如何向map和reduce脚本传递参数,加载文件和目录
我开始使用如下方式进行传递.

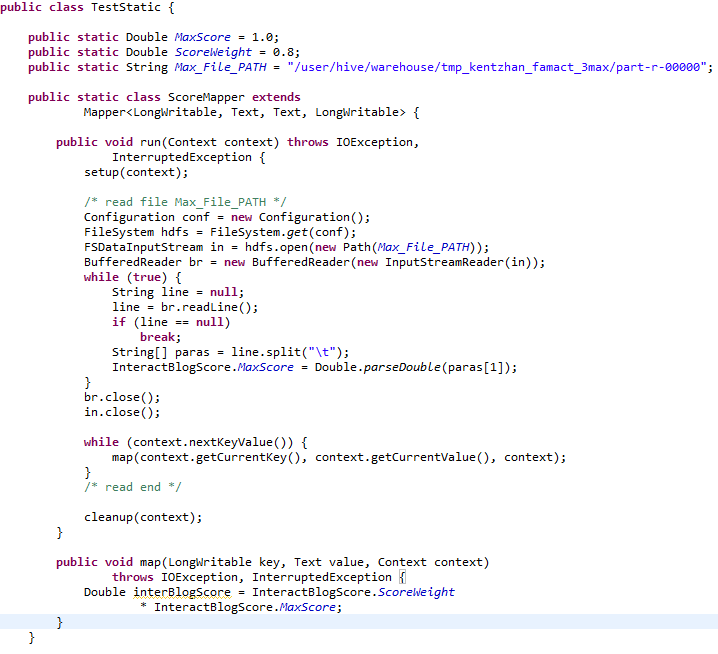
在mapper中通过上下文context来获取当前作业的配置, 并获取参数, 例如:
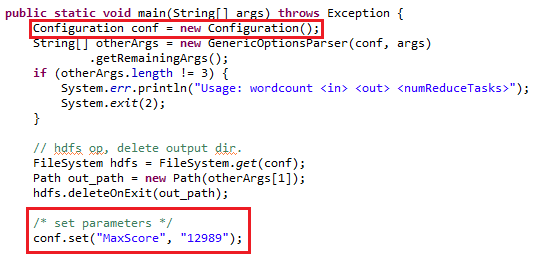
示例:
main中:
Configuration conf = new Configuration();
Text maxscore = new Text("12989");
DefaultStringifier.store(conf, maxscore ,"maxscore");
这样,Text对象maxscore就以“maxscore”作为key存储在conf对象中了,然后在map和reduce函数中调用load的方法便可以把对象读出。
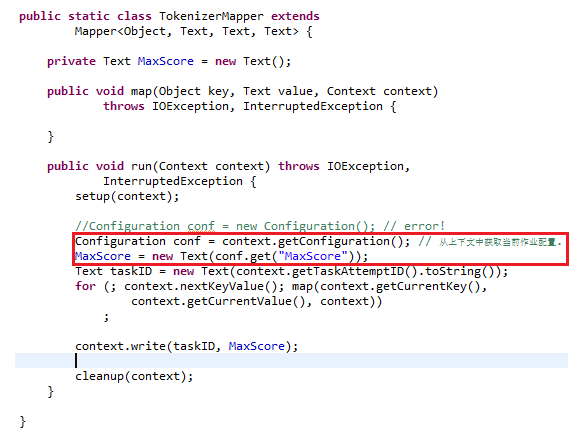
mapper获取:
Configuration conf = context.getConfiguration()
Text out = DefaultStringifier.load(conf, "maxscore", Text.class);
需要说明的是,这个需要传递的对象必须要先实现序列化的接口,Hadoop的序列化是通过Writable接口来实现的。
(2) 参考自:http://blog.sina.com.cn/s/blog_6b7cf18f0100x9jg.html
2. 编写 Streaming 程序时,如何向map、reduce函数传递参数
可以通过 streaming 的 cmdenv 选项设置环境变量,然后在 map 和 reduce 脚本中获取环境变量。
可参考 << hadoop streaming 高级编程 >>
http://dongxicheng.org/mapreduce/hadoop-streaming-advanced-programming/
(0) 作业提交脚本:
#!/usr/bin/env bash
max_read_count=${array[0]}
min_read_count=${array[1]}
max_write_count=${array[2]}
min_write_count=${array[3]}
hadoop jar $HADOOP_HOME/contrib/streaming/hadoop-0.20.2-streaming.jar \
-D mapred.reduce.tasks=1
-input $input \
-output $output \
-mapper $mapper_script \
-file $map_file \
-reducer $reducer_script \
-file $reduce_file \
-cmdenv "max_read_count=${array[0]}" \ # 设置环境变量 max_read_count .
