[C8] 聚类(Clustering)
聚类(Clustering)
非监督学习:简介(Unsupervised Learning: Introduction)
本章节介绍聚类算法,这是我们学习的第一个非监督学习算法——学习无标签数据,而不是此前的有标签数据。
什么是非监督学习?与监督学习对比
监督学习,有标签的训练集,目标是找到区分正负样本的决策边界,需要据此拟合一个假设函数。

非监督学习,数据无任何标签。也就是,将一系列无标签训练数据,输入算法,然后算法自动为我们寻找出这些数据内在的结构。下图的数据看起来可以分成两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
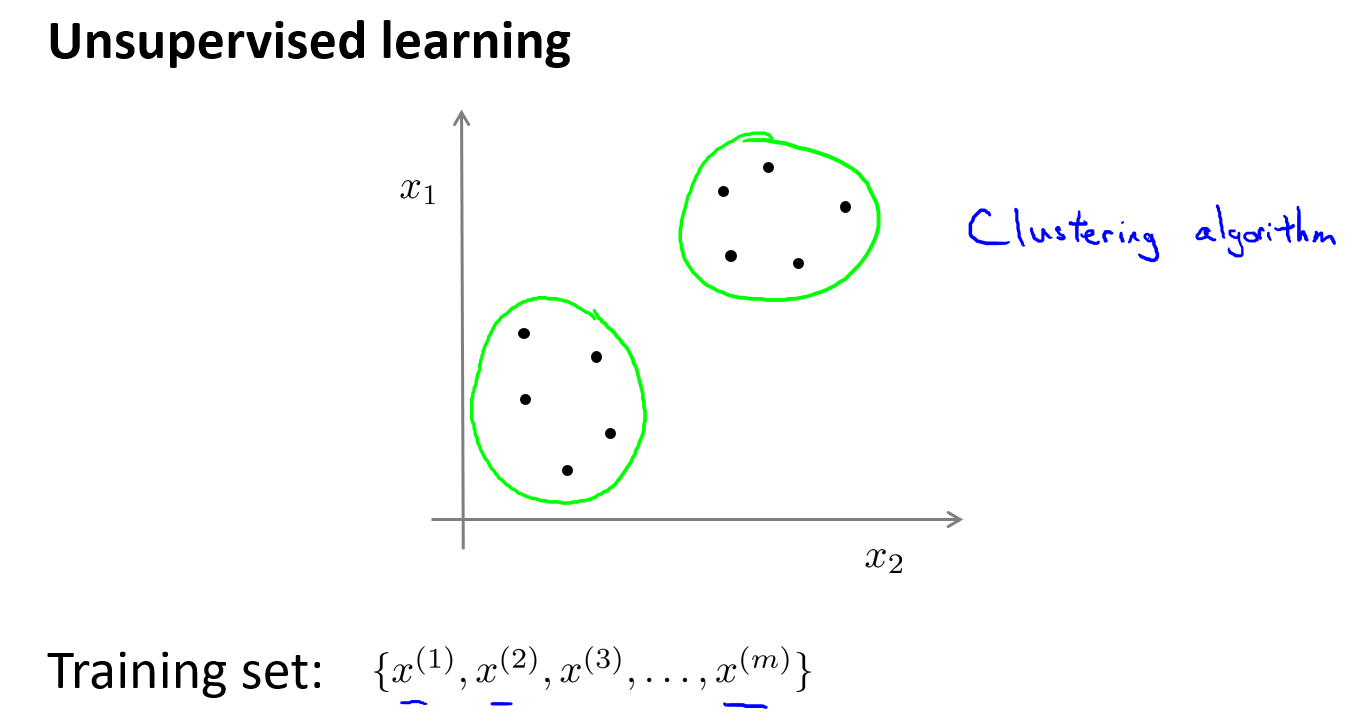
聚类算法一般用来做什么?
