使用pytorch快速搭建神经网络实现二分类任务(包含示例)
使用pytorch快速搭建神经网络实现二分类任务(包含示例)
Introduce
上一篇学习笔记介绍了不使用pytorch包装好的神经网络框架实现logistic回归模型,并且根据autograd实现了神经网络参数更新。
本文介绍利用pytorch快速搭建神经网络。即利用torch.nn以及torch.optim库来快捷搭建一个简单的神经网络来实现二分类功能。
- 利用pytorch已经包装好的库(torch.nn)来快速搭建神经网络结构。
- 利用已经包装好的包含各种优化算法的库(torch.optim)来优化神经网络中的参数,如权值参数w和阈值参数b。
以下均为初学者笔记。
Build a neural network structure
假设我们要搭建一个带有两个隐层的神经网络来实现节点的二分类,输入层包括2个节点(输入节点特征),两个隐层均包含5个节点(特征映射),输出层包括2个节点(分别输出属于对应节点标签的概率)。如下图所示:
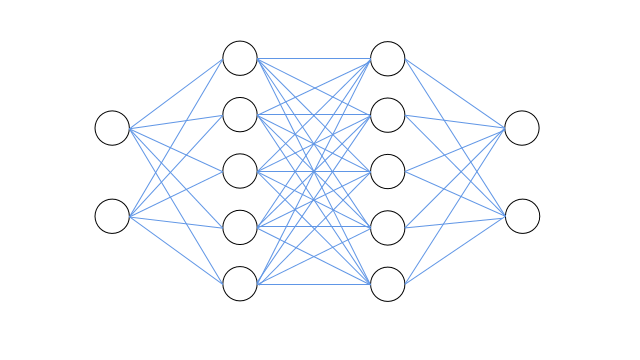
上图从左右到右为输入层、隐藏层、隐藏层、输出层,各层之间采用全连接结构。神经网络两隐藏层的激活函数均采用sigmoid函数,输出层最后采用softmax函数归一化概率。
网络搭建过程中使用的torch.nn相关模块介绍如下:
- torch.nn.Sequential:是一个时序容器,我们可以通过调用其构造器,将神经网络模块按照输入层到输出层的顺序传入,以此构造完整的神经网络结构,具体用法参考如下神经网络搭建代码。
- torch.nn.Linear:设置网络中的全连接层,用来实现网络中节点输入的线性求和,即实现如下线性变换函数:
\]
'''
搭建神经网络,
输入层包括2个节点,两个隐层均包含5个节点,输出层包括1个节点。'''
net = nn.Sequential(
nn.Linear(2,5), # 输入层与第一隐层结点数设置,全连接结构
torch.nn.Sigmoid(), # 第一隐层激活函数采用sigmoid
nn.Linear(5,5), # 第一隐层与第二隐层结点数设置,全连接结构
torch.nn.Sigmoid(), # 第一隐层激活函数采用sigmoid
nn.Linear(5,2), # 第二隐层与输出层层结点数设置,全连接结构
nn.Softmax(dim=1) # 由于有两个概率输出,因此对其使用Softmax进行概率归一化,dim=1代表行归一化
)
print(net)
'''
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Sigmoid()
(2): Linear(in_features=5, out_features=5, bias=True)
(3): Sigmoid()
(4): Linear(in_features=5, out_features=2, bias=True)
(5): Softmax(dim=1)
)'''
Configure Loss Function and Optimizer
note: torch.optim库中封装了许多常用的优化方法,这边使用了最常用的随机梯度下降来优化网络参数。例子中使用了交叉熵损失作为代价函数,其实torch.nn中也封装了许多代价函数,具体可以查看官方文档。对于pytorch中各种损失函数的学习以及优化方法的学习将在后期进行补充。
配置损失函数和优化器的代码如下所示:
# 配置损失函数和优化器
optimizer = torch.optim.SGD(net.parameters(),lr=0.01) # 优化器使用随机梯度下降,传入网络参数和学习率
loss_func = torch.nn.CrossEntropyLoss() # 损失函数使用交叉熵损失函数
Model Training
神经网络训练过程大致如下:首先输入数据,接着神经网络进行前向传播,计算输出层的输出,进而计算预先定义好的损失(如本例中的交叉熵损失),接着进行误差反向传播,利用事先设置的优化方法(如本例中的随机梯度下降SGD)来更新网络中的参数,如权值参数w和阈值参数b。接着反复进行上述迭代,达到最大迭代次数(num_epoch)或者损失值满足某条件之后训练停止,从而我们可以得到一个由大量数据训练完成的神经网络模型。模型训练的代码如下所示:
# 模型训练
num_epoch = 10000 # 最大迭代更新次数
for epoch in range(num_epoch):
y_p = net(x_t) # 喂数据并前向传播
loss = loss_func(y_p,y_t.long()) # 计算损失
'''
PyTorch默认会对梯度进行累加,因此为了不使得之前计算的梯度影响到当前计算,需要手动清除梯度。
pyTorch这样子设置也有许多好处,但是由于个人能力,还没完全弄懂。
'''
optimizer.zero_grad() # 清除梯度
loss.backward() # 计算梯度,误差回传
optimizer.step() # 根据计算的梯度,更新网络中的参数
if epoch % 1000 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.data.item()))
'''
每1000次输出损失如下:
epoch: 0, loss: 0.7303197979927063
epoch: 1000, loss: 0.669952392578125
epoch: 2000, loss: 0.6142827868461609
epoch: 3000, loss: 0.5110923051834106
epoch: 4000, loss: 0.4233965575695038
epoch: 5000, loss: 0.37978556752204895
epoch: 6000, loss: 0.3588798940181732
epoch: 7000, loss: 0.3476340174674988
......
