Nvidia 的新显卡架构 Maxwell 性能相比开普勒提升了多少?
链接:https://www.zhihu.com/question/22630075/answer/29041618
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
现在Nvidia的节奏基本上是一个结构用两年。类似于intel的钟摆计划。
我们先先谈谈开普勒架构之前的费米架构好了。
费米的本质是什么,英伟达只要用他来搞通用计算的还有DX11(这个涉及当年的环境问题)。
费米架构提出了GPC和SM的结构概念。每一个GPC则有4个SM,sm里面有32个CUDA,每个CUDA Core是一个统一的处理器核心,执行顶点,像素,几何和kernel函数,然后有16个储存单元和8个特殊单元。
上面一段话的意思是,GPC是一个很完整的GPU,而且细分的十分完整。
所以你会看到高中低端是这么分配的低端一个,中端两个,高端四个。
大家会不会想到CPU呢。。单核,双核,四核。。大概就是思路。。
然后又引入了一二级缓存这种东西。。大家详细了解自己去搜相关东西吧。。
而AMD当时的思路跟Nvidia不一样的是,坚持用simd。至于为什么?可能是AMD和ATI整合,也可能是ATI做过游戏机的芯片制造,这个不好推断)
大的核心里面有Shader单元,每个Shader内部有5个ALU单元。
五个ALU处理完了之后一起上传,而CUDA Core是直接上传了,这就是mimd。
看到ZOL论坛有一个很好的比方。。我就粗略说说意思(传送门【NV 开普勒 架构解析篇】)
AMD就是一辆战车,然后一个马拉着战车(发射端和控制逻辑端),上面有五个家伙。弓箭手啊,战士,扔斧子的。
费米就是骑兵。。
战车虽然相比较骑兵发挥不出一个人的优势。但是养马在古代很贵的好吧,就算现在也很贵好吧。。
战车上有五个汉子,相当于马加五个人,而骑兵是一个马加一个人。
性价比肯定是战车好。
但是数量到了一定程度。史实是大兵团对战时,骑兵可以用经典的魔兽战术hit and run对付战车,先遭遇,一轮齐射,射完马上后撤,迂回一圈再过来齐射,射完再后撤········(中世纪时曾经很虎的东欧战车军就是这样被蒙古骑兵团灭的,西征波兰战役的虐杀)。中世纪开始大家都发现了,一旦战争规模玩大了,只能用骑兵,再贵也得用。
Nvidia依旧保持卡皇身份,但是中低端的AMD高功耗比和性价比虐杀。
显卡跟骑兵不一样的是。。你弄了那么多马(发射器和控制逻辑),那玩意是要发热的。。而且也是要占晶体管的。
所以你就看到核弹这个词的产生了。。。热得要死,晶体管多的要命。
详细请看传送门
写的挺好的(对了 要不要找别人授权啥的。。我没这意识啊。。)
总结一下就是AMD追求数量,而Nvidia追求效率。。
后来AMD发觉在这么玩下去不行,毕竟规模越来越大了。。也开始制造骑兵了,再贵也得用。。。就是tahtil架构。
然后我们回到开普勒架构。。
开普勒开始追求所谓的能耗,如何追求能耗的呢?降低控制逻辑单元和指令发射器的比例,,用较少的逻辑单元去控制更多的CUDA核心,增加吞吐量啊等等方面。