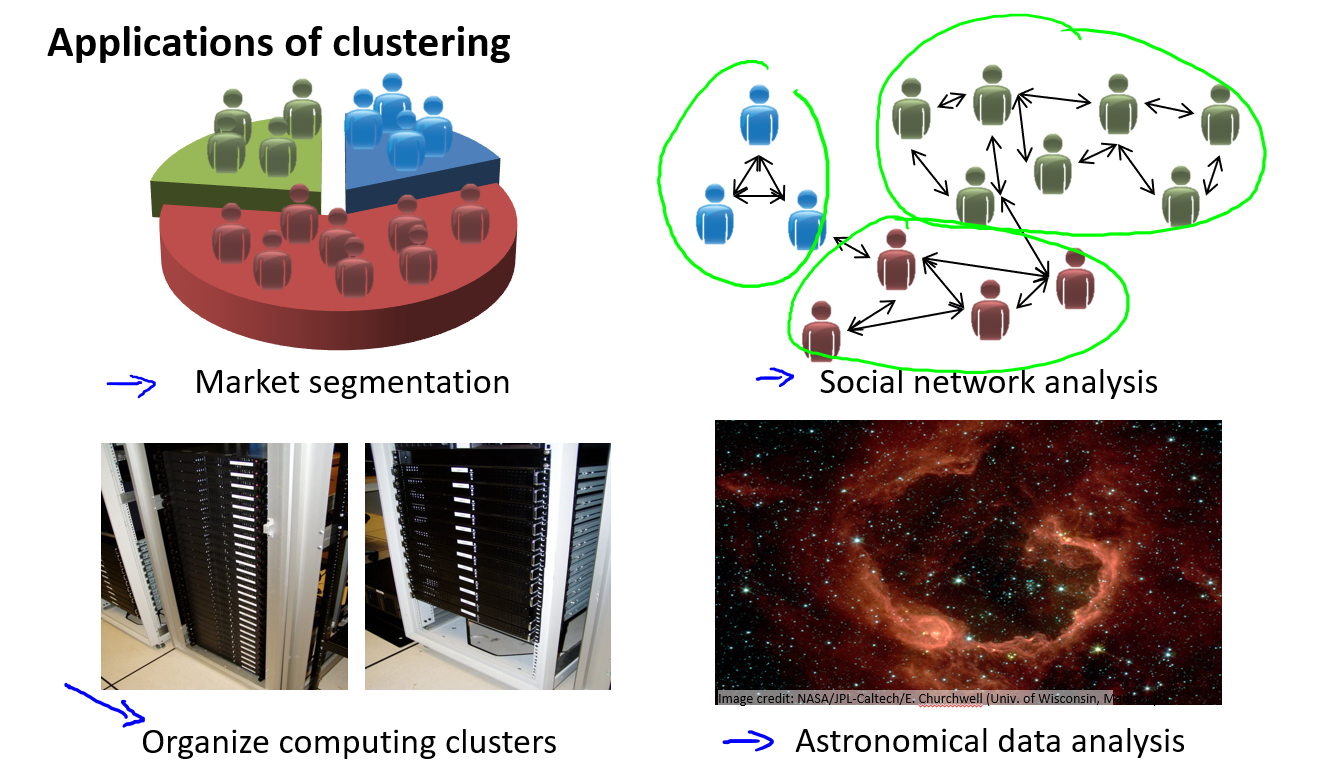
- 市场分割:也许你的数据库存储了许多客户信息,你希望将他们分成不同的客户群,这样你可以对不同类型的客户分别销售产品,或者分别提供更适合的服务。
- 社交网络分析:事实上有许多研究人员正在研究这样一些内容,他们关注一群人,关注社交网络,例如Facebook,Google+,或者是其他的一些信息,比如说:你经常跟哪些人联系,而这些人又经常给哪些人发邮件,由此找到关系密切的人群。
- 使用聚类算法来更好的组织计算机集群,或更好的管理数据中心。如果知道数据中心中,那些计算机经常协作工作。你就可以重新分配资源,重新布局网络。由此优化数据中心,优化数据通信。
- 最后,我实际上还在研究如何利用聚类算法了解星系的形成。然后用这个知识,了解一些天文学上的细节问题。
K-均值算法(K-Means Algorithm)
聚类问题中,给出了一个未标记的数据集,希望有一个算法能自动将数据分组成一些相关的子集或簇。
K Means 是迄今为止最流行、使用最广泛的聚类算法,下面说明一下 K-Means 算法是什么以及它是如何工作的。
假设我有一个未标记的数据集,如下图:
现在,我想将数据分为两个聚类,如果运行K-Means算法,第一步是随机初始化两个点,称为聚类质心或簇质心(Cluster Centroids),即:下图中的两个x。K-Means是一种迭代算法,在每次迭代中,它会做两件事:
- 将样本分配给离它最近的质心
- 移动质心到属于该质心的所有样本的平均值处
然后再次重复迭代,直至收敛。
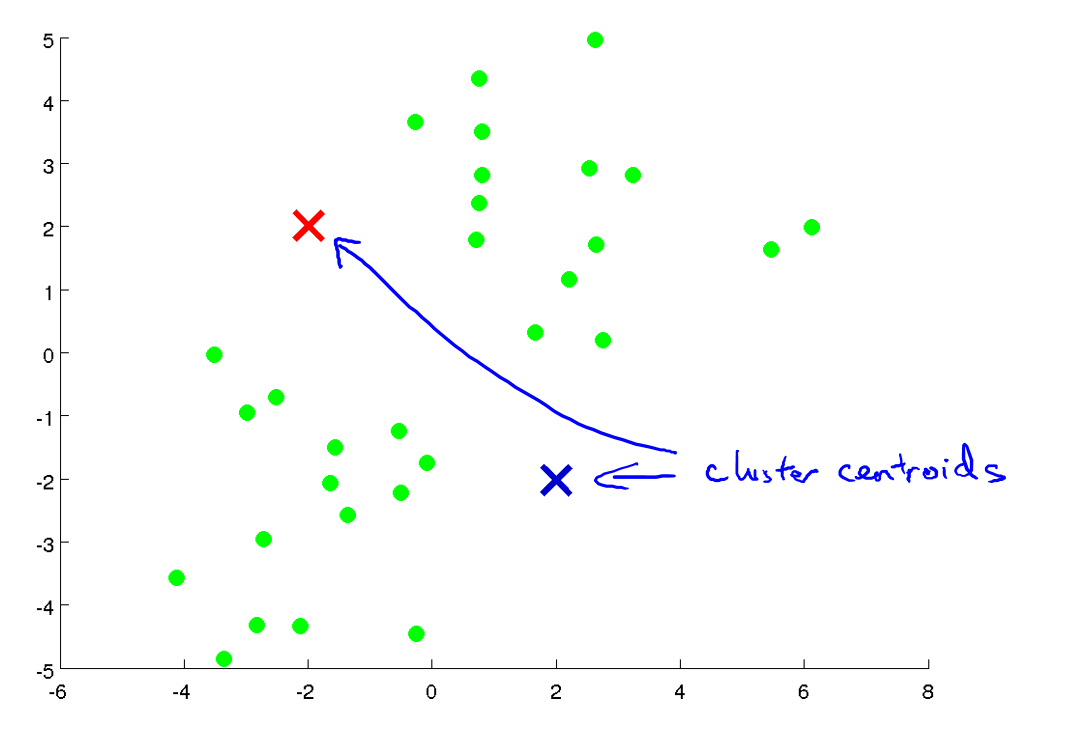
将样本分配给离它最近的质心 这意味着,它通过分别计算并比较每个样本(上图中显示的每个绿点)和两个聚类中心点(红色X和蓝色X)的距离,如果它距离红X近,就将它分配给红X,反之,将其分配给蓝X。如下图,这就是聚类中心点的分配步骤:

移动质心到属于该质心的所有样本的平均值处 这意味着,我们将采用两个聚类中心点,即红X和蓝X,然后将它们移动到相同颜色的点的平均值处。所以我们要做的是查看所有红点并计算平均值,实际上是所有红点位置的平均值,然后我们将红色质心移动到该平均值处。对于蓝色质心也是如此操作,即查看所有蓝点并计算它们的平均值,然后移动蓝色质心到那个平均值处。现在让我们来移动一步,如下如:
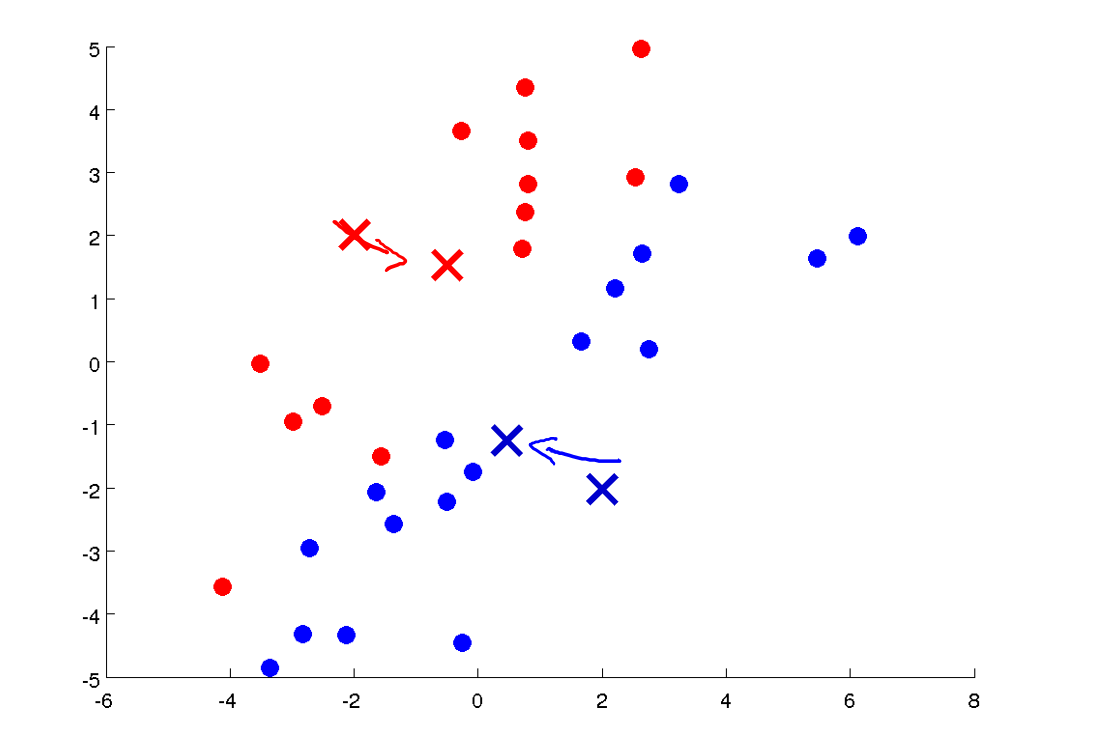
我现在把它们移动到了新的位置。红色的那个像那样移动,蓝色的那个像那样移动。然后再次重新迭代运行这两个步骤:
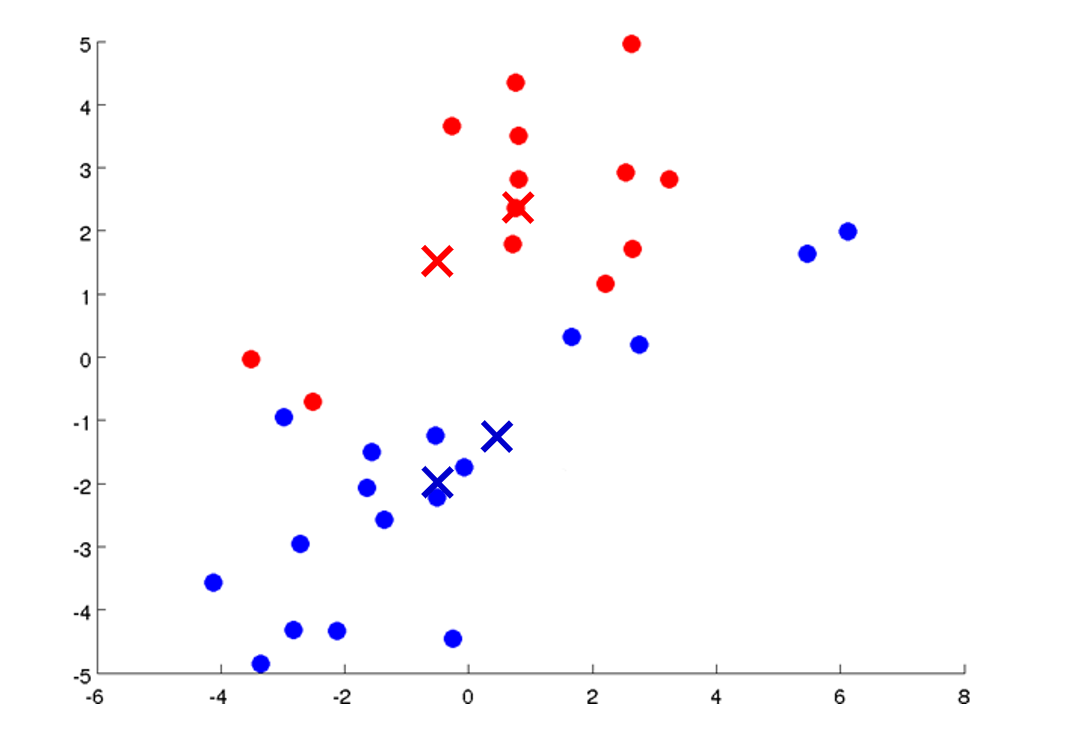
一些点的颜色刚刚改变了,因为被重新分配到了不同的质心,我们继续移动:
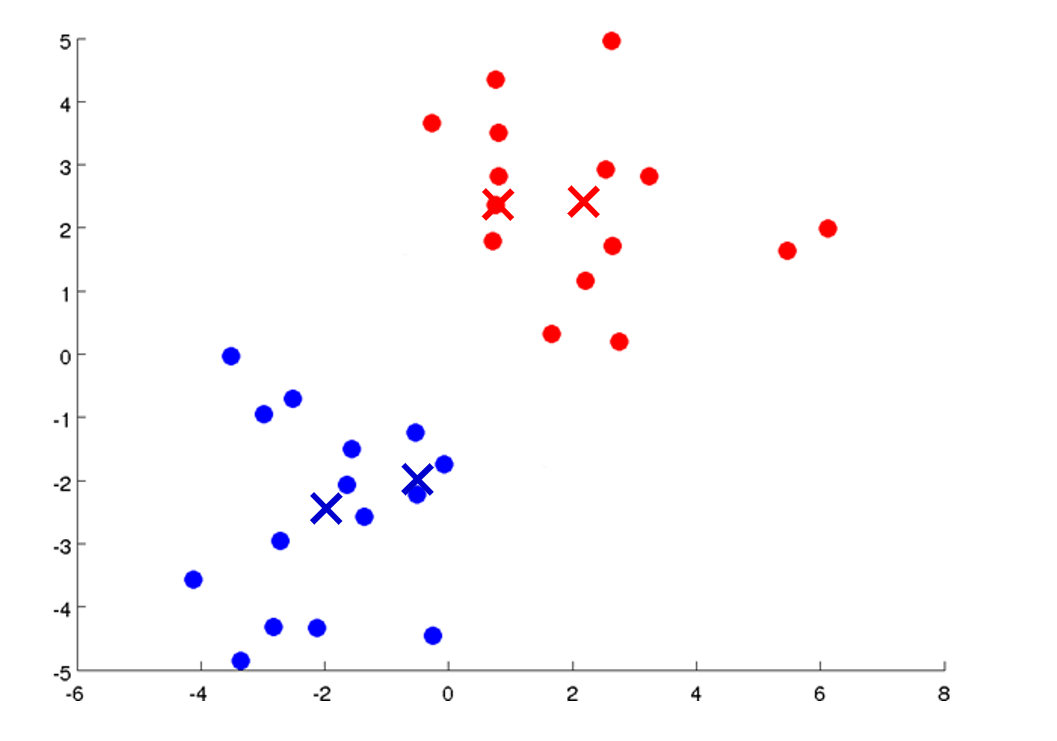
如果这些点的颜色不再变化,意味着K-Means已经收敛,我们得到最终的质心位置,以及属于该质心的样本,可以看到,K-Means算法已经很好的在数据集中找到了两个聚类:
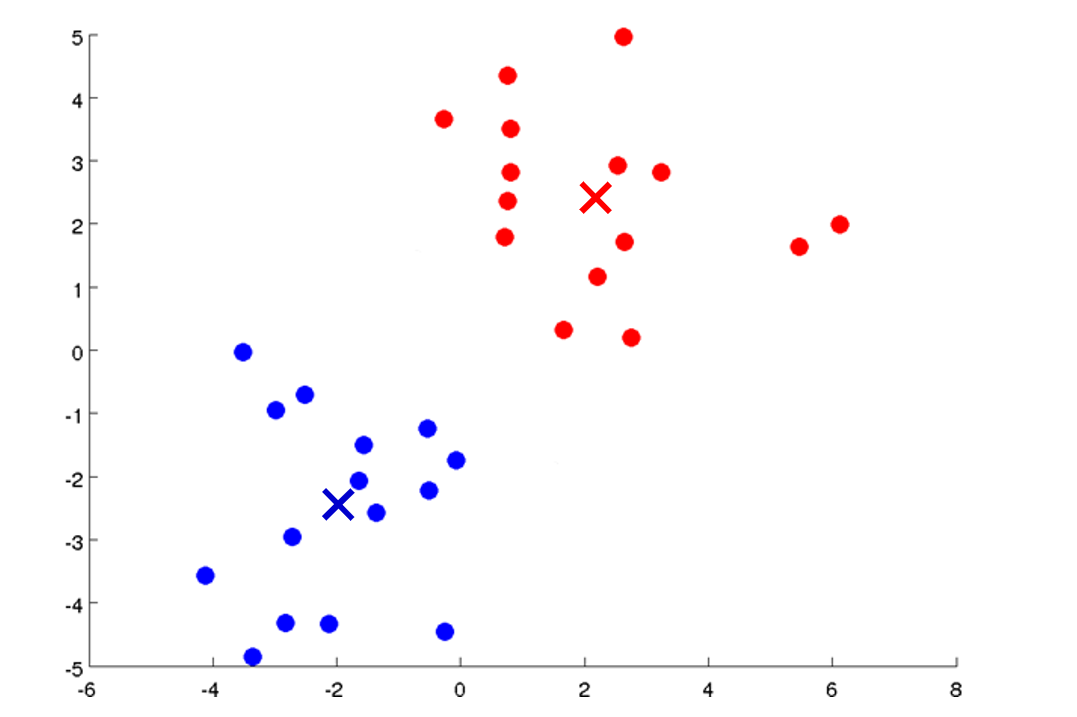
让我们更正式地写出K均值算法,如下:

K-Means算法需要两个输入。一个是参数K,它是你要在数据中找到的聚类数。稍后会讲如何来选择这个参数K的值,但现在假设我们已经确定了我们需要的聚类的数量,我们将告诉算法我们认为有多少聚类在数据集中。然后K-Means也会将这种只有X的训练集作为输入,因为这是无监督学习,不再有标签Y。 对于K-Means无监督学习,按照惯例,\(x^{(i)}\) 为属于 \(\mathbb{R}\) 的n维向量,即 \(x^{(i)} \in \mathbb{R}^n\),此处无需偏置项 \(x_0=1\)。
然后,下图就是K均值算法所做的:

第一步是它随机初始化 k 个簇质心,我们称之为 \(\mu_1\),\(\mu_2\),直到 \(\mu_K\)。因此在前面的图中,簇质心对应于红X和蓝X的位置,那时我们有两个簇质心,也许红X是 \(\mu_1\) 而蓝X是 \(\mu_2\),更一般地说我们会有 K 个聚类质心而不是只有两个。