-cmdenv "min_read_count=${array[1]}" \ # 多个变量时请多次使用 -cmdenv
-cmdenv "max_write_count=${array[2]}" \
-cmdenv "min_write_count=${array[3]}"
(1) Python mapper.py
#!/usr/bin/env python
import sys
import os
min_r_count = float(os.environ.get('min_read_count')) # get environment variables.
max_r_count = float(os.environ.get('max_read_count'))
min_w_count = float(os.environ.get('min_write_count'))
max_w_count = float(os.environ.get('max_write_count'))
(2)Shell mapper.sh
#!/usr/bin/env bash
while read line # 读入行
do
a=$line
done
echo $min_read_count $max_read_count # get environment variables.
(3)C/C++ mapper.c
#include
#include
int main(int argc, char *argv[], char *env[])
{
double min_r_count;
int i = 0;
for (i = 0; env[i] != NULL; i++) // env[i] 存储了环境变量, 每项的值为此种形式: PATH=******, 所以需要截取变量值
{
if( strstr(env[i], "PATH=") ) {
char *p =NULL;
p = strstr(env[i], "=");
if( (p-env[i]) == 4 )
printf("%s\n", ++p); // 获取 PATH 环境变量
}
if( strstr(env[i], "min_write_count=") ) {
char *p =NULL;
p = strstr(env[i], "=");
if( (p-env[i]) == strlen("min_write_count") )
printf("%s\n", ++p); // 获取 min_write_count 环境变量
}
}
char eachLine[200]={0};
while(fgets(eachLine, 199, stdin)) // read line from stdin
{
printf("%s", eachLine);
}
}
注意:
(1) streaming 加载本地单个文件
streaming 支持 -file 选项, 可以把 -file 后面的本地文件(注意是本地文件)打包成作业提交的一部分, 即打包到作业的jar文件当中, 这样在mapreduce脚本中就可以像访问本地文件一样访问打包的文件了.
实例:
作业提交文件 run.sh
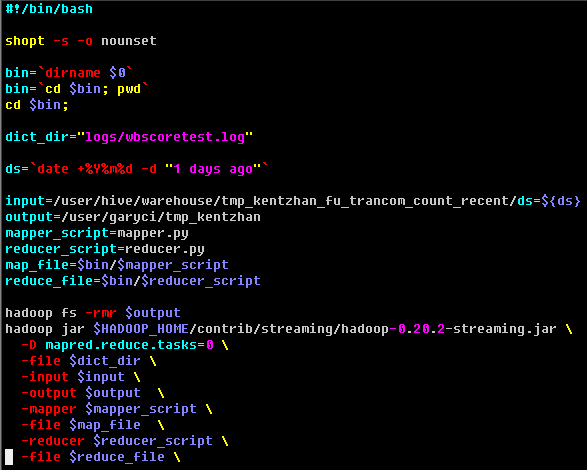
mapper.py
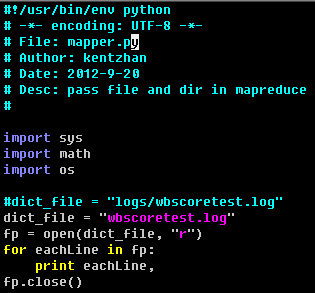
注意:在提交作业时使用的是 -file logs/wbscoretest.log 指定需要加载的文件. 在 map 脚本中只需要直接读取文件 wbscoretest.log 即可, 不需要写 logs/wbscoretest.log, 因为只加载了文件 wbscoretest.log, 而不会加载 logs 目录和
wbscoretest.log 文件.