<img src="https://pic2.zhimg.com/c2ded9290c1ee7a6d32e21f1935a76b5_b.jpg" data-rawheight="492" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic2.zhimg.com/c2ded9290c1ee7a6d32e21f1935a76b5_r.jpg">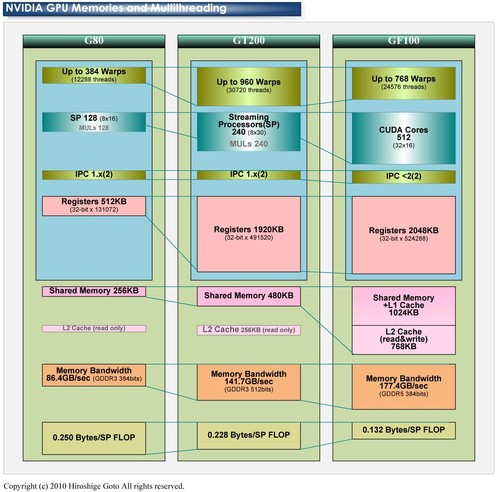
但是关键还是在调度的机制。
减少了调度的模块,才能拥有非常多的cuda(也就是工作单位)
<img src="https://pic3.zhimg.com/db1a634716f43218ad92f51df98f26e6_b.jpg" data-rawheight="282" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic3.zhimg.com/db1a634716f43218ad92f51df98f26e6_r.jpg">通过软件把GPU用来分配工作的任务,来交给了CPU。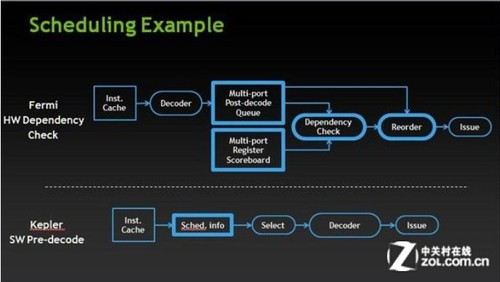 通过软件把GPU用来分配工作的任务,来交给了CPU。
通过软件把GPU用来分配工作的任务,来交给了CPU。
<img src="https://pic4.zhimg.com/b7f42f772e6ed7cd9481615e18834a13_b.jpg" data-rawheight="866" data-rawwidth="500" class="origin_image zh-lightbox-thumb" width="500" data-original="https://pic4.zhimg.com/b7f42f772e6ed7cd9481615e18834a13_r.jpg">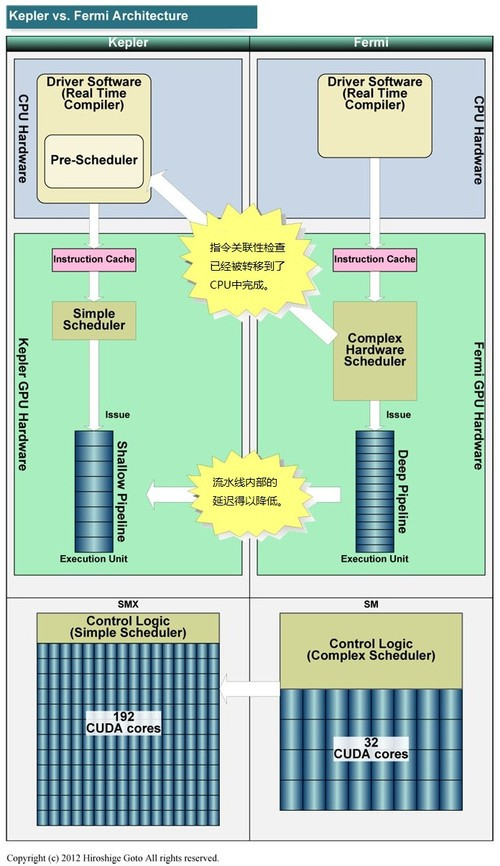
还有关键的几点是制程的改进,用了台积电的28mm,ddr5的显卡内存,动态提速(类似睿频的概念)等。
nvidia 在全面优化各方面,梳理各方面的思绪。方方面面的优化,只为了追求效率和功耗比。
最后说说 Maxwell 架构
<img src="https://pic2.zhimg.com/ec523c8963e5e7a74552bab83dcb6aa1_b.jpg" data-rawheight="324" data-rawwidth="190" class="content_image" width="190">
相比较开普勒架构的
<img src="https://pic2.zhimg.com/6484a9a33ece2754d95c00a837e16dad_b.jpg" data-rawwidth="741" data-rawheight="800" class="origin_image zh-lightbox-thumb" width="741" data-original="https://pic2.zhimg.com/6484a9a33ece2754d95c00a837e16dad_r.jpg">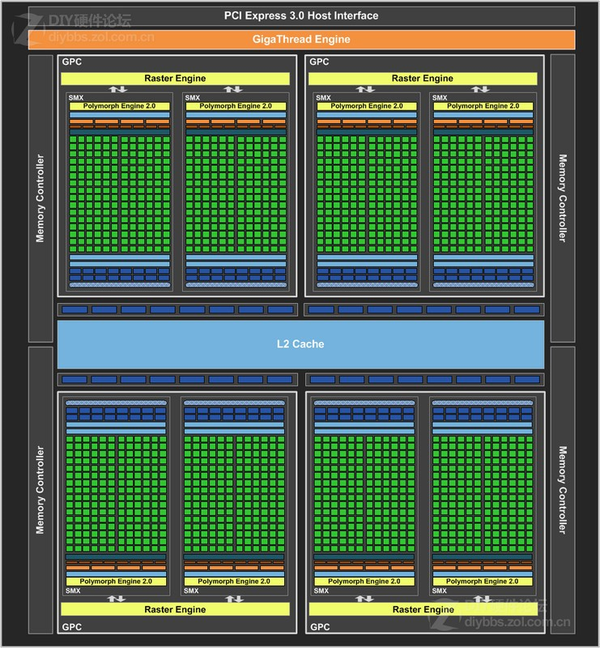
。。。能够更好的检测到每一个cuda的状态(因为每一个sm单元控制的cuda单元减少),并且通过时钟调节来控制每一个效率。