然后 Repeat 循环意味着我们我会反复做以下事情:
簇分配的步骤 :对于每个训练样本,把变量 \(c^{(i)}\) 设置为簇质心从1到K中最接近 \(x^{(i)}\) 的那个质心的索引。可表示为 \(c^{(i)} = \underset{k}{min} ||x^{(i)} - \mu_k||^2\), 大写的 K 为簇的总数,小写的 k 为 1 ~ K之间的数,表示不同簇质心的索引,这就是簇分配的步骤。
质心移动的步骤 :对于每个簇质心(小写 k 等于 1 到 K),将 \(\mu_k\) 设置为等于分配给该簇质心的所有点的平均值。\(\mu_k\) 为 K * n 维向量,K 是 K 个簇,n 是每个样本都是 n 维向量。
如果存在一个簇质心,没有被分配点。在这种情况下,更常见的事情是移除该簇质心。如果你这样做,你最终得到K-1个簇而不是K个。有时如果你确实需要K个簇,那么你可以重新随机重新初始化那个簇质心,但是移除簇是更常见的。
优化目标(Optimization Objective)
\(c^{(i)}\) = index of cluster(1,2,...,K) to which example \(x^{(i)}\) is currently assigned.
\(\mu_k\) = cluster centroid $ k (\mu_k \in \mathbb{R}^n$)
\(\mu_{c^{(i)}}\) = cluster centroid of cluster to which example \(x^{(i)}\) has been assigned.
K-Means cost function(又称 畸变函数 Distortion function):
\(J(c^{(1)},...,c^{(m)},μ_1,...,μ_K)=\dfrac {1}{m}\sum\limits^{m}_{i=1}\left\| x^{\left( i\right) }-\mu_{c^{(i)}}\right\| ^{2}\)
K-Meand optimization objective:
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,其中\({{\mu }_{{{c}^{(i)}}}}\)代表与\({{x}^{(i)}}\)最近的聚类中心点。我们的优化目标便是找出使得代价函数最小的 \(c^{(1)},...,c^{(m)}\) 和 \(μ^1,...,μ^k\):
$\underset{\mu_1,...,\mu_K}{\underset{c^{(1)},...,c^{(m)}}{min}} J(c^{(1)},...,c^{(m)},μ_1,...,μ_K) $
