ROC曲线和AUC值(转)
分类器性能指标之ROC曲线、AUC值
一 roc曲线
1、roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
2针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况.
(1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP)
(2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN)
(3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP)
(4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN)
TP:正确的肯定数目
FN:漏报,没有找到正确匹配的数目
FP:误报,没有的匹配不正确
TN:正确拒绝的非匹配数目
列联表如下,1代表正类,0代表负类:
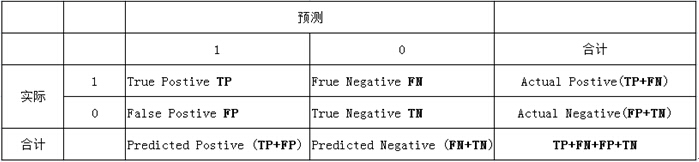
由上表可得出横,纵轴的计算公式:
(1)真正类率(True Postive Rate)TPR: TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。Sensitivity
(2)负正类率(False Postive Rate)FPR: FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例。1-Specificity
(3)真负类率(True Negative Rate)TNR: TN/(FP+TN),代表分类器预测的负类中实际负实例占所有负实例的比例,TNR=1-FPR。Specificity
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
如下面这幅图,(a)图中实线为ROC曲线,线上每个点对应一个阈值。
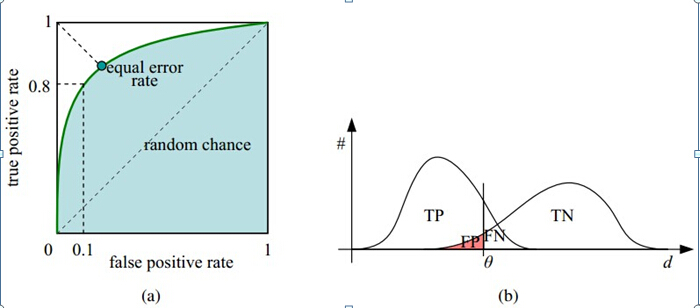
横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。
二 如何画roc曲线
假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。
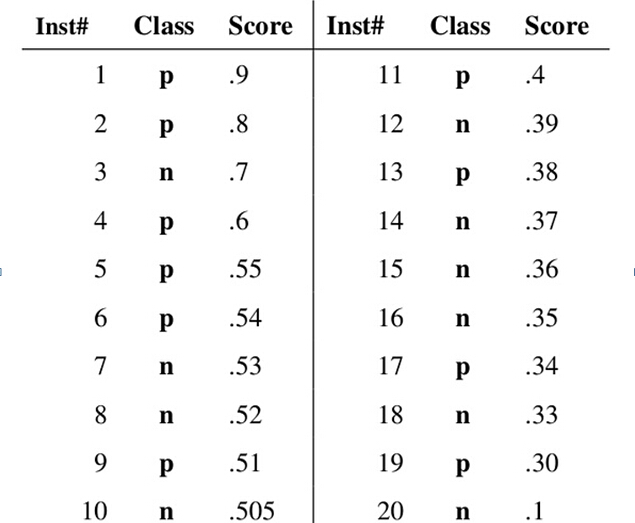
接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
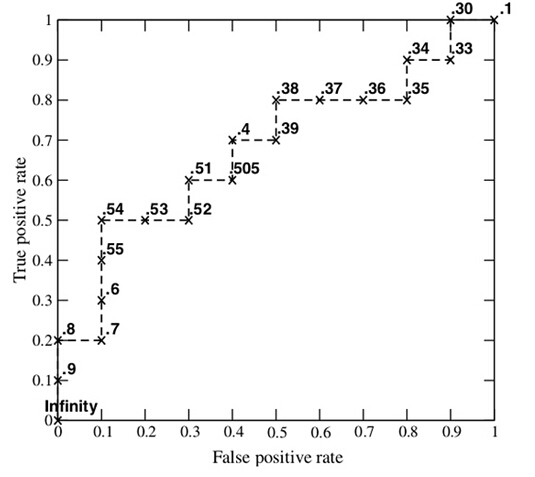
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间。Auc作为数值可以直观的评价分类器的好坏,值越大越好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值,AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
三 为什么使用Roc和Auc评价分类器
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比:
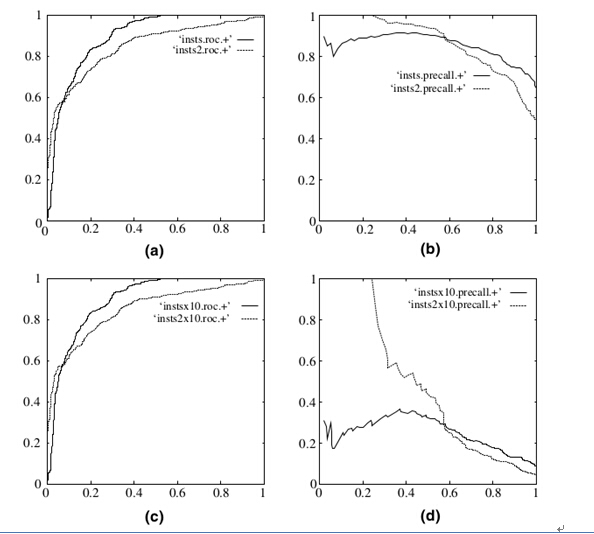
在上图中,(a)和(c)为Roc曲线,(b)和(d)为Precision-Recall曲线。
(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
参考:
ROC曲线和AUC值(转)的更多相关文章
- 机器学习之分类器性能指标之ROC曲线、AUC值
分类器性能指标之ROC曲线.AUC值 一 roc曲线 1.roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性 ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- 模型监控指标- 混淆矩阵、ROC曲线,AUC值,KS曲线以及KS值、PSI值,Lift图,Gain图,KT值,迁移矩阵
1. 混淆矩阵 确定截断点后,评价学习器性能 假设训练之初以及预测后,一个样本是正例还是反例是已经确定的,这个时候,样本应该有两个类别值,一个是真实的0/1,一个是预测的0/1 TP(实际为正预测为正 ...