,增加了二级缓存。。集成了NVENC,能在视频解码的仅仅靠NVENC模块,让GPU休眠。。当然还有很多
第一次写这个,然后好多资料是日语,英语的。我这方面好渣,就先默默搜集,以后在啃。,借鉴了一些国内有质量新闻的东西。。比如说中关村的顾杰。。写的还是货比较多的。、。
其实我感觉Nvidia每一代继承了上一代并且在各方面进行改进。。
~
~~~~~~~~~~~~~~~~~~~~实际情况~~~~~~~~~~~
gtx750TI是maxwell架构 gtx660 650ti是开普勒架构 hd7850是Tahiti架构
<img src="https://pic1.zhimg.com/1c0d593a46b106296e146a011956ca94_b.jpg" data-rawwidth="482" data-rawheight="247" class="origin_image zh-lightbox-thumb" width="482" data-original="https://pic1.zhimg.com/1c0d593a46b106296e146a011956ca94_r.jpg">跑分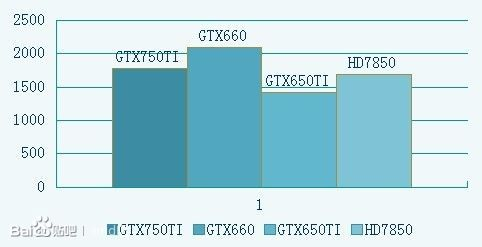 跑分
跑分
<img src="https://pic2.zhimg.com/47009df7ea0521bb68a3a2f4ae082211_b.jpg" data-rawwidth="465" data-rawheight="241" class="origin_image zh-lightbox-thumb" width="465" data-original="https://pic2.zhimg.com/47009df7ea0521bb68a3a2f4ae082211_r.jpg">功耗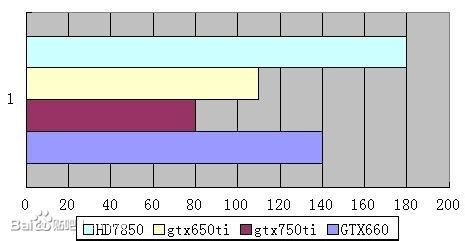 功耗
功耗
Nvidia 的新显卡架构 Maxwell 性能相比开普勒提升了多少?的更多相关文章
- NVIDIA各个领域芯片现阶段的性能和适应范围
NVIDIA作为老牌显卡厂商,在AI领域深耕多年.功夫不负有心人,一朝AI火,NVIDIA大爆发,NVIDIA每年送给科研院所和高校的大量显卡,大力推广Physix和CUDA,终于钓了产业的大鱼. 由 ...
- ubuntu下终于安装好了nvidia的gt540显卡驱动
ubuntu下终于安装好了nvidia的gt540显卡驱动.估计好多童鞋怕麻烦都放弃安装了哈. 先看看效果. ~$ lspci |grep -i vga :) :00.0 VGA compatible ...
- 【转帖】威盛x86 AI处理器架构、性能公布:媲美Intel 32核心
威盛x86 AI处理器架构.性能公布:媲美Intel 32核心 https://www.cnbeta.com/articles/tech/920559.htm 除了Intel.AMD,宝岛台湾的威盛也 ...
- paip.cache 缓存架构以及性能提升总结
paip.cache 缓存架构以及性能提升总结 1 缓存架构以及性能(贯穿读出式(LookThrough) 旁路读出式(LookAside) 写穿式(WriteThrough) 回写式 ...
