lua的性能优化
Roberto Ierusalimschy写过经典的Lua 性能提示的文章,链接地址>>
我通过实际的代码来验证,发现一个问题。当我使用 LuaStudio 运行时,发现结果反而与提示相反,甚是奇怪,而使用luac进行运行,与作者给予的提示相符,在某些地方性能可能有优化,比如读取35kb的文件时,时间还是比较快的(可能5.1版本做过优化了)。
日常的Lua编码中,需要注意以下几点:
1)多使用local
print(_VERSION) local startTime, endTime startTime = os.clock() for i = 1, 100 * 10000 do
local x = math.sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local sin = math.sin
for i = 1, 100 * 10000 do
local x = sin(i)
end endTime = os.clock() print("[local] used time " .. (endTime - startTime) * 1000 .. " ms")

上面二段代码,唯一的区别就是使用 local sin 将 math.sin缓存起来。性能提升约 (107 - 74) / 107 ~= 30.8%,基本符合作者所说的30%的效率提升。
startTime = os.clock()
function foo(x)
for i = 1, 100 * 10000 do
x = x + math.sin(i)
end
return x
end foo(10) endTime = os.clock() print("[foo] used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function foo2(x)
local sin = math.sin
for i = 1, 100 * 10000 do
x = x + sin(i)
end
return x
end foo2(10) endTime = os.clock() print("[foo2] used time " .. (endTime - startTime) * 1000 .. " ms")
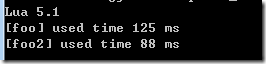
提升的时间是 (125 – 88) /125 = 29.6%,也约为30%(需要多次测试取平均值)
使用闭包,避免动态编译。
startTime = os.clock()
local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = loadstring(string.format("return %d", i))
end print(a[10]()) endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
function fk(k)
return function() return k end
end local lim = 10 * 10000
local a = {}
for i = 1, lim do
a[i] = fk(i)
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
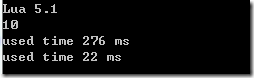
节省了约92%的时间,差异距大。
2) 字符串拼接,尽可能使用 table 替代
startTime = os.clock() local buff = ""
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
buff = buff .. line .. "\n"
end endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock() local buff = ""
local tbl = {}
for line in io.lines("C:/Users/zhangyi/Desktop/xxx.txt") do
table.insert(tbl, line)
end buff = table.concat(table, "\n") endTime = os.clock() print(collectgarbage("count") * 1024) print("used time " .. (endTime - startTime) * 1000 .. " ms")
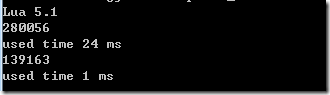
差异非常大,无论是内存还是时间,主要原因是:Lua中字符串的拼接都是新创建一个新的字符串,有一个新创建一块内存、copy字符串的动作,时间、空间上消耗都比较大。
3) table使用的优化
startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms") startTime = os.clock()
for i = 1, 100 * 10000 do
local a = {true, true, true}
a[1] = 1
a[2] = 2
a[3] = 3
end
endTime = os.clock() print("used time " .. (endTime - startTime) * 1000 .. " ms")
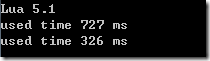
时间相差一倍,也就是说如果不给{}给定初时化大小,当赋值的时候,它会申请空间来存放相应的值。
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {x = i, y = 1})
end
print(collectgarbage("count") / 1024)
107.57151889801MB
local polyline= {}
for i = 0, 100 * 10000 do
table.insert(polyline, {i, 1})
end
print(collectgarbage("count") / 1024)
77.053853034973MB
local polyline= {
x = {},
y = {}
}
for i = 0, 100 * 10000 do
table.insert(polyline.x, i)
table.insert(polyline.y, i)
end
print(collectgarbage("count") / 1024)
32.019150733948MB
空间占用差距也非常大,从上面似乎可以得到这样的结论:尽可能减少table的长度,尽可能使用array 而不是 hash。
综上所述,尽可能多使用local,减少查询的性能损耗。json数据表如果需要转化为table时,改变数据的存储结构可能减少很大的内存使用。
lua的性能优化的更多相关文章
- Lua脚本性能优化指南
https://github.com/flily/lua-performance/blob/master/Guide.zh.md https://springrts.com/wiki/Lua_Perf ...
- Lua性能优化
原文:Lua Performance Tips 偶然找到<Lua Performance Tips>这篇关于Lua的优化文章,个人认为相较于多数泛泛而谈要好不少.尽管Lua已经到5.2版本 ...
