词法分析器--DFA(c++实现)
语言名为TINY
实例程序:
begin
var x,y:interger;
x:=;
read(x);
if y< then x:=x-y;
x:=x+y;
write(x);
end
TINY语言扫描程序的DFA: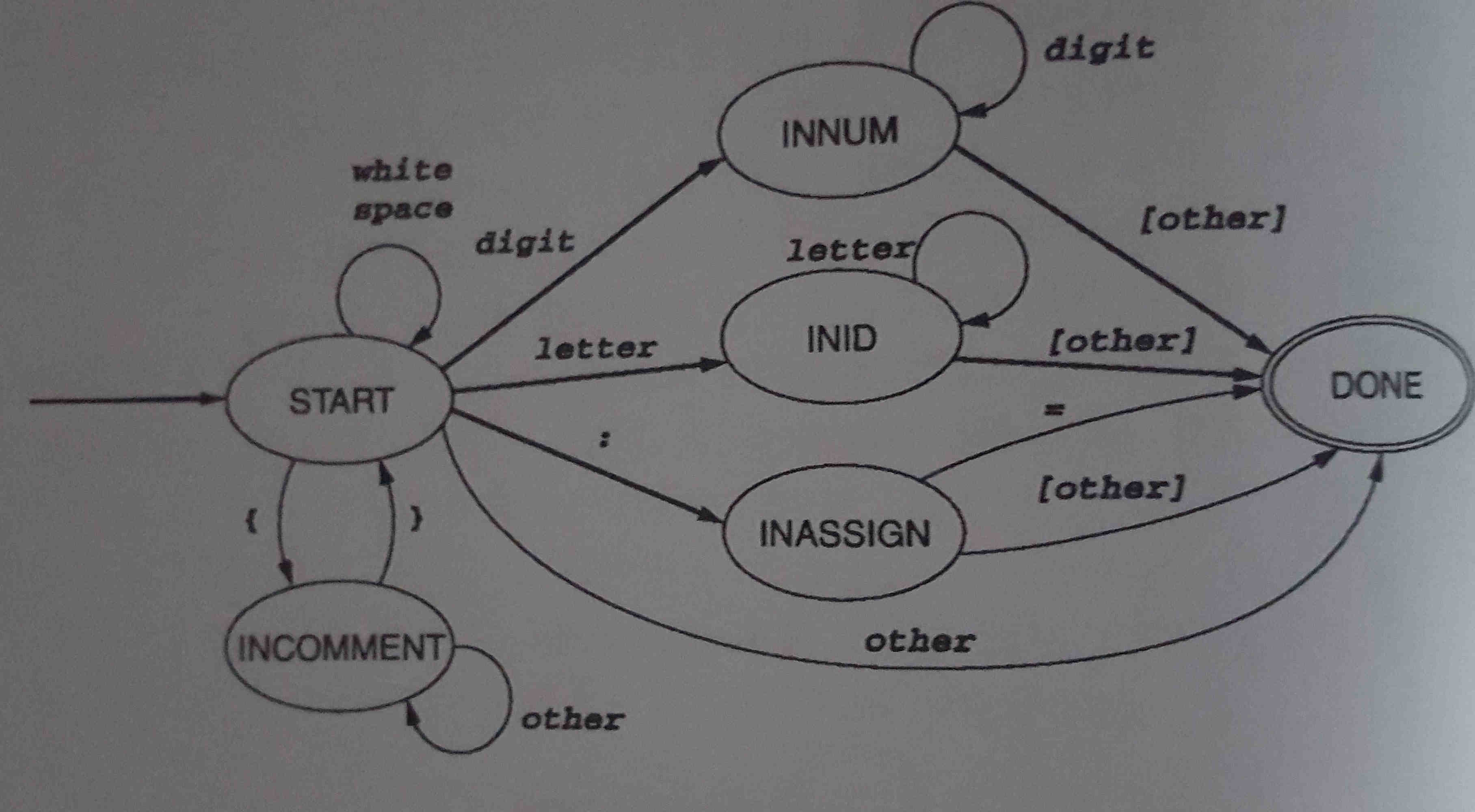
代码
//ExplLexicalAnalyzer.h
#ifndef EXPLLEXICALANALYZER_H
#define EXPLLEXICALANALYZER_H #define MAXTOKENLEN 40
#define MAXRESERVED 13 typedef enum {
ENDFILE, ERROR,
IF, THEN, ELSE, END, REPEAT, UNTIL, READ, WRITE, VAR, BEGIN, INTEGER, DOUBLE, STRING,
ID, NUM,
ASSIGN, EQ, LT, PLUS, MINUS, TIMES, OVER, LPAREN, RPAREN, SEMI, COMMA, DEFINE
} TokenType; //typedef struct {
// TokenType kind;
// int row = -1;
// int column = -1;
// double value;
// std::string ID;
//} Token; TokenType getToken(void); #endif //LEARN_2_EXPLLEXICALANALYZER_H
//ExplLexicalAnalyzer.cpp
#include <cstdio>
#include <iostream>
#include <fstream>
#include <cstring>
#include "ExplLexicalAnalyzer.h" using namespace std; typedef enum {
START, INASSIGN, INCOMMENT, INNUM, INID, DONE
} StateType; char tokenString[MAXTOKENLEN + ]; #define BUFLEN 256 static char lineBuf[BUFLEN];
static int linepos = ;
static int bufsize = ;
static int EOF_flag = false;
static string filename;
static fstream get;
static int lineno = ;
static int columnpos = ;
bool TraceScan = true;
StateType state; static struct {
const char *str;
TokenType tok;
} reservedWords[MAXRESERVED]
= {{"if", IF},
{"then", THEN},
{"else", ELSE},
{"end", END},
{"repeat", REPEAT},
{"until", UNTIL},
{"read", READ},
{"write", WRITE},
{"begin", BEGIN},
{"var", VAR},
{"interger", INTEGER},
{"double", DOUBLE},
{"string", STRING}}; static char
getNextChar() {
if (linepos >= bufsize) {
lineno = ;
if (state != START)
return ' ';
if (get.getline(lineBuf, BUFLEN - )) {
printf("%d: %s\n", columnpos++, lineBuf);
bufsize = (int) strlen(lineBuf);
