C++学习---二叉树的输入及非递归遍历
二叉树的二叉链表存储表示如下
//二叉树的二叉链表存储表示
typedef struct BiTNode {
char data;//结点数据域
struct BiTNode* lchild, * rchild;//左右孩子指针
}*BiTree;
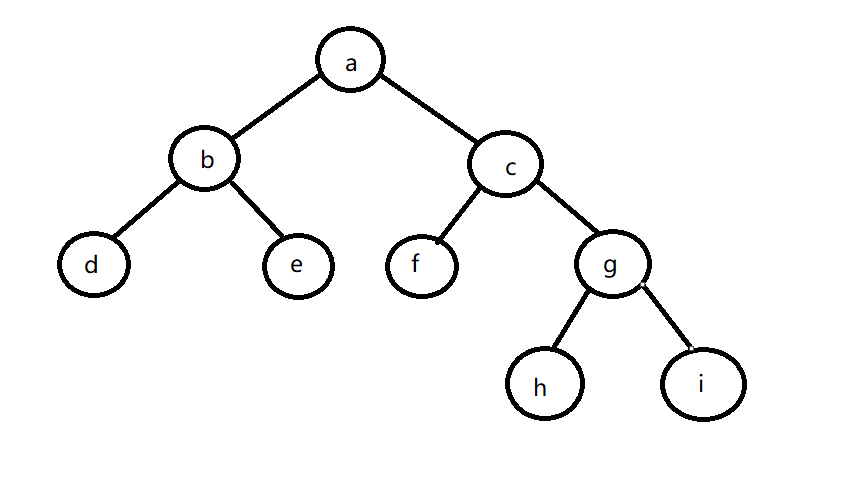
根据括号表示法的字符串创建树(括号里的表示括号前结点的子结点,‘,’号左边是左子结点,右边是右子结点)
比如:a(b(d,e),c(f,g(h,i)))
表示的则是
//创建树
void CreateBiTree(BiTree& T)
{
stack<BiTNode*> s;//用于确定需要操作的结点
BiTNode* p=NULL;
int i = 0;
bool child_Direct;//0表示左子结点,1表示右子结点
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
string TreeStr;
cin >> TreeStr;
while (TreeStr[i] != '\0') {
switch (TreeStr[i])
{
case'('://左子结点
s.push(p);
child_Direct = false;
break;
case')':
s.pop();
case','://右子结点
child_Direct = true;
break; default:
p = new BiTNode;
p->data = TreeStr[i];
p->lchild = p->rchild = NULL;
if (T == NULL)//若根节点为空则p指向根节点
T = p;
else {
if (!child_Direct)
s.top()->lchild = p;
else
s.top()->rchild = p;
}
break;
}
i++;
} }
非递归先序、中序、后序遍历
先序:
void PreOrderTraverse(BiTree T) {
stack<BiTNode*> s;
BiTNode* p = T, * q = new BiTNode();
while (p != NULL || !s.empty()) {
if (p)//p非空
{
cout << p->data;
s.push(p);//根指针入栈
p = p->lchild;//遍历左子树
}
else {
p = s.top();
s.pop();
p = p->rchild;//遍历右子树
}
}
}
中序:
//中序遍历
void InOrderTraverse(BiTree T) {
stack<BiTNode*> s;
BiTNode* p = T, * q = new BiTNode();
while (p != NULL || !s.empty()) {
if (p)//p非空
{
s.push(p);//根指针入栈
p = p->lchild;//遍历左子树
}
else {
p = s.top();
s.pop();
cout << p->data;
p = p->rchild;//遍历右子树
}
}
}
后序:
//后序遍历
void PostOrderTraverse(BiTree T) {
BiTNode* p = T, * r = NULL;
stack<BiTNode*> s;
while (p != NULL || !s.empty()) {
if (p != NULL) {//走到最左边
s.push(p);
p = p->lchild;
}
else {
p = s.top();
if (p->rchild != NULL && p->rchild != r)//右子树存在,未被访问
p = p->rchild;
else {
s.pop();
cout << p->data;
r = p;//记录最近访问过的节点
p = NULL;//节点访问完后,重置p指针
}
}//else
}//while }
完整代码
#include <iostream>
#include <stack>
#include <string>
using namespace std; //二叉树的二叉链表存储表示
typedef struct BiTNode {
char data;//结点数据域
struct BiTNode* lchild, * rchild;//左右孩子指针
}*BiTree; void Initial(BiTree& T) {
T = new BiTNode;
T = NULL;
}
//创建树
void CreateBiTree(BiTree& T)
{
stack<BiTNode*> s;//用于确定需要操作的结点
BiTNode* p=NULL;
int i = 0;
bool child_Direct;//0表示左子结点,1表示右子结点
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
string TreeStr;
cin >> TreeStr;
while (TreeStr[i] != '\0') {
switch (TreeStr[i])
{
case'('://左子结点
s.push(p);
