Kafka数据辅助和Failover
数据辅助与Failover
CAP理论(它具有一致性、可用性、分区容忍性)

CAP理论:分布式系统中,一致性、可用性、分区容忍性最多只可同时满足两个。一般分区容忍性都要求有保障,因此很多时候在可用性与一致性之间做权衡。
一致性方案
1.Master-slave
》RDBMS的读写分离即为典型的Master-slave方案
》同步复制可保证强一致性但会影响可用性(等master确保将数据复制给全部的slave,slave才返回结果)
》异步复制可提供高可用性但会降低一致性
2.WNR
》主要用于去中心化(P2P)的分布式系统,DynameDB与Cassandra即采用此方案
》N代表副本数,W代表每次写操作要保证的最少写成功的副本数,R代表每次读至少读取的副本数
》当W+R>N时,可保证每次读取的数据至少有一个副本具有最新的更新
》多个写操作的顺序难以保证,可能导致多副本间的写操作顺序不一致,Dynamo通过向量时钟保证最终一致性
3.Paxos及其变种
》Google的Chubby,Zookeeper的Zab,RAFT等
Kafka是如何权衡CA的呢?
Replica

如:
当一个Patiton副本数超过Broker时,就会报错
Data Replication要解决的问题
1.如何Propagate(扩散)消息
2.何时Commit
3.如何处理Replica恢复
4.如何处理Replica全部宕机
1.如何Propagate(扩散)消息
以写入数据为例,Patiton分为leader和follower,follower周期性的向leader pull数据(和consumer相似)。
在读取数据时,与数据库读写分离不一样,follower并不参与读取操作,读取只和leader有关。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
2.何时Commit