- mysql性能调优与架构设计(一)商业需求与系统架构对性能的影响
这里我们就拿一个看上去很简单的功能来分析一下. 需求:一个论坛帖子总量的统计附加要求:实时更新 在很多人看来,这个功能非常容易实现,不就是执行一条SELECT COUNT(*)的Query 就可以得到 ...
- 新项目架构从零开始(三)------基于简单ESB的服务架构
这几个月一直在修改架构,所以迟迟没有更新博客. 新的架构是一个基于简单esb的服务架构,主要构成是esb服务注册,wcf服务,MVC项目构成. 首先,我门来看一看解决方案, 1.Common 在Com ...
- Ubuntu 14.04(64位)+GTX970+CUDA8.0+Tensorflow配置 (双显卡NVIDIA+Intel集成显卡) ------本内容是长时间的积累,有时间再详细整理
(后面内容是本人初次玩GPU时,遇到很多坑的问题总结及尝试解决办法.由于买独立的GPU安装会涉及到设备的兼容问题,这里建议还是购买GPU一体机(比如https://item.jd.com/396477 ...
- 微软YY公开课[《微软中国云计算Azure平台体验与新企业架构设计》 周六晚9点
YY频道是 52545291//@_勤_: YY账号真的是一次一账号啊! 全然记不得之前注冊的//@老徐FrankXuLei: 最火爆的微软免费公开课.第一次顶峰126人.第二次96人.第三次我们又来 ...
- FlowPortal-BPM——创建新组织架构、表单、流程
一.创建新组织架构 (1)管理流程→组织管理→组织架构添加需要的组织架构→新建新成员或角色 (2)设置成员信息 二.创建新数据源(如果在已有的数据库中操作,只需要添加需要的表) (1)添加新数据库并添 ...
随机推荐
- [洛谷P1361]小M的作物
题目大意:将作物种在A,B两地,对于每种作物,种A,B分别有不同的收益,对于一些特殊的作物集合,共同种到A,B集合分别有一些额外收益.求最大收益. 题解:最小割,S向i连容量为$a_i$的边,i向T连 ...
- [Leetcode] distinct subsequences 不同子序列
Given a string S and a string T, count the number of distinct subsequences of T in S. A subsequence ...
- BZOJ1095 [ZJOI2007]Hide 捉迷藏 【动态点分治 + 堆】
题目链接 BZOJ1095 题解 传说中的动态点分治,一直不敢碰 今日一会,感觉其实并不艰涩难懂 考虑没有修改,如果不用树形dp的话,就得点分治 对于每个重心,我们会考虑其分治的子树内所有点到它的距离 ...
- C++——OOP面向对象理解
从Rob Pike 的 Google+上的一个推看到了一篇叫<Understanding Object Oriented Programming>的文章,我先把这篇文章简述一下,然后再说说 ...
- 第九届蓝桥杯C/C++B组题解附代码
1.标题:第几天 2000年的1月1日,是那一年的第1天.那么,2000年的5月4日,是那一年的第几天? 125天 打开日历就ok 2. 标题:明码 汉字的字形存在于字库中,即便在今天,16点阵的字库 ...
- 毕业答辩的PPT攻略
关于内容: 1.一般概括性内容:课题标题.答辩人.课题执行时间.课题指导教师.课题的归属.致谢等. 2.课题研究内容:研究目的.方案设计(流程图).运行过程.研究结果.创新性.应用价值.有关课题延续 ...
- CRM系统主要业务流程思维导图
[CRM五策略] ❶对客户进行分类,不是根据规模,而是根据和你的关系,越细腻越好: ❷不定期更新客户资料,信息越全面越好: ❸主动对客户进行 ...
- Git菜鸟
1.git 和svn的差异 git和svn 最大的差异在于git是分布式的管理方式而svn是集中式的管理方式.如果不习惯用代码管理工具,可能比较难理解分布式管理和集中式管理的概念.下面介绍两种工具的工 ...
- bzoj3382 [Usaco2004 Open]Cave Cows 3 洞穴里的牛之三
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=3382 [题解] 套路题. 首先我们会发现曼哈顿距离不好处理,难道要写kdtree??? (k ...
- codefoeces problem 671D——贪心+启发式合并+平衡树
D. Roads in Yusland Mayor of Yusland just won the lottery and decided to spent money on something go ...