spark session 深入理解
spark 1.6 创建语句
在Spark1.6中我们使用的叫Hive on spark,主要是依赖hive生成spark程序,有两个核心组件SQLcontext和HiveContext。
这是Spark 1.x 版本的语法
//set up the spark configuration and create contexts
val sparkConf = new SparkConf().setAppName("SparkSessionZipsExample").setMaster("local")
// your handle to SparkContext to access other context like SQLContext
val sc = new SparkContext(sparkConf).set("spark.some.config.option", "some-value")
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
而Spark2.0中我们使用的就是sparkSQL,是后继的全新产品,解除了对Hive的依赖。
从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6中的SQLcontext和HiveContext
来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。
我们在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。
然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
创建SparkSession
SparkSession 是 Spark SQL 的入口。
使用 Dataset 或者 Datafram 编写 Spark SQL 应用的时候,第一个要创建的对象就是 SparkSession。
Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置。
Builder 的方法如下:
| 方法 | 说明 |
| getOrCreate | 获取或者新建一个 sparkSession |
| enableHiveSupport | 增加支持 hive Support |
| appName | 设置 application 的名字 |
| config | 设置各种配置 |
你可以通过 SparkSession.builder 来创建一个 SparkSession 的实例,并通过 stop 函数来停止 SparkSession。
import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder
.appName("demo") // optional and will be autogenerated if not specified
.master("local[1]") // avoid hardcoding the deployment environment
.enableHiveSupport() // self-explanatory, isn't it?
.config("spark.sql.warehouse.dir", "/user/hive")
.getOrCreate // 停止
spark.stop()
这样我就就可以使用我们创建的SparkSession类型的spark对象了。
设置spark参数
创建SparkSession之后可以通过 spark.conf.set 来设置运行参数
//set new runtime options
spark.conf.set("spark.sql.shuffle.partitions", 6)
spark.conf.set("spark.executor.memory", "2g")
//get all settings
val configMap:Map[String, String] = spark.conf.getAll()//可以使用Scala的迭代器来读取configMap中的数据。
读取元数据
如果需要读取元数据(catalog),可以通过SparkSession来获取。
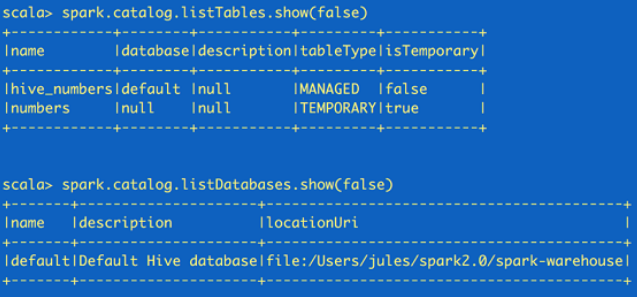
//fetch metadata data from the catalog
spark.catalog.listDatabases.show(false)
spark.catalog.listTables.show(false)
这里返回的都是Dataset,所以可以根据需要再使用Dataset API来读取。
注意:catalog 和 schema 是两个不同的概念
Catalog是目录的意思,从数据库方向说,相当于就是所有数据库的集合;
Schema是模式的意思, 从数据库方向说, 类似Catelog下的某一个数据库;
创建Dataset和Dataframe
通过SparkSession来创建Dataset和Dataframe有多种方法。
最简单的就是通过range()方法来创建dataset,通过createDataFrame()来创建dataframe。
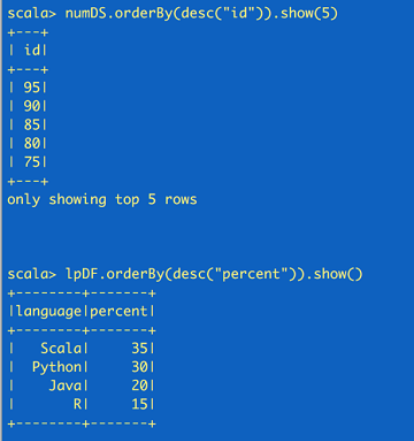
//create a Dataset using spark.range starting from 5 to 100, with increments of 5
val numDS = spark.range(5, 100, 5)//创建dataset
// reverse the order and display first 5 items
numDS.orderBy(desc("id")).show(5)
//compute descriptive stats and display them
numDs.describe().show()
// create a DataFrame using spark.createDataFrame from a List or Seq
val langPercentDF = spark.createDataFrame(List(("Scala", 35), ("Python", 30), ("R", 15), ("Java", 20)))//创建dataframe
//rename the columns
val lpDF = langPercentDF.withColumnRenamed("_1", "language").withColumnRenamed("_2", "percent")
//order the DataFrame in descending order of percentage
lpDF.orderBy(desc("percent")).show(false)
读取外部数据
可以用SparkSession读取JSON、CSV、TXT和parquet表。
import spark.implicits //使RDD转化为DataFrame以及后续SQL操作
//读取JSON文件,生成DataFrame
val df= spark.read.format("json").json(path)
使用Spark SQL语言
借助SparkSession用户可以像SQLContext一样使用Spark SQL的全部功能。
df.createOrReplaceTempView("tmp")//对上面的dataframe创建一个表
df.cache()//缓存表
val resultsDF = spark.sql("SELECT city, pop, state, zip FROM tmp")//对表调用SQL语句
resultsDF.show(10)//展示结果
存储/读取Hive表
下面的代码演示了通过SparkSession来创建Hive表并进行查询的方法。
/drop the table if exists to get around existing table error
spark.sql("DROP TABLE IF EXISTS zips_hive_table")
//save as a hive table
spark.table("zips_table").write.saveAsTable("zips_hive_table")
//make a similar query against the hive table
val resultsHiveDF = spark.sql("SELECT city, pop, state, zip FROM zips_hive_table WHERE pop > 40000")
resultsHiveDF.show(10)
sparkSession的类和方法
| 方法 | 说明 |
| builder | 创建一个sparkSession实例 |
| version | 返回当前spark的版本 |
| implicits | 引入隐式转化 |
| emptyDataset[T] | 创建一个空DataSet |
| range | 创建一个DataSet[Long] |
| sql | 执行sql查询(返回一个dataFrame) |
| udf | 自定义udf(自定义函数) |
| table | 从表中创建DataFrame |
| catalog | 访问结构化查询实体的目录 |
| read | 外部文件和存储系统读取DataFrame。 |
| conf | 当前运行的configuration |
| readStream | 访问DataStreamReader以读取流数据集。 |
| streams | 访问StreamingQueryManager以管理结构化流式传输查询。 |
| newSession | 创建新的SparkSession |
| stop | 停止SparkSession |
| write | 访问DataStreamReader以写入流数据集。 |
参考: https://www.cnblogs.com/zzhangyuhang/p/9039695.html
spark session 深入理解的更多相关文章
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- ECshop中的session机制理解
ECshop中的session机制理解 在网上找了发现都是来之一人之手,也没有用自己的话去解释,这里我就抛砖引玉,发表一下自己的意见,还希望能得到各界人士的指导批评! 此session机制不需 ...