'''
print("所有样本的预测标签: \n",torch.max(y_p,dim = 1)[1])
'''
note:可以发现前100个标签预测为0,后100个样本标签预测为1。因此所训练模型可以正确预测训练集标签。
所有样本的预测标签:
tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
'''
网络的保存和提取
'''两种保存方式
第一种: 保存网络的所有参数(包括网络结构)
torch.save(net,'net.pkl')
对应加载方式: net1 = torch.load('net.pkl')
第二种: 仅保存网络中需要训练的参数 ,即net.state_dict(),如权值参数w和阈值参数b。(不包括网络结构)
torch.save(net.state_dict(),'net_parameter.pkl')
对应加载方式:
加载时需要提供两个信息:
第一: 网络结构信息,需要先重新搭建和保存的网络同样的网络结构。
第二: 保存的网络中的参数的信息,权值和阈值参数。
具体加载方式如下:
net = nn.Sequential(
nn.Linear(2,5),
torch.nn.Sigmoid(),
nn.Linear(5,5),
torch.nn.Sigmoid(),
nn.Linear(5,2),
nn.Softmax(dim=1)
)
net2.load_state_dict(torch.load('net_parameter.pkl')
'''
附完整代码
import torch
import torch.nn as nn
'''
使用正态分布随机生成两类数据
第一类有100个点,使用均值为2,标准差为1的正态分布随机生成,标签为0。
第二类有100个点,使用均值为-2,标准差为1的正态分布随机生成,标签为1。
torch.normal(tensor1,tensor2)
输入两个张量,tensor1为正态分布的均值,tensor2为正态分布的标准差。
torch.normal以此抽取tensor1和tensor2中对应位置的元素值构造对应的正态分布以随机生成数据,返回数据张量。
'''
x1_t = torch.normal(2*torch.ones(100,2),1)
y1_t = torch.zeros(100)
x2_t = torch.normal(-2*torch.ones(100,2),1)
y2_t = torch.ones(100)
x_t = torch.cat((x1_t,x2_t),0)
y_t = torch.cat((y1_t,y2_t),0)
'''
搭建神经网络,
输入层包括2个节点,两个隐层均包含5个节点,输出层包括1个节点。
'''
net = nn.Sequential(
nn.Linear(2,5), # 输入层与第一隐层结点数设置,全连接结构
torch.nn.Sigmoid(), # 第一隐层激活函数采用sigmoid
nn.Linear(5,5), # 第一隐层与第二隐层结点数设置,全连接结构
torch.nn.Sigmoid(), # 第一隐层激活函数采用sigmoid
nn.Linear(5,2), # 第二隐层与输出层层结点数设置,全连接结构
nn.Softmax(dim=1) # 由于有两个概率输出,因此对其使用Softmax进行概率归一化
)
print(net)
'''
Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Sigmoid()
(2): Linear(in_features=5, out_features=5, bias=True)
(3): Sigmoid()
(4): Linear(in_features=5, out_features=2, bias=True)
(5): Softmax(dim=1)
)'''
# 配置损失函数和优化器
optimizer = torch.optim.SGD(net.parameters(),lr=0.01) # 优化器使用随机梯度下降,传入网络参数和学习率
loss_func = torch.nn.CrossEntropyLoss() # 损失函数使用交叉熵损失函数
# 模型训练
num_epoch = 10000 # 最大迭代更新次数
for epoch in range(num_epoch):
y_p = net(x_t) # 喂数据并前向传播
loss = loss_func(y_p,y_t.long()) # 计算损失
'''
PyTorch默认会对梯度进行累加,因此为了不使得之前计算的梯度影响到当前计算,需要手动清除梯度。
pyTorch这样子设置也有许多好处,但是由于个人能力,还没完全弄懂。
'''
optimizer.zero_grad() # 清除梯度
loss.backward() # 计算梯度,误差回传
optimizer.step() # 根据计算的梯度,更新网络中的参数
if epoch % 1000 == 0:
print('epoch: {}, loss: {}'.format(epoch, loss.data.item()))
'''
torch.max(y_p,dim = 1)[0]是每行最大的值
torch.max(y_p,dim = 1)[0]是每行最大的值的下标,可认为标签
'''
print("所有样本的预测标签: \n",torch.max(y_p,dim = 1)[1])
使用pytorch快速搭建神经网络实现二分类任务(包含示例)的更多相关文章
- pytorch 6 build_nn_quickly 快速搭建神经网络
import torch import torch.nn.functional as F # replace following class code with an easy sequential ...
