SpringCloud Sleuth
1.定义
Sleuth(分布式请求链路跟踪):提供了一套完整的服务跟踪解决方案,也兼容zipkin。
参考网址:https://github.com/spring-cloud/spring-cloud-sleuth
2.项目开发
源代码:https://github.com/zhongyushi-git/cloud-sleuth.git
2.1环境搭建
这里需要下载zipkin的jar才能使用。
1)zipkin下载地址:https://dl.bintray.com/openzipkin/maven/io/zipkin/java/zipkin-server/2.12.9/zipkin-server-2.12.9-exec.jar
2)在下载的jar目录下执行命令
java -jar zipkin-server-2.12.9-exec.jar
看到下图说明配置成功
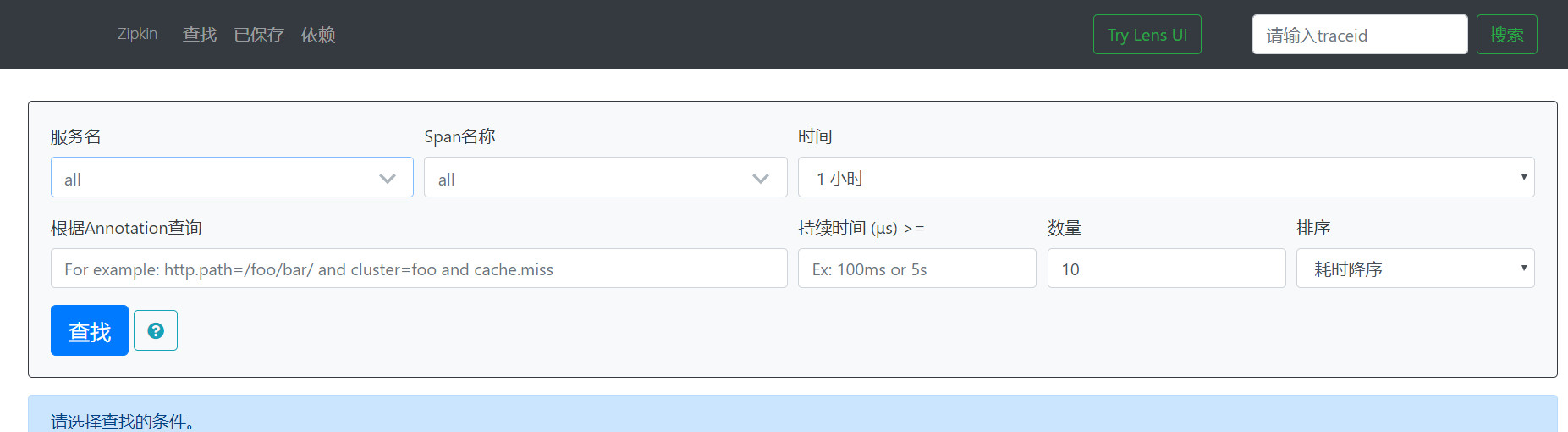
3)访问http://localhost:9411/zipkin/可看到相关的页面,主要用来查看请求的调用记录的。
2.2父工程搭建
创建一个maven的父工程cloud-sleuth,导入依赖
<!--统一管理jar包版本-->
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
</properties>
<!-- 依赖管理,父工程锁定版本-->
<dependencyManagement>
<dependencies>
<!--spring boot 2.2.2-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud Hoxton.SR1-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<!--log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
</plugin>
</plugins>
</build>
2.3注册服务eureka
1)创建一个子工程cloud-eureka-server7001,导入依赖
2)yml配置
server:
port: 7001 eureka:
instance:
#eureka服务端的实例名称
#单机版
hostname: localhost
client:
#false表示不向注册中心注册自己
register-with-eureka: false
#false表示自己端就是注册中心,我的职责就是维护服务实例,并不需要去检索服务
fetch-registry: false
service-url:
#设置与Eureka Server交互的地址查询服务和注册服务都需要依赖这个地址
#单机版
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; @SpringBootApplication
@EnableEurekaServer
public class EurekaMain7001 {
public static void main(String[] args) {
SpringApplication.run(EurekaMain7001.class, args);
}
}
2.4服务提供者模块
1)创建一个子工程cloud-provider8001作为服务消费者,导入依赖
<dependencies>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--eureka-client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
