Kafka实战-数据持久化
1.概述
经过前面Kafka实战系列的学习,我们通过学习《Kafka实战-入门》了解Kafka的应用场景和基本原理,《Kafka实战-Kafka Cluster》一文给大家分享了Kafka集群的搭建部署,让大家掌握了集群的搭建步骤,《Kafka实战-实时日志统计流程》一文给大家讲解一个项目(或者说是系统)的整体流程,《Kafka实战-Flume到Kafka》一文给大家介绍了Kafka的数据生产过程,《Kafka实战-Kafka到Storm》一文给大家介绍了Kafka的数据消费,通过Storm来实时计算处理。今天进入Kafka实战的最后一个环节,那就是Kafka实战的结果的数据持久化。下面是今天要分享的内容目录:
- 结果持久化
- 实现过程
- 结果预览
下面开始今天的分享内容。
2.结果持久化
一般,我们在进行实时计算,将结果统计处理后,需要将结果进行输出,供前端工程师去展示我们统计的结果(所说的报表)。结果的存储,这里我们选择的是Redis+MySQL进行存储,下面用一张图来展示这个持久化的流程,如下图所示:
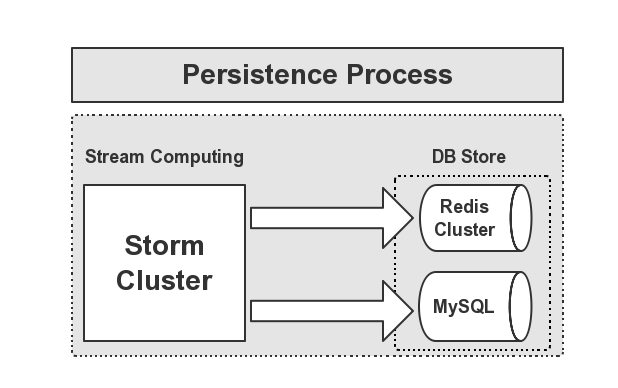
从途中可以看出,实时计算的部分由Storm集群去完成,然后将计算的结果输出到Redis和MySQL库中进行持久化,给前端展示提供数据源。接下来,我给大家介绍如何实现这部分流程。
3.实现过程
首先,我们去实现Storm的计算结果输出到Redis库中,代码如下所示:
package cn.hadoop.hdfs.storm; import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry; import redis.clients.jedis.Jedis;
import cn.hadoop.hdfs.util.JedisFactory;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple; /**
* @Date Jun 10, 2015
*
* @Author dengjie
*
* @Note Calc WordsCount eg.
*/
public class WordsCounterBlots implements IRichBolt { /**
*
*/
private static final long serialVersionUID = -619395076356762569L; OutputCollector collector;
Map<String, Integer> counter; @SuppressWarnings("rawtypes")
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
this.counter = new HashMap<String, Integer>();
} public void execute(Tuple input) {
String word = input.getString(0);
Integer integer = this.counter.get(word);
if (integer != null) {
integer += 1;
this.counter.put(word, integer);
} else {
this.counter.put(word, 1);
}
for (Entry<String, Integer> entry : this.counter.entrySet()) {
// write result to redis
Jedis jedis = JedisFactory.getJedisInstance("real-time");
jedis.set(entry.getKey(), entry.getValue().toString()); // write result to mysql
// ...
}
this.collector.ack(input);
} public void cleanup() {
// TODO Auto-generated method stub } public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub } public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
} }
注:这里关于输出到MySQL就不赘述了,大家可以按需处理即可。
4.结果预览
在实现持久化到Redis的代码实现后,接下来,我们通过提交Storm作业,来观察是否将计算后的结果持久化到了Redis集群中。结果如下图所示:

通过Redis的Client来浏览存储的Key值,可以观察统计的结果持久化到来Redis中。
5.总结
我们在提交作业到Storm集群的时候需要观察作业运行状况,有可能会出现异常,我们可以通过Storm UI界面来观察,会有提示异常信息的详细描述。若是出错,大家可以通过Storm UI的错误信息和Log日志打印的错误信息来定位出原因,从而找到对应的解决办法。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Kafka实战-数据持久化的更多相关文章
- 漫游Kafka设计篇之数据持久化
Kafka大量依赖文件系统去存储和缓存消息.对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能.实际上硬盘的快慢完全取决于使用它的方式.设计良好的硬盘架构可以和内 ...
