第三十篇 玩转数据结构——字典树(Trie)
- Trie的形象化描述如下图:
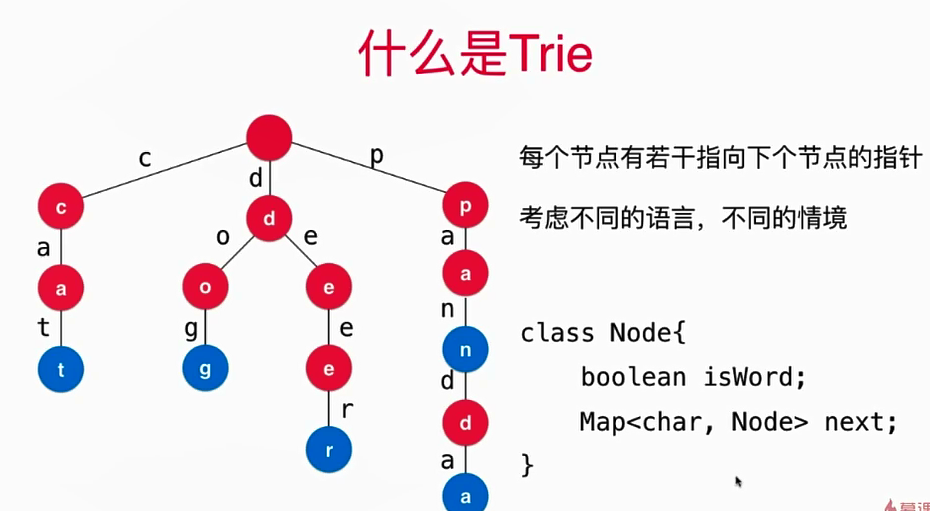
- Trie的优势和适用场景

- 实现Trie的业务无逻辑如下:
import java.util.TreeMap; public class Trie { private class Node { public boolean isWord;
public TreeMap<Character, Node> next; // 构造函数
public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
} // 无参数构造函数
public Node() {
this(false);
}
} private Node root;
private int size; // 构造函数
public Trie() {
root = new Node();
size = 0;
} // 实现getSize方法,获得Trie中存储的单词数量
public int getSize() {
return size;
} // 实现add方法,向Trie中添加新的单词word
public void add(String word) { Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
if (!cur.isWord) {
cur.isWord = true;
size++;
}
} // 实现contains方法,查询Trie中是否包含单词word
public boolean contains(String word) { Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
return false;
}
cur = cur.next.get(c);
}
return cur.isWord; // 好聪明
} // 实现isPrefix方法,查询Trie中时候保存了以prefix为前缀的单词
public boolean isPrefix(String prefix) { Node cur = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (cur.next.get(c) == null) {
return false;
}
cur = cur.next.get(c);
}
return true;
}
}
3.. Trie和简单的模式匹配
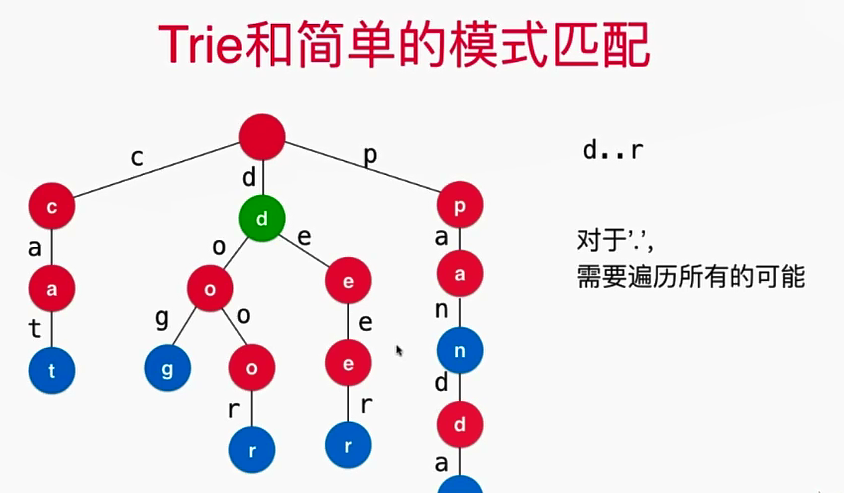
- 实现的业务逻辑如下:
import java.util.TreeMap; class WordDictionary { private class Node { public boolean isWord;
public TreeMap<Character, Node> next; public Node(boolean isWord) {
this.isWord = isWord;
next = new TreeMap<>();
} public Node() {
this(false);
} } /**
* Initialize your data structure here.
*/
private Node root; public WordDictionary() {
root = new Node();
} /**
* Adds a word into the data structure.