2)yml配置
server:
port: 8001 spring:
application:
name: cloud-provider
zipkin:
#监控地查看址
base-url: http://localhost:9411
sleuth:
sampler:
#采样率
probability: 1 #把客户端注册到服务列表中
eureka:
client:
#表示是否将自己注册进EurekaServer默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
#单机版
defaultZone: http://localhost:7001/eureka
#设置入驻的服务的名称,是唯一的
instance:
instance-id: cloud-provider
#访问路径显示ip
prefer-ip-address: true
里面主要是配置了ziplin的相关信息。
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication
@EnableEurekaClient
public class ProviderMain8001 {
public static void main(String[] args) {
SpringApplication.run(ProviderMain8001.class, args);
}
}
4)在包下新建controller接口
package com.zys.cloud.controller; import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController; @RestController
public class UserController {
@Value("${server.port}")
private String port; @GetMapping("/user/get")
public String get() {
return "provider port is :" + port;
} }
2.5服务消费者模块
1)创建一个子工程cloud-provider8001作为服务消费者,导入依赖
<dependencies>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!--eureka-client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<!--包含了sleuth+zipkin-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
</dependencies>
2)yml配置
server:
port: 80 spring:
application:
name: cloud-consumer
zipkin:
#监控地查看址
base-url: http://localhost:9411
sleuth:
sampler:
#采样率
probability: 1 #把客户端注册到服务列表中
eureka:
client:
#表示是否将自己注册进EurekaServer默认为true
register-with-eureka: true
#是否从EurekaServer抓取已有的注册信息,默认为true。单节点无所谓,集群必须设置为true才能配合ribbon使用负载均衡
fetch-registry: true
service-url:
#单机版