child_Direct = false;
break;
case')':
s.pop();
case','://右子结点
child_Direct = true;
break; default:
p = new BiTNode;
p->data = TreeStr[i];
p->lchild = p->rchild = NULL;
if (T == NULL)//若根节点为空则p指向根节点
T = p;
else {
if (!child_Direct)
s.top()->lchild = p;
else
s.top()->rchild = p;
}
break;
}
i++;
} }
//以括号表示法输出二叉树
void DispBTNode(BiTNode *&b)
{
if (b != NULL)
{
cout<<b->data;
if (b->lchild != NULL || b->rchild != NULL)
{
cout<<"(";
DispBTNode(b->lchild);
if (b->rchild != NULL) cout<<(",");
DispBTNode(b->rchild);
cout<<")";
}
}
} #pragma region 递归遍历
//先序
void PreOrderTraverseR(BiTree T) {
if (T != NULL) {
cout << T->data;
PreOrderTraverseR(T->lchild);
PreOrderTraverseR(T->rchild);
}
}
//中序
void InOrderTraverseR(BiTree T) {
if (T != NULL) {
InOrderTraverseR(T->lchild);
cout << T->data;
InOrderTraverseR(T->rchild);
}
}
//后序
void PostOrderTraverseR(BiTree T) {
if (T != NULL) {
PostOrderTraverseR(T->lchild);
PostOrderTraverseR(T->rchild);
cout << T->data;
}
}
#pragma endregion #pragma region 非递归遍历
//先序遍历
void PreOrderTraverse(BiTree T) {
stack<BiTNode*> s;
BiTNode* p = T, * q = new BiTNode();
while (p != NULL || !s.empty()) {
if (p)//p非空
{
cout << p->data;
s.push(p);//根指针入栈
p = p->lchild;//遍历左子树
}
else {
p = s.top();
s.pop();
p = p->rchild;//遍历右子树
}
}
}
//中序遍历
void InOrderTraverse(BiTree T) {
stack<BiTNode*> s;
BiTNode* p = T, * q = new BiTNode();
while (p != NULL || !s.empty()) {
if (p)//p非空
{
s.push(p);//根指针入栈
p = p->lchild;//遍历左子树
}
else {
p = s.top();
s.pop();
cout << p->data;
p = p->rchild;//遍历右子树
}
}
}
//后序遍历
void PostOrderTraverse(BiTree T) {
BiTNode* p = T, * r = NULL;
stack<BiTNode*> s;
while (p != NULL || !s.empty()) {
if (p != NULL) {//走到最左边
s.push(p);
p = p->lchild;
}
else {
p = s.top();
if (p->rchild != NULL && p->rchild != r)//右子树存在,未被访问
p = p->rchild;
else {
s.pop();
cout << p->data;
r = p;//记录最近访问过的节点
p = NULL;//节点访问完后,重置p指针
}
}//else
}//while }
#pragma endregion
int main()
{
BiTree b;
Initial(b);
//创建树
CreateBiTree(b);
//先序遍历
cout << "先序遍历:";
PreOrderTraverse(b);
cout << endl;
//中序遍历
cout << "中序遍历:";
InOrderTraverse(b);
cout << endl;
//后序遍历
cout << "后序遍历:";
PostOrderTraverse(b);
}
程序示例:

C++学习---二叉树的输入及非递归遍历的更多相关文章
- 数据结构二叉树的递归与非递归遍历之java,javascript,php实现可编译(1)java
前一段时间,学习数据结构的各种算法,概念不难理解,只是被C++的指针给弄的犯糊涂,于是用java,web,javascript,分别去实现数据结构的各种算法. 二叉树的遍历,本分享只是以二叉树中的先序 ...