*/
public void addWord(String word) {
Node cur = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (cur.next.get(c) == null) {
cur.next.put(c, new Node());
}
cur = cur.next.get(c);
}
cur.isWord = true;
} /**
* Returns if the word is in the data structure. A word could contain the dot character '.' to represent any one letter.
*/
public boolean search(String word) {
return match(root, word, 0);
} private boolean match(Node node, String word, int index) {
if (index == word.length()) {
return node.isWord;
} char c = word.charAt(index);
if (c != '.') {
if (node.next.get(c) == null) {
return false;
}
return match(node.next.get(c), word, index + 1);
} else {
for (char nextChar : node.next.keySet()) {
if (match(node.next.get(nextChar), word, index + 1)) {
return true;
}
}
return false;
}
}
}
第三十篇 玩转数据结构——字典树(Trie)的更多相关文章
- 第三十二篇 玩转数据结构——AVL树(AVL Tree)
1.. 平衡二叉树 平衡二叉树要求,对于任意一个节点,左子树和右子树的高度差不能超过1. 平衡二叉树的高度和节点数量之间的关系也是O(logn) 为二叉树标注节点高度并计算平衡因子 AVL ...
- 第三十三篇 玩转数据结构——红黑树(Read Black Tree)
1.. 图解2-3树维持绝对平衡的原理: 2.. 红黑树与2-3树是等价的 3.. 红黑树的特点 简要概括如下: 所有节点非黑即红:根节点为黑:NULL节点为黑:红节点孩子为黑:黑平衡 4.. 实现红 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- Java数据结构——字典树TRIE
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种. 典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计. 它的优点是:利用字符串的公共 ...
- 模板 - 字符串/数据结构 - 字典树/Trie
使用静态数组的nxt指针的设计,大概比使用map作为nxt指针的设计要快1倍,但空间花费大概也大1倍.在数据量小的情况下,时间和空间效率都不及map<vector,int>.map< ...
- [POJ] #1002# 487-3279 : 桶排序/字典树(Trie树)/快速排序
一. 题目 487-3279 Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 274040 Accepted: 48891 ...
- Delphi 泛型(三十篇)
Delphi 泛型(三十篇)http://www.cnblogs.com/jxgxy/category/216671.html
- 字典树(Trie)详解
详解字典树(Trie) 本篇随笔简单讲解一下信息学奥林匹克竞赛中的较为常用的数据结构--字典树.字典树也叫Trie树.前缀树.顾名思义,它是一种针对字符串进行维护的数据结构.并且,它的用途超级广泛.建 ...
随机推荐
- npm ERR! Cannot read property 'match' of undefined
在Vue项目中运行npm i命令时直接提示npm ERR! Cannot read property 'match' of undefined错误了,此时需要把package-lock.json文件删 ...
- openlayers显示区域
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- cf1282c
题意描述: 给你一颗带权无根树,共有2*n个节点,有n对人,然后每一个人被分配到一个节点上 问题1:怎么安排使得这n对人之间距离之和最小 问题2:怎么安排使得这n对人之间距离之和最大 题解:直接去想具 ...
- processing data
获取有效数据 Scikit-learn will not accept categorical features by default API里面不知使用默认的特征变量名,因此需要编码 这里我还是有疑 ...
- A Simple Problem with Integers POJ - 3468 线段树区间修改+区间查询
//add,懒标记,给以当前节点为根的子树中的每一个点加上add(不包含根节点) // #include <cstdio> #include <cstring> #includ ...
- ArcMap 导出Table数据到Excel
- webpack打包后不能调用,改用uglifyjs打包压缩
背景: 项目基于原生js,没用到任何脚手架和框架,但也需要打包压缩. 项目的js中声明了一些全局变量 供其他js调用. 这时候如果用webpack打包,基于webpack特性,会嵌套一层大函数,会将j ...
- Qt Installer Framework翻译(7-8)
C++ API C ++ API文档是为开发Qt Installer Framework的开发人员编写的. 它描述了内部API,因此没有兼容性保证. 此外,该文档尚在开发中,因此缺少部分内容,而其他部 ...
- 【巨杉数据库Sequoiadb】巨杉⼯具系列之一 | ⼤对象存储⼯具sdblobtool
近期,巨杉数据库正式推出了完整的SequoiaDB 工具包,作为辅助工具,更好地帮助大家使用和运维管理分布式数据库.为此,巨杉技术社区还将持续推出工具系列文章,帮助大家了解巨杉数据库丰富的工具矩阵. ...
- Win10安装7 —— 系统的优化
本文内容皆为作者原创,如需转载,请注明出处:https://www.cnblogs.com/xuexianqi/p/12371356.html 一:引言 在我们使用电脑的过程中,总是有一些窗口弹出来需 ...