defaultZone: http://localhost:7001/eureka
#设置入驻的服务的名称,是唯一的
instance:
instance-id: cloud-provider
#访问路径显示ip
prefer-ip-address: true
3)创建包com.zys.cloud,包下创建启动类
package com.zys.cloud; import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient; @SpringBootApplication
@EnableEurekaClient
public class ConsumerMain80 {
public static void main(String[] args) {
SpringApplication.run(ConsumerMain80.class, args);
}
}
4)在包下新建config的配置类
package com.zys.cloud.config; import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate; //相当于spring中的applicationContext.xml
@Configuration
public class ConfigBean { @Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
5)在包下新建controller接口
package com.zys.cloud.controller; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.client.RestTemplate; import java.util.Map; @RestController
@RequestMapping("/consumer")
public class UserController {
private final String BASE_URL="http://cloud-provider"; @Autowired
private RestTemplate restTemplate; @GetMapping("/get")
public String get(){
return restTemplate.getForObject(BASE_URL+"/user/get",String.class);
} }
2.6测试
先启动7001,然后启动8001,最后启动80。访问http://localhost/consumer/get,然后再回到zipkin的页面,发现服务名多了两个,分别是设置的消费者和生产者。
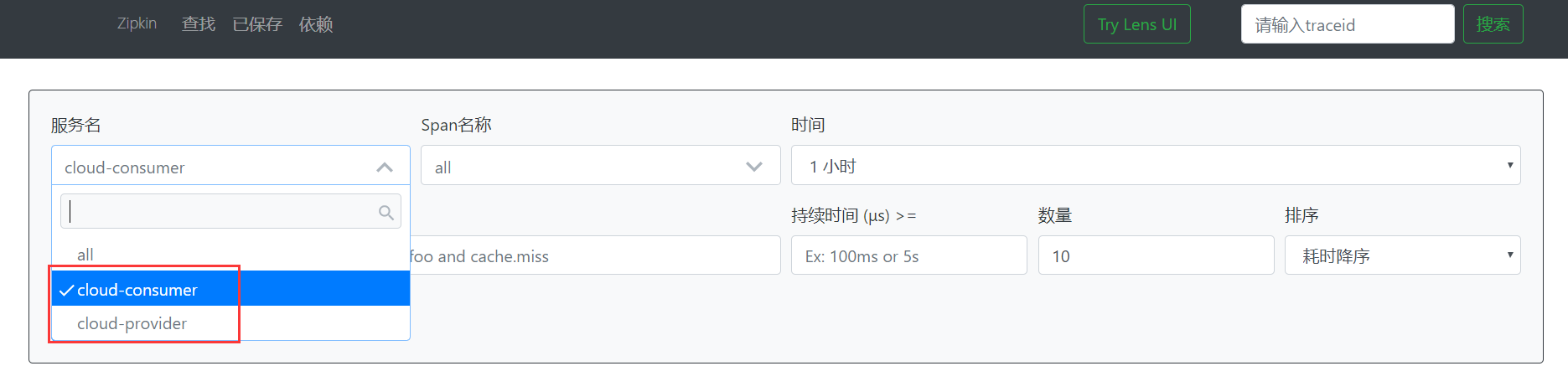
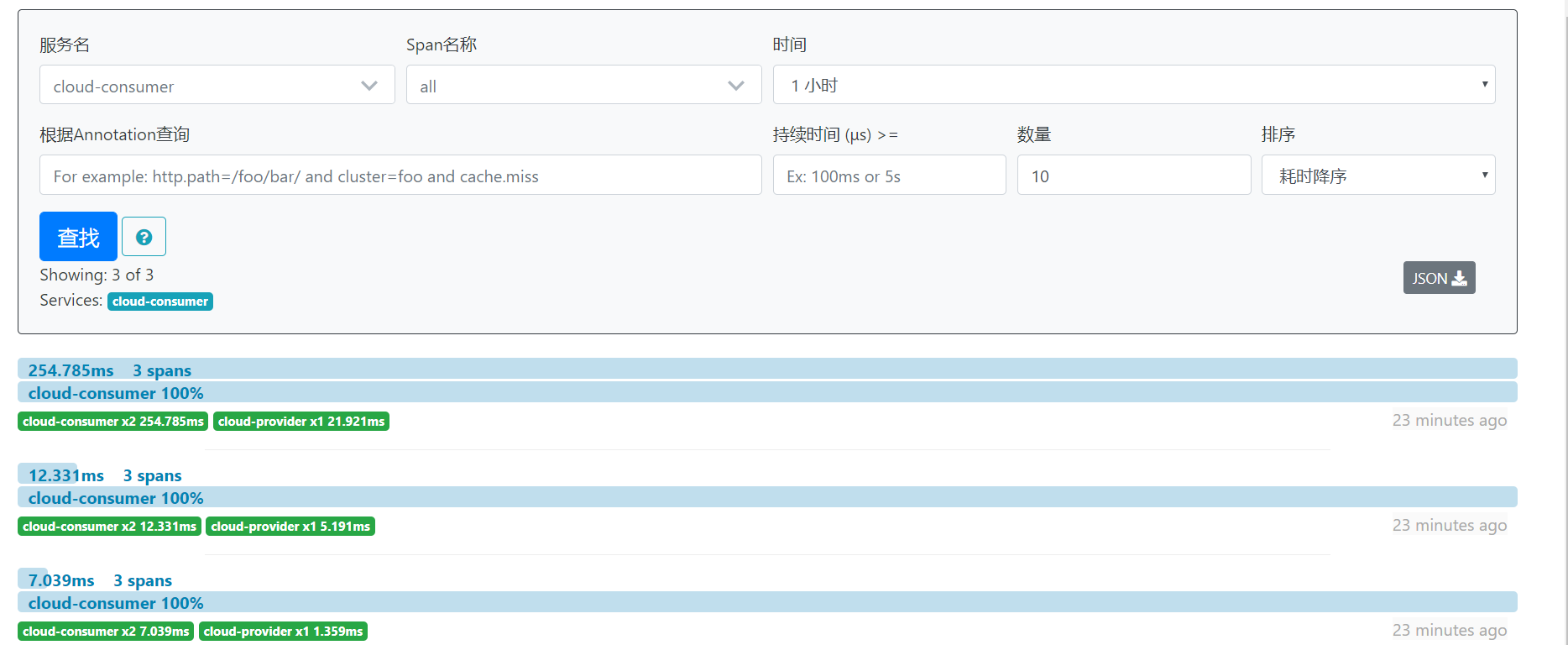
选择一个服务后点击查找,就会显示出链路信息
SpringCloud Sleuth的更多相关文章
- 新版本SpringCloud sleuth整合zipkin
SpringCloud Sleuth 简介 Spring Cloud Sleuth为Spring Cloud实现了分布式跟踪解决方案. Spring Cloud Sleuth借鉴了Dapper的术语. ...
- SpringCloud Sleuth + Zipkin 实现链路追踪
一.Sleuth介绍 为什么要使用微服务跟踪? 它解决了什么问题? 1.微服务的现状? 随着业务的发展,单体架构变为微服务架构,并且系统规模也变得越来越大,各微服务间的调用关系也变得越来越复杂 ...