(2) streaming 加载本地多个文件
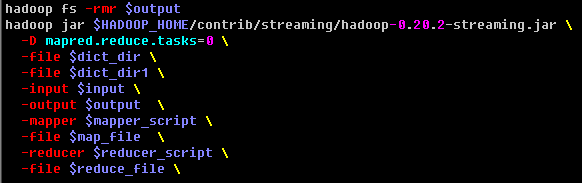
(3) streaming 加载本地目录 ( 若加载多个目录,用逗号隔开,-files dir1, dir2, dir3 )
使用streaming的 -file 选项不能加载本地目录, 我实验是如此.
我们可以使用 hadoop 的通用选项 -files 来加载本地目录, 加载成功后在mapreduce脚本中可以像访问本地目录一样访问加载的目录.
实际应用中,我们在编写 分词MapReduce作业时需要加载分词词典,就使用该方法.
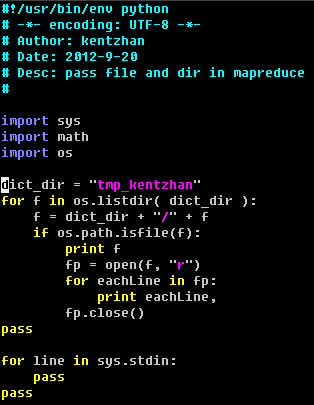
作业提交脚本:
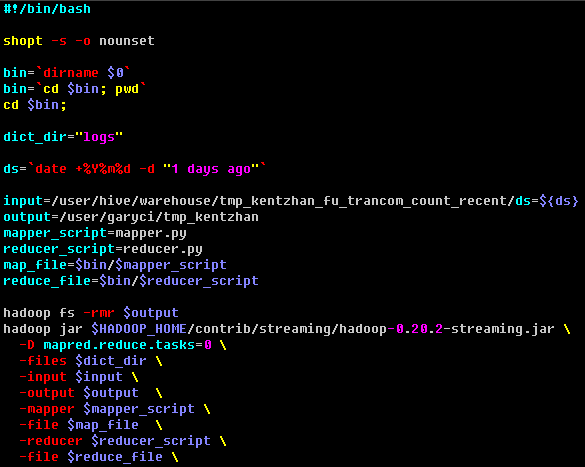
map 脚本: 读取目录下的文件.
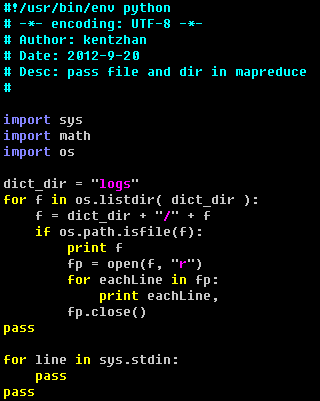
加载多个目录:
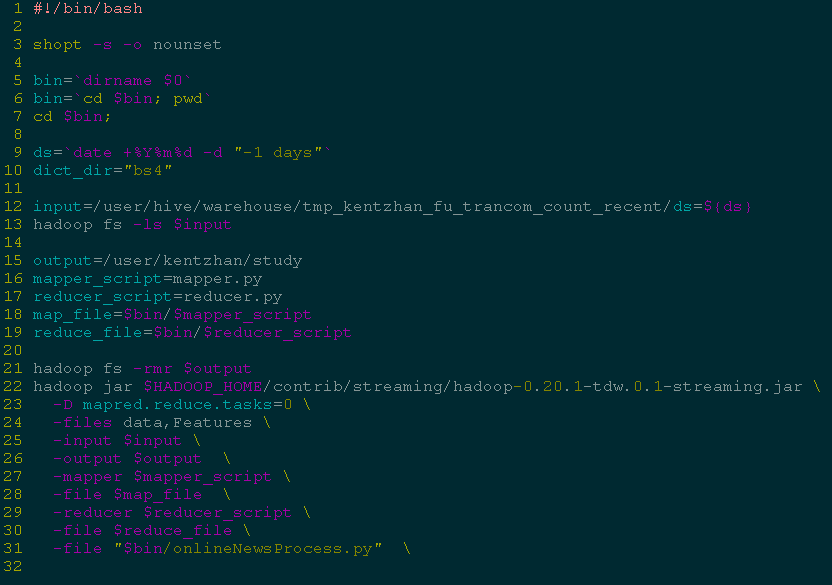
注意:多个目录之间用逗号隔开,且不能有空格,否则会出错,这个限制太蛋疼了。
例如:
(4) streaming编程时在mapreduce脚本中读 hdfs 文件
使用 -files 选项, 后面跟需要读的 hdfs 文件路径. 这样在 mapreduce 脚本中就可以直接通过文件名来访问该文件.