- iOS app性能优化的那些事
iPhone上面的应用一直都是以流畅的操作体验而著称,但是由于之前开发人员把注意力更多的放在开发功能上面,比较少去考虑性能的问题,可能这其中涉及到objective-c,c++跟lua,优化起来相对 ...
- app 性能优化的那些事
来源:树下的老男孩 链接:http://www.jianshu.com/p/5cf9ac335aec iPhone上面的应用一直都是以流畅的操作体验而著称,但是由于之前开发人员把注意力更多的放在开发功 ...
- [转]Lua和Lua JIT及优化指南
一.什么是lua&luaJit lua(www.lua.org)其实就是为了嵌入其它应用程序而开发的一个脚本语言, luajit(www.luajit.org)是lua的一个Just-In-T ...
- luajit官方性能优化指南和注解
luajit是目前最快的脚本语言之一,不过深入使用就很快会发现,要把这个语言用到像宣称那样高性能,并不是那么容易.实际使用的时候往往会发现,刚开始写的一些小test case性能非常好,经常毫秒级就算 ...
- 用好lua+unity,让性能飞起来——关于《Unity项目常见Lua解决方案性能比较》的一些补充
<Unity项目常见Lua解决方案性能比较>,这篇文章对比了现在主流几个lua+unity的方案 http://blog.uwa4d.com/archives/lua_perf.html ...
- Nginx 服务器性能Bug和性能优化方案(真实经历)
一.遇到的问题 1.问题:本应该是3个ffmpeg ,但是怎么会有5个ffmpeg出现? 2.Lua脚本问题,一直写入日志,导致有大量的日志,这里的错误日志是直接写进nginx的error.log 日 ...
- "个性化空间"性能优化方案设计初步
一.问题的提出 在九月中开始,我们要打造个性化空间,领导要求的是只进行原型的设计,逻辑的设计,不进行技术开发.其实是严重不正确的,因为个性化空间其特点与现有的技术模型完全不同,现有的技术方案未必能适应 ...
随机推荐
- ssh登录报错-bash fork retry Resource temporarily unavailable
- Codeforces 425E Sereja and Sets dp
Sereja and Sets 我们先考虑对于一堆线段我们怎么求最大的不相交的线段数量. 我们先按 r 排序, 然后能选就选. 所以我们能想到我们用$dp[ i ][ j ]$表示已经选了 i 个线段 ...
- ghithub中PHPOffice/PHPWord的学习
1.概念:PHPWord是用纯PHP提供了一组类写入和从不同的文档格式的文件阅读库.PHPWord的当前版本支持微软的Office Open XML(OOXML或处理OpenXML),用于Office ...
- C# 类的序列化和反序列化
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程.在序列化期间,对象将其当前状态写入到临时或持久性存储区.以后,可以通过从存储区中读取或反序列化对象的状态,重新创 ...
- L1-006 连续因子 (20 分) 模拟
一个正整数 N 的因子中可能存在若干连续的数字.例如 630 可以分解为 3×5×6×7,其中 5.6.7 就是 3 个连续的数字.给定任一正整数 N,要求编写程序求出最长连续因子的个数,并输出最小的 ...
- 数学模型:3.非监督学习--聚类分析 和K-means聚类
1. 聚类分析 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术 ---->> 将观测对象的群体按照相似性和相异性进行不同群 ...
- C++实现--最大公因数和最小公倍数
一丶 最大公因数求法: 辗转相除法(也称欧几里得算法)原理: 二丶最小公倍数求法:两个整数的最小公倍数等于两整数之积除以最大公约数 C++ 代码实现 #include <iostream ...
- JS事件基础
事件对象Event 对象代表事件的状态,比如事件在其中发生的元素.键盘按键的状态.鼠标的位置.鼠标按钮的状态.什么时候会产生Event 对象呢? 例如: 当用户单击某个元素的时候,我们给这个元素注册的 ...
- 3dsmax不同版本 pyside qt UI 设置max窗口为父窗口的方法
3dsmax不同版本 pyside qt widget 设置 max 窗口为父窗口的方法 前言: 3dsmax 在 2014 extension 之后开始集成 Python 和 PySide,但是在版 ...
- Codeforces 1130D1 Toy Train (Simplified) (思维)【贪心】
<题目链接> 题目大意: 有一个的环形火车站,其中有$[1,n] n$个站台,站台上能够放糖果,火车只能朝一个方向移动,如果火车在站台$i$,那么下一秒就会在$i+1$站(如果$i=n$, ...