- 逻辑回归(Logistic Regression)二分类原理及python实现
本文目录: 1. sigmoid function (logistic function) 2. 逻辑回归二分类模型 3. 神经网络做二分类问题 4. python实现神经网络做二分类问题 1. si ...
- 用Keras搭建神经网络 简单模版(二)——Classifier分类(手写数字识别)
# -*- coding: utf-8 -*- import numpy as np np.random.seed(1337) #for reproducibility再现性 from keras.d ...
- Tensorflow学习:(二)搭建神经网络
一.神经网络的实现过程 1.准备数据集,提取特征,作为输入喂给神经网络 2.搭建神经网络结构,从输入到输出 3.大量特征数据喂给 NN,迭代优化 NN 参数 4.使 ...
- keras搭建神经网络快速入门笔记
之前学习了tensorflow2.0的小伙伴可能会遇到一些问题,就是在读论文中的代码和一些实战项目往往使用keras+tensorflow1.0搭建, 所以本次和大家一起分享keras如何搭建神经网络 ...
- [DeeplearningAI笔记]卷积神经网络4.1-4.5 人脸识别/one-shot learning/Siamase网络/Triplet损失/将面部识别转化为二分类问题
4.4特殊应用:人脸识别和神经网络风格转换 觉得有用的话,欢迎一起讨论相互学习~Follow Me 4.1什么是人脸识别 Face verification人脸验证 VS face recogniti ...
- 【pytorch】学习笔记(四)-搭建神经网络进行关系拟合
[pytorch学习笔记]-搭建神经网络进行关系拟合 学习自莫烦python 目标 1.创建一些围绕y=x^2+噪声这个函数的散点 2.用神经网络模型来建立一个可以代表他们关系的线条 建立数据集 im ...
- 从零到一快速搭建个人博客网站(域名自动跳转www,二级域名使用)(二)
前言 本篇文章是对上篇文章从零到一快速搭建个人博客网站(域名备案 + https免费证书)(一)的完善,比如域名自动跳转www.二级域名使用等. 域名自动跳转www 这里对上篇域名访问进行优化,首先支 ...
- 利用 TFLearn 快速搭建经典深度学习模型
利用 TFLearn 快速搭建经典深度学习模型 使用 TensorFlow 一个最大的好处是可以用各种运算符(Ops)灵活构建计算图,同时可以支持自定义运算符(见本公众号早期文章<Tenso ...
随机推荐
- jmeter设置HTTP代理,录制APP脚本
1.打开jmeter,“工作台”右键——“添加”——“非测试元件”——“HTTP代理服务器” 2.设置端口号,手机需与这里的端口号一致 3.新建线程组,“测试计划”右键——“添加”——“Threads ...
- day77 vue对象提供的属性功能
目录 一.过滤器 二.计算属性(computed) 三.侦听属性(watch) 四.vue对象的生命周期 五.阻止事件冒泡和刷新页面 六.综合案例-todolist 一.过滤器 定义:就是vue允许开 ...
- day56 js收尾,jQuery前戏
目录 一.原生js事件绑定 1 开关灯案例 2 input框获取焦点,失去焦点案例 3 实现展示当前时间,定时功能 4 省市联动 二.jQuery入门 1 jQuery的两种导入方式 1.1 直接下载 ...
- 基层教师 - CMD命令之net命令与IPC连接
1)建立空连接: net use \\IP\ipc$ "" /user:"" (一定要注意:这一行命令中包含了3个空格) 2)建立非空连接: net use \ ...
- 机器学习实战基础(二十六):sklearn中的降维算法PCA和SVD(七) 附录
- Mybatis执行流程浅析(附深度文章推荐&面试题集锦)
首先推荐一个简单的Mybatis原理视频教程,可以作为入门教程进行学习:点我 (该教程讲解的是如何手写简易版Mybatis) 执行流程的理解 理解Mybatis的简单流程后自己手写一个,可以解决百分之 ...
- Java8之Stream 集合聚合操作集锦(含日常练习Demo)
Stream 是用函数式编程方式在集合类上进行复杂操作的工具,其集成了Java 8中的众多新特性之一的聚合操作,开发者可以更容易地使用Lambda表达式,并且更方便地实现对集合的查找.遍历.过滤以及常 ...
- OSCP Learning Notes - WebApp Exploitation(2)
Cross-Site Scripting(XSS) 1. Using the tool - netdiscover to find the IP of target server. netdiscov ...
- 线性dp 之 麻烦的聚餐
题目描述 为了避免餐厅过分拥挤,FJ要求奶牛们分3批就餐.每天晚饭前,奶牛们都会在餐厅前排队入内,按FJ的设想,所有第3批就餐的奶牛排在队尾,队伍的前端由设定为第1批就餐的奶牛占据,中间的位置就归第2 ...
- Shell基本语法---for语句
for语句 格式 ()for 变量名 in 值1 值2 值3 do 执行动作 done ()for 变量名 in `命令` do 执行动作 done ()for (( 条件 )) do 执行动作 do ...