- ROC曲线与AUC值
本文根据以下文章整理而成,链接: (1)http://blog.csdn.net/ice110956/article/details/20288239 (2)http://blog.csdn.net/ ...
- ROC曲线和AUC值
链接:https://www.zhihu.com/question/39840928/answer/146205830来源:知乎 一.混淆矩阵 混淆矩阵如图1分别用”0“和”1“代表负样本和正样本.F ...
- Mean Average Precision(mAP),Precision,Recall,Accuracy,F1_score,PR曲线、ROC曲线,AUC值,决定系数R^2 的含义与计算
背景 之前在研究Object Detection的时候,只是知道Precision这个指标,但是mAP(mean Average Precision)具体是如何计算的,暂时还不知道.最近做OD的任 ...
- 【转】roc曲线与auc值
https://www.cnblogs.com/gatherstars/p/6084696.html ROC的全名叫做Receiver Operating Characteristic,其主要分析工具 ...
- 使用Python画ROC曲线以及AUC值
from:http://kubicode.me/2016/09/19/Machine%20Learning/AUC-Calculation-by-Python/ AUC介绍 AUC(Area Unde ...
- ROC曲线,AUC面积
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间.Auc作为数值可以直观的评价分类器的好坏,值越大越好. 首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本, ...
随机推荐
- [数据结构与算法] : AVL树
头文件 typedef int ElementType; #ifndef _AVLTREE_H_ #define _AVLTREE_H_ struct AvlNode; typedef struct ...
- 关于 android 读取当前手机号码
手机号码不是所有的都能获取.只是有一部分可以拿到.这个是由于移动运营商没有把手机号码的数据写入到sim卡中.SIM卡只有唯一的编号,供网络与设备识别那就是IMSI号码,手机的信号也可以说是通过这个号码 ...
- 论战大数据----胖子哥的PK之旅(一)
胖子哥(1106110976) 9:35:36 http://www.cnblogs.com/hadoopdev/p/3531963.htmlnosqlt数据库-肖(380594863) 9:38:0 ...
- C/C++基础----泛型算法
算法不依赖与容器(使用迭代器),但大多数依赖于元素类型.如find需要==运算符,其他算法可能要求支持<运算符. 算法永远不会执行容器的操作,永远不会改变底层容器的大小(添加或删除元素). ac ...
- bzoj1941 Hide and Seek
Description 小猪iPig在PKU刚上完了无聊的猪性代数课,天资聪慧的iPig被这门对他来说无比简单的课弄得非常寂寞,为了消除寂寞感,他决定和他的好朋友giPi(鸡皮)玩一个更加寂寞的游戏- ...
- appium 中文API 集
参考:https://testerhome.com/topics/3711 根据appium 1.4.13.1版本整理,1.5弃用了find by name 所以更新了下如有错误请多多指正谢谢@lyl ...
- Logstash之四:logstash接收kafka数据
3.kafka+logstash整合logstash1.5以后已经集成了对kafka的支持扩展,可以在conf配置中直接使用 vim /etc/logstash/conf.d/pay.conf inp ...
- 浅谈在Java开发中的枚举的作用和用法
枚举(enum),是指一个经过排序的.被打包成一个单一实体的项列表.一个枚举的实例可以使用枚举项列表中任意单一项的值.枚举在各个语言当中都有着广泛的应用,通常用来表示诸如颜色.方式.类别.状态等等数目 ...
- python中for...if...构建List
1.简单的for...[if]...语句 >>> a=[12, 3, 4, 6, 7, 13, 21] >>> newList = [x for x in a] & ...
- 基于Linux的Samba开源共享解决方案测试(四)
对于客户端的网络监控如图: 双NAS网关100Mb码率视音频文件的稳定读测试结果如下: 100Mb/s负载性能记录 NAS网关资源占用 稳定写 稳定写 CPU空闲 内存空闲 网卡占用 NAS1 8个稳 ...