linepos = ;
return lineBuf[linepos++];
} else {
return EOF;
}
} else return lineBuf[linepos++];
} static TokenType reservedLookup(char *s) {
int i;
for (i = ; i < MAXRESERVED; i++)
if (!strcmp(s, reservedWords[i].str))
return reservedWords[i].tok;
return ID;
} //退回一个字符
static void ungetNextChar(void) { if (!EOF_flag) linepos--; } //打印分析结果
void printToken(TokenType token, const char *tokenString) {
switch (token) {
case IF:
case THEN:
case ELSE:
case END:
case REPEAT:
case UNTIL:
case READ:
case WRITE:
case BEGIN:
case VAR:
case INTEGER:
case DOUBLE:
case STRING:
printf("reserved word: %s\n", tokenString);
break;
case DEFINE:
printf(":\n");
break;
case COMMA:
printf(",\n");
break;
case ASSIGN:
printf(":=\n");
break;
case LT:
printf("<\n");
break;
case EQ:
printf("=\n");
break;
case LPAREN:
printf("(\n");
break;
case RPAREN:
printf(")\n");
break;
case SEMI:
printf(";\n");
break;
case PLUS:
printf("+\n");
break;
case MINUS:
printf("-\n");
break;
case TIMES:
printf("*\n");
break;
case OVER:
printf("/\n");
break;
case ENDFILE:
break;
case NUM:
printf("NUM, val= %s\n", tokenString);
break;
case ID:
printf("ID, name= %s\n", tokenString);
break;
case ERROR:
printf("ERROR: %s\n", tokenString);
break;
default:
printf("Unknown token: %d\n", token);
}
} //词法分析
TokenType getToken(void) {
int tokenStringIndex = ;
TokenType currentToken;
state = START;
bool save;
while (state != DONE) {
char c = getNextChar();
save = true;
switch (state) {
case START:
if (isdigit(c))
state = INNUM;
else if (isalpha(c))
state = INID;
else if (c == ':')
state = INASSIGN;
else if ((c == ' ') || (c == '\t') || (c == '\n'))
save = false;
else if (c == '{') {
save = false;
state = INCOMMENT;
} else {
state = DONE;
switch (c) {
case EOF:
return ENDFILE;