作业提交脚本:

map脚本:
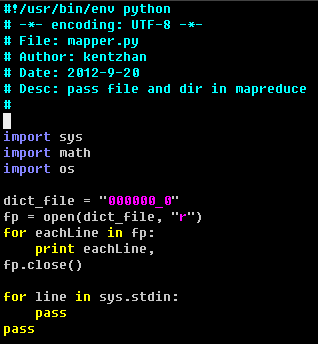
如果需要加载大文件, 我们可以将文件先上传到 hdfs 中, 然后在 mapreduce 脚本中读取 hdfs 文件.
(5) streaming编程时在mapreduce脚本中读 hdfs 目录
使用 -files 选项, 后面跟需要读的 hdfs 目录. 这样在 mapreduce 脚本中就可以像访问本地目录一样访问该目录.
作业提交脚本:
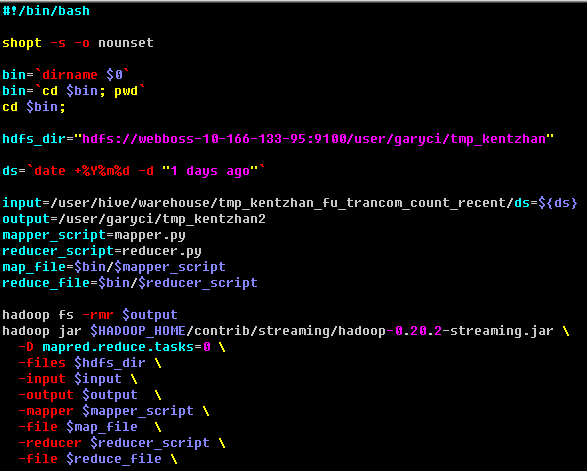
map脚本: 直接读取 tmp_kentzhan 目录.
如何向map和reduce脚本传递参数,加载文件和目录的更多相关文章
- 【hadoop】如何向map和reduce脚本传递参数,加载文件和目录
本文主要讲解三个问题: 1 使用Java编写MapReduce程序时,如何向map.reduce函数传递参数. 2 使用Streaming编写MapReduce程序(C/C++ ...
- (转)如何向map和reduce脚本传递参数
[MapReduce] 如何向map和reduce脚本传递参数,加载文件和目录 分类: hadoop2014-04-28 21:30 1553人阅读 评论(0) 收藏 举报 hadoop 本文主要讲解 ...
- python 脚本传递参数
python查找指定字符 #!/usr/bin/env python import sys import re f = open("log.txt", "rb" ...
- PowerShell脚本传递参数
在编写PowerShell脚本的时候,可以通过给变量赋值的方法输出想要的结果,但这样的话,需要改动脚本内容.其实也可以在脚本中定义参数,然后再在执行脚本的时候对参数赋值,而无需改动脚本内容. 在Pow ...
