = 1, 2, ⋯, nc, 这里a(i)代表的是包含了A的第ith行的向量,b(i)代表的是b的ith第个元素。
如果我们按下面的参数设置QP参数,则可以得到硬间隔线性SVM分类器的目标:

一个训练硬间隔线性SVM分类器的方法是使用已有的OP问题解决方法,传入上述参数即可。求得的结果向量p会包含偏执项b=p0,以及特征权重wi = pi for i = 1, 2, ⋯, n。类似的,也可以使用QP问题解决方案解决软间隔问题。
不过在使用核方法时,我们会使用另一个不同的带约束的优化问题。
在线SVM(online SVM)
在这章结束之前,我们快速地看一下在线SVM分类器(在线学习是指递增的训练,一般在一个新实例到达时就训练一次)。
对于线性SVM分类器,一种方法是使用梯度下降(例如使用SGDClassifier)最小化以下损失函数:
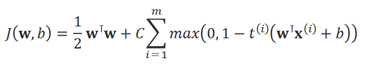
这个损失函数是由原始问题推导得出,但是它的收敛速度相比基于QP方法的收敛会慢特别多。在这个损失函数中,第一个累加会推进模型去找一个较小的权重向量w,继而产生一个更大的间隔。第二个累加会计算所有的间隔入侵(margin violations)。一个实例如果是远离街道、且在它所属正确的那一侧,则它的间隔入侵为0;否则它的间隔入侵则为距离正确那一侧街道的距离的比例。最小化这个项,会确保模型尽可能少地造成间隔入侵。
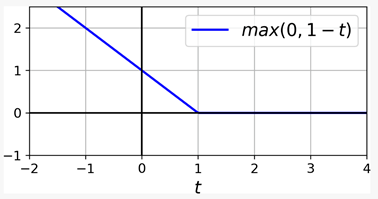
最后提一下HINGE LOSS,我们之前在训练SVM时使用的是这个损失函数。它的函数为max(0, 1-t)。在 t ≥ 1时,输出为0。它的导数在t < 1 时等于 -1,在t > 1 时等于0 ;在t=1时不可微,不过仍可以在使用梯度下降时,使用t=1 时的任何次导数(也就是说,任何在-1到0之间的值)。函数图如下:
在在线SVM中,也是可以实现在线核化SVM的,例如使用“Incremental and Decremental SVM Learning” 或”Fast Kernel Classifiers with Online and Active Learning”。不过这些是通过Matlab和C++实现的。对于大型的非线性问题,我们其实可以考虑使用神经网络。
SVM-支持向量机(三)SVM回归与原理的更多相关文章
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- 机器学习算法与Python实践之(三)支持向量机(SVM)进阶
机器学习算法与Python实践之(三)支持向量机(SVM)进阶 机器学习算法与Python实践之(三)支持向量机(SVM)进阶 zouxy09@qq.com http://blog.csdn.net/ ...
- 机器学习--支持向量机 (SVM)算法的原理及优缺点
一.支持向量机 (SVM)算法的原理 支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析.它是将向量映射到一个更高维的 ...
- 支持向量机(SVM)原理阐述
支持向量机(Support Vector Machine, SVM)是一种二分类模型.给定训练集D = {(x1,y1), (x2,y2), ..., (xm,ym)},分类学习的最基本的想法即是找到 ...
- 4. 支持向量机(SVM)原理
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- 支持向量机(SVM)、支持向量回归(SVR)
1.支持向量机( SVM )是一种比较好的实现了结构风险最小化思想的方法.它的机器学习策略是结构风险最小化原则 为了最小化期望风险,应同时最小化经验风险和置信范围) 支持向量机方法的基本思想: ( 1 ...
- 支持向量机(SVM)
断断续续看了好多天,赶紧补上坑. 感谢july的 http://blog.csdn.net/v_july_v/article/details/7624837/ 以及CSDN上淘的比较正规的SMO C+ ...
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
机器学习算法与Python实践之(四)支持向量机(SVM)实现 机器学习算法与Python实践之(四)支持向量机(SVM)实现 zouxy09@qq.com http://blog.csdn.net/ ...
- SVM(支持向量机)算法
第一步.初步了解SVM 1.0.什么是支持向量机SVM 要明白什么是SVM,便得从分类说起. 分类作为数据挖掘领域中一项非常重要的任务,它的目的是学会一个分类函数或分类模型(或者叫做分类器),而支持向 ...
随机推荐
- JS杨辉三角形
题目:打印出杨辉三角形(要求打印出10行如下图) 1 1 1 1 2 1 1 3 3 1 1 4 6 4 1 1 5 10 10 5 1 分析: 1.第1列或列数=行数时,value=1 2.其余的值 ...
- c# 匿名方法(函数) 匿名委托 内置泛型委托 lamada
匿名方法:通过匿名委托 .lamada表达式定义的函数具体操作并复制给委托类型: 匿名委托:委托的一种简单化声明方式通过delegate关键字声明: 内置泛型委托:系统已经内置的委托类型主要是不带返回 ...
- Flink知识散点
1.KeyBy 操作后,只有当 Key 的数量大于算子的并发实例数才能获得较好的计算性能. A.而若Key 的数量比实例数量少,就会导致部分实例收不到数据,这些实例就得不到执行,这些实例的计算能力得不 ...
- Bounce 弹飞绵羊 HYSBZ - 2002 分块
//预处理出以这个点为起点并跳出这个块的次数和位置 //更新一个点的弹力系数可以只更新这个点以及这个块内之前的点 #include<stdio.h> #include<algorit ...
- ArcGIS Runtime SDK for Android 加载shp数据,中文乱码问题
针对ArcGIS10.2版本的解决办法(默认中文编码为OEM): 现有一个图层名称为“图层.shp”,以此为例: 1.拷贝一个cpg文件,修改名称为“图层.cpg”,并用文本打开cpg文件修改编码为“ ...
- Android_向用户发送短信
一段代码,用的时候copy就行 记得在manifest里声明send-sms和read-sms权限 public class SendMsgActivity extends AppCompatActi ...
- 关键字Lock的简单小例子
一.什么是Lock? Lock——字面上理解就是锁上:锁住:把……锁起来的意思: 为什么要锁?要锁干什么?——回到现实中可想象到,这个卫生间我要上,其他人不要进来!(所以我要锁住门):又或者土味情话所 ...
- LNMP环境配置(2)
php-fpm配置,Nginx配置 Nginx配置 默认虚拟主机 修改主配置文件 # vi /usr/local/nginx/conf/nginx.conf 在最后 } 符号上面写入 includ ...
- Photoshop Elements2020强势来袭,教你三秒钟拯救闭眼照
Photoshop Elements2020强势来袭,一系列的黑科技让设计师和路人都惊叹不已!若某人的闭眼成为一张集体照的败笔,那该如何挽回? 想要挽救闭眼照?听起来很高大上,很困难?不,Photos ...
- Zabbbix之十二------Zabbix实现微信报警通知及创建聚合图形
实战一:实现zabbix监控微信报警 1.在企业微信上注册账号 1.注册企业微信,管理员需要写上自己的真实姓名,扫描以下的二维码,与微信关联真实姓名. 2.登陆企业微信,然后创建一个微信故障通知应用 ...