- SpringCloud学习笔记(十、SpringCloud Sleuth)
目录: 什么是SpringCloud Sleuth 为什么使用SpringCloud Sleuth 如何使用SpringCloud Sleuth 什么是SpringCloud Sleuth: Spri ...
- springcloud -- sleuth+zipkin整合rabbitMQ详解
为什么使用RabbitMQ? 我们已经知道,zipkin的原理是服务之间的调用关系会通过HTTP方式上报到zipkin-server端,然后我们再通过zipkin-ui去调用查看追踪服务之间的调用链路 ...
- SpringCloud Sleuth 使用
1. 介绍 Spring-Cloud-Sleuth是Spring Cloud的组成部分之一,为SpringCloud应用实现了一种分布式追踪解决方案,其兼容了Zipkin, HTrace和log- ...
- SpringCloud Sleuth入门介绍
案例代码:https://github.com/q279583842q/springcloud-e-book 一.Sleuth介绍 为什么要使用微服务跟踪?它解决了什么问题? 1.微服务的现状? ...
- SpringCloud入门(十一):Sleuth 与 Zipkin分布式链路跟踪
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文<Dapper, a Large-Scale Distributed Systems Tracing Infrastructu ...
- 学习一下 SpringCloud (五)-- 配置中心 Config、消息总线 Bus、链路追踪 Sleuth、配置中心 Nacos
(1) 相关博文地址: 学习一下 SpringCloud (一)-- 从单体架构到微服务架构.代码拆分(maven 聚合): https://www.cnblogs.com/l-y-h/p/14105 ...
- SpringCloud(八)Sleuth 分布式请求链路跟踪
SpringCloud Sleuth 分布式请求链路跟踪 概述 为什么会出现这个技术?需要解决哪些问题? 在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后 ...
随机推荐
- 22.firewalld
1.firewalld 中常用的区域名称及策略规则 2.firewalld-cmd 命令中使用的参数以及作用 与 Linux 系统中其他的防火墙策略配置工具一样,使用firewalld 配置的防火墙策 ...
- Java之jdk环境变量配置
1.jdk下载(按平时下载,注意一下路径就行)2.配置环境变量 :JAVA_HOME.Path.ClassPath3.检查是否成功:(查一下版本,可省略).运行环境(java.javac) 2:电脑- ...
- Scala数据结构(数组,Map和Tuple)
package com.zy import scala.collection.mutable import scala.collection.mutable.ArrayBuffer object te ...
- 2020牛客暑期多校训练营(第五场)B - Graph (异或 最小生成树 分治 Trie)
B - Graph 题目链接 每次操作不会改变两点之间的路径异或和 以 1 号点为起点,算出任意一点到 1 号点的异或值 dis[i](把该值当做 i 号点权值), 那么任意两点的异或值为 \(dis ...
- Luogu4168 蒲公英 (分块)
题目传送门 题意 长度为n的序列,有m次询问,每次询问求\([l,r]\) 间的众数,如果有多个,输出最小的那个 \(n\le 4\times 10^4,m\le 5\times 10^5,a_i\l ...
- 【uva 11572】Unique Snowflakes(算法效率--滑动窗口,3种实现方法)
题意:求长度为N的序列中,最长的一个无重复元素的连续子序列. 解法:[L,R]每次R++或L++延伸就可以得到答案. 实现:(1)next[],last[]--O(n): 1 #include< ...
- STL中pair容器的用法
1.定义pair容器 1 pair <int, int> p, p1; 2 //定义 [int,int] 型容器 //直接初始化了p的内容 pair<string,int>p( ...
- Codeforces Round #663 (Div. 2) C. Cyclic Permutations (构造,图?)
题意:对于某个序列,若\(1\le i\le n\),\(1\le j\le i\)且\(p_j>p_i\),或者\(1\le i\le n\),\(i<j \le n\)且\(p_j&g ...
- Codeforces Round #654 (Div. 2) D. Grid-00100 (构造)
题意:构造一个\(n\)x\(n\)只含\(0\)和\(k\)个\(1\)的矩阵,统计每一行每一列\(1\)的sum,然后构造一个权值最大行和最小行的差的平方加权值最大列和最小列的差的平方的最小和(\ ...
- HDU - 4722 Good Numbers 【找规律 or 数位dp模板】
If we sum up every digit of a number and the result can be exactly divided by 10, we say this number ...