- linux shell编程指南第二十章------向脚本传递参数
前面已经讲到如何使用特定变量$ 1 . . $ 9向脚本传递参数.$ #用于统计传递参数的个数.可 以创建一个u s a g e语句,需要时可通知用户怎样以适当的调用参数调用脚本或函数. 简单地说,下 ...
- shell调用python脚本,并且向python脚本传递参数
1.shell调用python脚本,并且向python脚本传递参数: shell中: python test.py $para1 $para2 python中: import sys def main ...
- 分发系统介绍、expect脚本远程登录、expect脚本远程执行命令、expect脚本传递参数
7月19日任务 20.27 分发系统介绍20.28 expect脚本远程登录20.29 expect脚本远程执行命令20.30 expect脚本传递参数 20.27 分发系统介绍 公司业务逐渐扩大时, ...
- Linux centosVMware运行告警系统、分发系统-expect讲解、自动远程登录后,执行命令并退出、expect脚本传递参数、expect脚本同步文件、指定host和要同步的文件、shell项目-分发系统-构建文件分发系统、分发系统-命令批量执行
一运行告警系统 创建一个任务计划crontab -e 每一分钟都执行一次 调试时把主脚本里边log先注释掉 再次执行 没有发现502文件说明执行成功了,每日有错误,本机IP 负载不高 二.分发系统-e ...
- 学习加密(四)spring boot 使用RSA+AES混合加密,前后端传递参数加解密
学习加密(四)spring boot 使用RSA+AES混合加密,前后端传递参数加解密 技术标签: RSA AES RSA AES 混合加密 整合 前言: 为了提高安全性采用了RS ...
随机推荐
- Struts2 入门实例
一.最简登录 Demo:login.jsp——web.xml——struts.xml——LoginAction.java——struts.xml——index.jsp 1.下载 Struts2 框架: ...
- xshell5使用ssh连接阿里云服务器
这里有两种方式,一种是在阿里云的控制台里面进行,另一种是在Xshell里面生成密钥. 阿里云控制台密钥对 点击右上方的创建密钥对 在阿里云里面生成较为简单,点击该页面右上方的“创建密钥对”,在另一个页 ...
- Memory Manager surface area changes in SQL Server 2012
here were various changes to memory related DMVs, DBCC memory status, and Perfmon counters in SQL Se ...
- Runtime.getRuntime.exec();
杀死Chrome浏览器进程 private static void closeAllChrome() throws IOException{ Runtime.getRuntime().exec(&qu ...
- 双击jar包运行方法
方案一 在jar包同级,写个bat文件,如下 java -jar Xxx.jar pause 方案二 右击jar文件 ->打开方式->选择安装的jre/bin/javaw.exe. 双击依 ...
- Linux命令nohup+screen 转
如果想在关闭ssh连接后刚才启动的程序继续运行怎么办,可以使用nohup.但是如果要求第二天来的时候,一开ssh,还能查看到昨天运行的程序的状态,然后继续工作,这时nohup是不行了,需要使用scre ...
- js排序算法03——选择排序
选排序的思路是首先从要排序的数组中选择最小的和目前的第一位交换位置,然后从剩下的数中选择最小的和第二个位置的数交换位置,再从剩下的数中选择最小的和第三个位置的数交换位置,以此类推,实现代码如下: fu ...
- webapi在IIS发布后报Http 403.14 error
服务器是Windows Server 2008 R2 Enterprise IIS6.1 解决方法,修改web.config文件 1.在<system.webServer>配置 ...
- HDU 5875 Function (线段树+gcd / 单调栈)
题意:给你一串数a再给你一些区间(lef,rig),求出a[lef]%a[lef+1]...%a[rig] 题解:我们可以发现数字a对数字b取模时:如果a<b,则等于原数,否则a会变小至少一半. ...
- SpringBoot Mybatis PageHelper插件报错
SpringBoot2.0.0 MyBatis1.3.2 PageHelper1.1.2插件,但是在启动运行时,抛错:org.springframework.beans.factory.BeanCre ...