case ',':
currentToken = COMMA;
break;
case '=':
currentToken = EQ;
break;
case '<':
currentToken = LT;
break;
case '+':
currentToken = PLUS;
break;
case '-':
currentToken = MINUS;
break;
case '*':
currentToken = TIMES;
break;
case '/':
currentToken = OVER;
break;
case '(':
currentToken = LPAREN;
break;
case ')':
currentToken = RPAREN;
break;
case ';':
currentToken = SEMI;
break;
default:
currentToken = ERROR;
break;
}
}
break;
case INCOMMENT:
save = false;
if (c == EOF) {
state = DONE;
currentToken = ENDFILE;
} else if (c == '}') state = START;
break;
case INASSIGN:
state = DONE;
if (c == '=')
currentToken = ASSIGN;
else {
currentToken = DEFINE;
ungetNextChar();
}
break;
case INNUM:
if (!isdigit(c)) {
ungetNextChar();
save = false;
state = DONE;
currentToken = NUM;
}
break;
case INID:
if (!isalpha(c)) {
tokenString[tokenStringIndex] = '\0';
if (!strcmp(tokenString, "begin") || !strcmp(tokenString, "end")) {
save = false;
state = DONE;
currentToken = ID;
break;
}
ungetNextChar();
save = false;
state = DONE;
currentToken = ID;
}
break;
case DONE:
break;
}
if ((save) && (tokenStringIndex <= MAXTOKENLEN) && (state != START && !isspace(c)))
tokenString[tokenStringIndex++] = c;
if (state == DONE) {
tokenString[tokenStringIndex] = '\0';
if (currentToken == ID)
currentToken = reservedLookup(tokenString);
}
}
if (TraceScan) {
printf("\t%d: ", lineno++);
printToken(currentToken, tokenString);
}
return currentToken;
} int
main() {
if (cin >> filename && filename == "q") {
filename = "......";
}
get.open(filename, ios::in);
while (getToken() != ENDFILE);
}
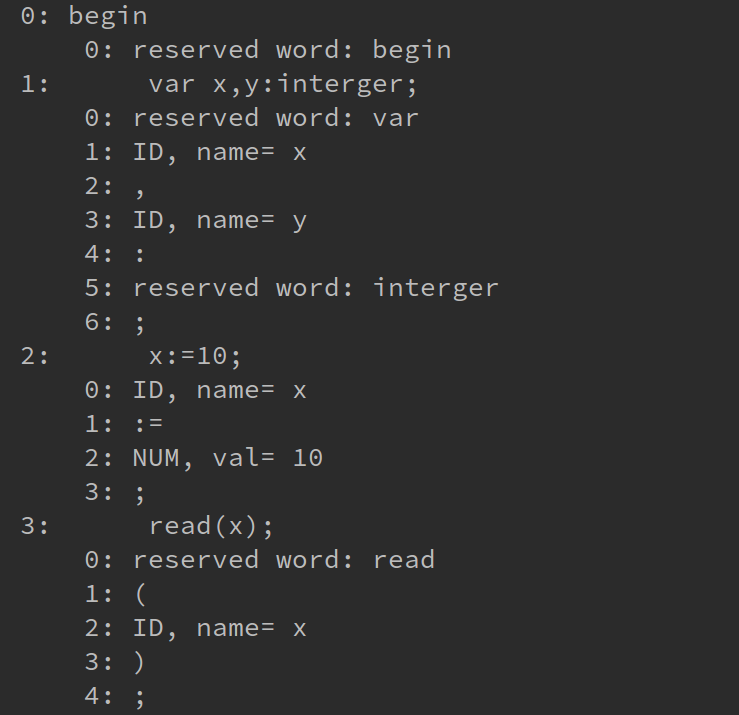
运行结果:
词法分析器--DFA(c++实现)的更多相关文章
- C# 词法分析器(五)转换 DFA
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 在上一篇文章中,已经得到了与正则表达式等价的 NFA ...