- C++编程练习(17)----“二叉树非递归遍历的实现“
二叉树的非递归遍历 最近看书上说道要掌握二叉树遍历的6种编写方式,之前只用递归方式编写过,这次就用非递归方式编写试一试. C++编程练习(8)----“二叉树的建立以及二叉树的三种遍历方式“(前序遍历 ...
- ZT 二叉树的非递归遍历
ZT 二叉树的非递归遍历 二叉树的非递归遍历 二叉树是一种非常重要的数据结构,很多其它数据结构都是基于二叉树的基础演变而来的.对于二叉树,有前序.中序以及后序三种遍历方法.因为树的定义本身就 是递归定 ...
- c语言描述的二叉树的基本操作(层序遍历,递归,非递归遍历)
#include<stdio.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define TRUE 1 #define ...
- 数据结构之二叉树篇卷三 -- 二叉树非递归遍历(With Java)
Nonrecursive Traversal of Binary Tree First I wanna talk about why we should <code>Stack</c ...
- [Alg] 二叉树的非递归遍历
1. 非递归遍历二叉树算法 (使用stack) 以非递归方式对二叉树进行遍历的算法需要借助一个栈来存放访问过得节点. (1) 前序遍历 从整棵树的根节点开始,对于任意节点V,访问节点V并将节点V入栈, ...
- 二叉树3种递归和非递归遍历(Java)
import java.util.Stack; //二叉树3种递归和非递归遍历(Java) public class Traverse { /******************一二进制树的定义*** ...
- c/c++二叉树的创建与遍历(非递归遍历左右中,破坏树结构)
二叉树的创建与遍历(非递归遍历左右中,破坏树结构) 创建 二叉树的递归3种遍历方式: 1,先中心,再左树,再右树 2,先左树,再中心,再右树 3,先左树,再右树,再中心 二叉树的非递归4种遍历方式: ...
- JAVA递归、非递归遍历二叉树(转)
原文链接: JAVA递归.非递归遍历二叉树 import java.util.Stack; import java.util.HashMap; public class BinTree { priva ...
随机推荐
- js实现隔行变色
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 我的Python自学之路-002 字典的知识
'''字典是python中唯一的验证类型,采用键值对(key-value)的形式存储数据.python对key进行哈希函数运算.根据计算的结果决定value的存储地址.所以字典是无序存储的.且key必 ...
- DVWA sql注入low级别
DVWA sql注入low级别 sql注入分类 数字型注入 SELECT first_name, last_name FROM users WHERE user_id = $id 字符型注入 SELE ...
- (专题一)06 MATLAB的算术运算
基本算术运算 乘法运算:A的行数等于B的列数(A,B两矩阵维数和大小相容) 除法运算 逻辑运算 真为1,假为0 优先级,算术运算的优先级最高,逻辑运算的优先级最低,但逻辑非运算是单目运算,他的优先级比 ...
- 最火的开源 IDE介绍与安装教程
导读:开发C/C++最好的IDE是什么,尤其对于很多初学者来说用什么IDE比较容易上手,本文将做以介绍,并为您演示如何下载与安装. 本文字数:1015,阅读时长大约:10分钟 (一)最火的开源IDE ...
- Spring 标签纸property
转载自https://www.cnblogs.com/zzb-yp/p/9968849.html Spring中XML文件配置Bean的简单示例,如下: <bean id="car&q ...
- Android作业 0923
计算器小应用 package com.example.myhomework2; import androidx.appcompat.app.AppCompatActivity; import andr ...
- ThinkPHP 5 生命周期
前段时间用TP5开发了一个小程序,就熟悉了一下TP5.TP5是TP框架最新的一个版本,与以前的3还是有很大的区别,有人说和laravel比较靠近,其实也还好,每个人都有自己不同的看法,只要是选择一个自 ...
- Java知识系统回顾整理01基础05控制流程03 while
while和do-while循环语句 一.while:条件为true时 重复执行 只要while中的表达式成立,就会不断地循环执行 public class HelloWorld { public s ...
- Numpy中的shape和reshape()
shape是查看数据有多少行多少列reshape()是数组array中的方法,作用是将数据重新组织 1.shape import numpy as np a = np.array([1,2,3,4,5 ...