- Docker数据持久化及实战(Nginx+Spring Boot项目+MySQL)
Docker数据持久化: Volume: (1)创建mysql数据库的container docker run -d --name mysql01 -e MYSQL_ROOT_PASSWORD= my ...
- .Net Redis实战——事务和数据持久化
Redis事务 Redis事务可以让一个客户端在不被其他客户端打断的情况下执行多个命令,和关系数据库那种可以在执行的过程中进行回滚(rollback)的事务不同,在Redis里面,被MULTI命令和E ...
- iOS开发——项目实战总结&数据持久化分析
数据持久化分析 plist文件(属性列表) preference(偏好设置) NSKeyedArchiver(归档) SQLite 3 CoreData 当存储大块数据时你会怎么做? 你有很多选择,比 ...
- DataPipeline |《Apache Kafka实战》作者胡夕:Apache Kafka监控与调优
胡夕 <Apache Kafka实战>作者,北航计算机硕士毕业,现任某互金公司计算平台总监,曾就职于IBM.搜狗.微博等公司.国内活跃的Kafka代码贡献者. 前言 虽然目前Apache ...
- Kafka实战分析(一)- 设计、部署规划及其调优
1. Kafka概要设计 kafka在设计之初就需要考虑以下4个方面的问题: 吞吐量/延时 消息持久化 负载均衡和故障转移 伸缩性 1.1 吞吐量/延时 对于任何一个消息引擎而言,吞吐量都是至关重要的 ...
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 《Apache Kafka 实战》读书笔记-认识Apache Kafka
<Apache Kafka 实战>读书笔记-认识Apache Kafka 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.kafka概要设计 kafka在设计初衷就是 ...
随机推荐
- PHP并发之CURL
<?php $start_time = microtime(true); $url = array(); for ($i=0;$i<1000;$i++){ $url[] = "h ...
- Django实现支付宝支付
一 去支付宝申请 - 正式:营业执照 - 测试: 沙箱测试环境 APPID:2016092000554391 买家: esnrce2727@sandbox.com 登录和支付密码: ...
- Thinkphp5 表单提交额外参数和页面跳转参数传递url
1. 表单提交 <input type="hidden" name="project_name" value="$project_name&qu ...
- Luogu1613 跑路-倍增+Floyd
Solution 挺有趣的一道题, 仔细想想才想出来 先用$mp[i][j][dis]$ 是否存在一条 $i$ 到 $j$ 的长度为 $2^{dis}$ 的路径. 转移 : ; dis < ba ...
- 17. pt-online-schema-change
在平时MySQL的运维过程中,经常会遇到表结构的变更.在表比较小的时候,直接进行变更,时间较短,但是当表非常大的时候,这么做会导致应用卡死,服务不可用.目前InnoDB引擎是通过以下步骤来进行DDL的 ...
- python页面解析_beautifulsoup试玩
最近玩爬虫,先把python解析器 beautifulsoup 练练 这个 tainiu.html 是从百度网盘里拷贝一段html from bs4 importBeautifulSoup wit ...
- 可以用到的XSS跨站语句
我们常用的测试XSS跨站的语句一般是alert比如: <script>alert(“sex”)</script> <script>alert(/sex/)</ ...
- Chapter3_操作符_逻辑操作符
逻辑操作符与(&&)或(||)非(^)能够对布尔类型的数据类型进行操作,并且生成布尔值,和关系操作符的产生的数据类型是一样的.需要注意的不多,有以下几点: (1)在需要使用string ...
- springboot读取properties和yml配置文件
一.新建maven工程:springboot-configfile-demo,完整工程如下: pom.xml <?xml version="1.0" encoding=&qu ...
- Solidity合约记录——(一)如何寻找以太坊真实Solidity源码
在自主学习Solidity智能合约的过程中,第一份入手资料无疑是官方文档.感谢前辈们还能提供出文档的中文翻译,作为我入门的第一手资料:文末附上有用的学习链接{持续更新中} 阅读完基础文档同时上手合约后 ...