- 自动构造词法分析器的步骤——正规式转换为最小化DFA
正规式-->最小化DFA 1.先把正则式-->NFA(非确定有穷自动机) 涉及一系列分解规则 2.再把NFA通过"子集构造法"-->DFA 通过子集构造法将NFA ...
- 求子串-KPM模式匹配-NFA/DFA
求子串 数据结构中对串的5种最小操作子集:串赋值,串比较,求串长,串连接,求子串,其他操作均可在该子集上实现 数据结构中串的模式匹配 KPM模式匹配算法 基本的模式匹配算法 //求字串subStrin ...
- Atitit 词法分析器的设计最佳实践说明attilax总结
Atitit 词法分析器的设计最佳实践说明attilax总结 1.1. 手写的优点:代码可读,对源代码中的各种错误给出友好的提示信息,用户体验高,1 1.2. 使用状态表比较简单,dfa比较麻烦1 1 ...
- C# 词法分析器(一)词法分析介绍 update 2014.1.8
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 虽然文章的标题是词法分析,但首先还是要从编译原理说开 ...
- C# 词法分析器(二)输入缓冲和代码定位
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 一.输入缓冲 在介绍如何进行词法分析之前,先来说说一 ...
- C# 词法分析器(三)正则表达式
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 正则表达式是一种描述词素的重要表示方法.虽然正则表达 ...
- C# 词法分析器(四)构造 NFA
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 有了上一节中得到的正则表达式,那么就可以用来构造 N ...
- C# 词法分析器(六)构造词法分析器
系列导航 (一)词法分析介绍 (二)输入缓冲和代码定位 (三)正则表达式 (四)构造 NFA (五)转换 DFA (六)构造词法分析器 (七)总结 现在最核心的 DFA 已经成功构造出来了,最后一步就 ...
随机推荐
- Bootstrap_基本HTML模板
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- Android 网格布局 计算器
<GridLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools=&quo ...
- [转]Unity3d之MonoBehaviour的可重写函数整理
最近在学习Unity3d的知识.虽然有很多资料都有记录了,可是我为了以后自己复习的时候方便就记录下来吧!下面的这些函数在Unity3d程序开发中具有很重要的作用. Update 当MonoBehavi ...
- Python ftplib
http://automationtesting.sinaapp.com/blog/m_ftplib https://docs.python.org/2/library/ftplib.html 概述 ...
- SELECT时为何要加WITH(NOLOCK)
此文章非原创,仅为分享.学习!! 要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑.其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH ( ...
- CUBRID学习笔记 14 dll加载错误
这个问题通常是缺少文件cascci.dll 或者版本错误 32 64弄错了 C:\Program Files (x86)\Python266>python.exe Python 2.6.6 (r ...
- FJNU 1155 Fat Brother’s prediction(胖哥的预言)
FJNU 1155 Fat Brother’s prediction(胖哥的预言) Time Limit: 1000MS Memory Limit: 257792K [Description] [ ...
- 寻找Linux单机负载瓶颈
寻找Linux单机负载瓶颈 服务器性能上不去,是哪里出了问题?IO还是CPU?只有找到瓶颈点,才能对症下药: 如何寻找Linux单机负载瓶颈,遵循的原则是不要推测,我们要通过测量的数据说话: 负载分两 ...
- Bootstrap日期和时间表单组件运用兼容ie8
准备动作先到下载Bootstrap日期和时间组件. 1:引入bootstrap.min.css,因为bootstrap-datetimepicker里面的很多样式依赖bootstarp的主样式,字体文 ...
- 笔记本_hp
1.技术支持 http://support.hp.com/cn-zh 2.搜到的信息:“http://forum.51nb.com/thread-1080424-1-1.html” Product N ...