- php中session的理解
一.Session是什么 Session一般译作会话,牛津词典对其的解释是进行某活动连续的一段时间.从不同的层面看待session,它有着类似但不完全同样的含义.比方,在web应用的用户看来,他打开浏 ...
- 整理对Spark SQL的理解
Catalyst Catalyst是与Spark解耦的一个独立库,是一个impl-free的运行计划的生成和优化框架. 眼下与Spark Core还是耦合的.对此user邮件组里有人对此提出疑问,见m ...
- php session的理解【转】
目录 1.什么是session? 2.Session常见函数及用法? ● 如何删除session? ● SESSION安全: Session跨页传递问题: 1.什么是session? Sessio ...
- Spark Job-Stage-Task实例理解
Spark Job-Stage-Task实例理解 基于一个word count的简单例子理解Job.Stage.Task的关系,以及各自产生的方式和对并行.分区等的联系: 相关概念 Job:Job是由 ...
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- Failed to create Spark client for Spark session
最近在hive里将mr换成spark引擎后,执行插入和一些复杂的hql会触发下面的异常: org.apache.hive.service.cli.HiveSQLException: Error whi ...
- Spark核心概念理解
本文主要内容来自于<Hadoop权威指南>英文版中的Spark章节,能够说是个人的翻译版本号,涵盖了基本的Spark概念.假设想获得更好地阅读体验,能够訪问这里. 安装Spark 首先从s ...
随机推荐
- STM32库中自定义的数据类型
在头文件 <stdint.h> 中 1 /* exact-width signed integer types */ typedef signed char int8_t; typedef ...
- Java-Class-C:com.github.pagehelper.PageHelper
ylbtech-Java-Class-C:com.github.pagehelper.PageHelper 1.返回顶部 2.返回顶部 1.1. import com.github.pagehel ...
- Django+telnetlib实现webtelnet
说明 基于 python3.7 + django 2.2.3 实现的 django-webtelnet.有兴趣的同学可以在此基础上稍作修改集成到自己的堡垒机中. 项目地址:https://github ...
- CodeForces1249E-By Elevator or Stairs?-好理解自己想不出来的dp
Input The first line of the input contains two integers nn and cc (2≤n≤2⋅105,1≤c≤10002≤n≤2⋅105,1≤c≤1 ...
- The Preliminary Contest for ICPC Asia Nanjing 2019( B H F)
B. super_log 题意:研究一下就是求幂塔函数 %m的值. 思路:扩展欧拉降幂. AC代码: #include<bits/stdc++.h> using namespace std ...
- JS:面向对象(进阶篇)
组合使用构造函数和原型模式 构造函数模式用于定义实例属性,而原型模式用于定义方法和共享属性.结果,每个实例都会有自己的一份实例属性的副本,但同时又共享这对方法的引用,最大限度的节省了内存. funct ...
- Spring MVC源码分析(二):SpringMVC的DispatcherServlet的设计与实现
概述 DispatcherServlet是SpringMVC的一个前端控制器,是MVC架构中的C,即controller的实现,用于拦截这个web应用的所有请求,具体为在web.xml中配置这个s ...
- 1-Navicat无法远程连接Ubuntu上的MySQL(已解决)
转发自: https://jingyan.baidu.com/article/4d58d54156ff069dd4e9c085.html
- 关于js 重载
拜读js忍者修炼一书 读到关于js函数重载内容这个模块 主要是介绍通过js的访问argument这个参数来实现js函数的重载 通过在函数内部进行判断js argument参数的长度 代码如下所示 va ...
- Mac上Chrome浏览器跨域解决方案
现在比较新的浏览器在本地调试时AJAX请求,基本都会有跨域问题.相应的解决方案也挺多的,工具也不少.像charles等抓包工具等.不过最简单的就是移除浏览器的同源限制. 我们要做的第一步,就是创建一个 ...