由上图可知,leader数据发送给follower既不是同步通信也不是异步通信,而是在一致性和可用性做了动态的平衡
3.如何处理Replica恢复
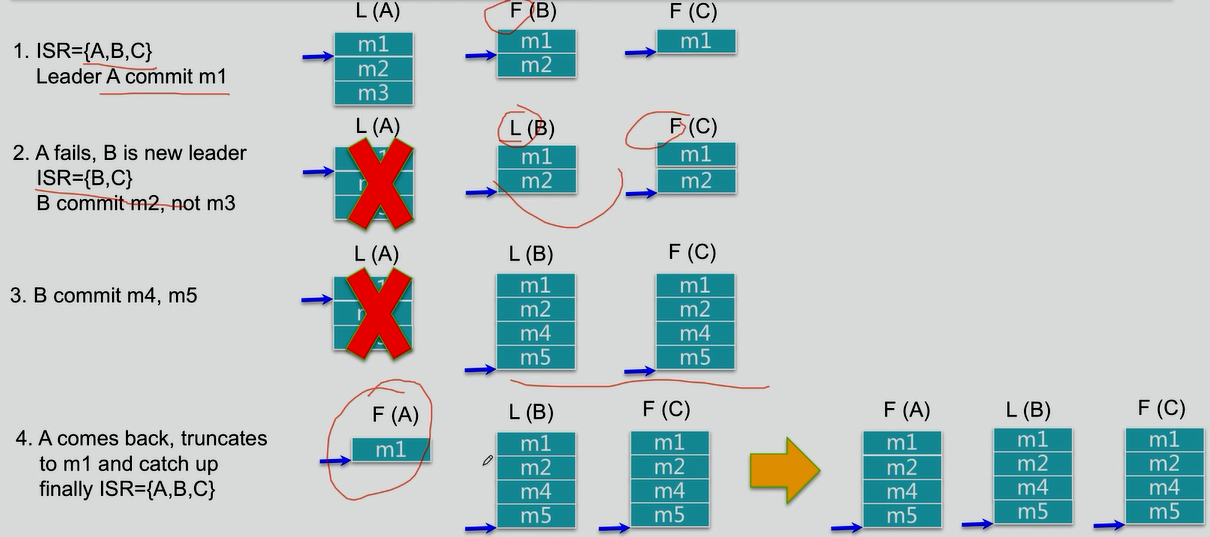
4.如何处理Replica全部宕机
等待ISR中任一Replica恢复,并选它为Leader
》等待时间较长,降低可用性
》或ISR中的所有Replica都无法恢复或者数据丢失,则该Patition将永不可用
选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
》可能会有数据丢失
》可用性较高
Kafka数据辅助和Failover的更多相关文章
- kafka数据祸福和failover
k CAP帽子理论. consistency:一致性 Availability:可用性 partition tolerance:分区容忍型 CA :mysql oracle(抛弃了网络分区) CP:h ...
- Gobblin采集kafka数据
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 找时间记录一下利用Gobblin采集kafka数据的过程,话不多说,进入正题 一.Gobblin ...
- java spark-streaming接收TCP/Kafka数据
本文将展示 1.如何使用spark-streaming接入TCP数据并进行过滤: 2.如何使用spark-streaming接入TCP数据并进行wordcount: 内容如下: 1.使用maven,先 ...
- Flink消费Kafka数据并把实时计算的结果导入到Redis
1. 完成的场景 在很多大数据场景下,要求数据形成数据流的形式进行计算和存储.上篇博客介绍了Flink消费Kafka数据实现Wordcount计算,这篇博客需要完成的是将实时计算的结果写到redis. ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- Spark Streaming接收Kafka数据存储到Hbase
Spark Streaming接收Kafka数据存储到Hbase fly spark hbase kafka 主要参考了这篇文章https://yq.aliyun.com/articles/60712 ...
- flume 读取kafka 数据
本文介绍flume读取kafka数据的方法 代码: /************************************************************************* ...
- Kafka数据安全性、运行原理、存储
直接贴面试题: 怎么保证数据 kafka 里的数据安全? 答: 生产者数据的不丢失kafka 的 ack 机制: 在 kafka 发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常的能够 ...
随机推荐
- MySql Connector/c++8中JSON处理Demo
#include <iostream> #include <vector> #include <mysqlx/xdevapi.h> using std::cout; ...
- Linux常用文档操作命令--1
1.查看目录下的文档 a) ls(list):查看目录下的所有文档或者文档的信息. 命令行:ls [-a][-A] [-f][-F][-h][-l][-r][-R][-S][-t] 目录名称 //注 ...
- springmvc处理器拦截器
处理器拦截器(interceptor)是做什么用的? 想知道处理拦截器做什么用的,你要先了解下处理·流程链·. 前端控制器(dispatcherServlet)接收到请求,通过handleMappin ...
- 一些斗鱼TV Web API [Some DouyuTv API]
一些斗鱼TV Web API [Some DouyuTv API] 写在最前 去年TI5前开发了dotaonly.com,网站需要用到各个直播平台API.不像国外网站Twitch那样开放,都有现成 ...
- 11 非阻塞套接字与IO多路复用(进阶)
1.非阻塞套接字 第一部分 基本IO模型 1.普通套接字实现的服务端的缺陷 一次只能服务一个客户端! 2.普通套接字实现的服务端的瓶颈!!! accept阻塞! 在没有新的套接字来之前,不能处理已经建 ...
- py3.7.1下pyinstaller 的安装及打包 坑
实在无语了,写了个小程序,用pyinstaller打包,运行就出现这个pip install pywin32-ctypes.明明全部都已经安装了啊. 解决办法: 不要在工程设置里安装pyinstall ...
- ruby net/http模块使用
ruby中的NET::HTTP:这里暂时先列出几个固定用法: 其中一,二不支持请求头设置(header取ruby默认值),只能用于基本的请求,不支持持久连接,如果您执行许多HTTP请求,则不推荐它们: ...
- Awakening Your Senses【唤醒你的感觉官能】
Awakening Your Senses Give youself a test. Which way is the wind blowing? How many kinds of wildflow ...
- spfa专题
SPFA专题 1通往奥格瑞玛的道路 在艾泽拉斯,有n个城市.编号为1,2,3,...,n. 城市之间有m条双向的公路,连接着两个城市,从某个城市到另一个城市,会遭到联盟的攻击,进而损失一定的血量. 每 ...
- LeetCode:15. 3Sum(Medium)
1. 原题链接 https://leetcode.com/problems/3sum/description/ 2. 题目要求 数组S = nums[n]包含n个整数,请问S中是否存在a,b,c三个整 ...