K-Means 算法在每次迭代(每次迭代都在减小代价函数)过程中:
- 第一个for循环是用来减小 \(c^{(i)}\) 引起的代价
- 第二个for循环则是用来减小 \({{\mu }_{i}}\) 引起的代价。
随机初始化(Random Initialization)
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
我们应该选择\(K<m\),即聚类中心点的个数要小于所有训练集实例的数量
随机选择\(K\)个训练实例,然后令\(K\)个聚类中心分别与这\(K\)个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
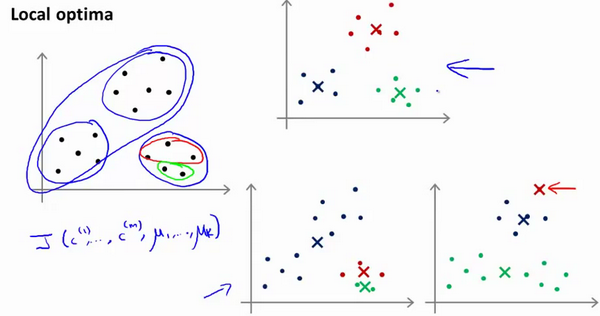
为了解决这个问题,我们通常需要多次运行K-Means算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在\(K\)较小的时候(2~10)还是可行的,但是如果\(K\)较大,这么做也可能不会有明显地改善。
选择聚类数(Choosing the Number of Clusters)
人们在讨论选择聚类数目的方法时,有一个可能会被谈及的方法叫作“肘部法则”。关于“肘部法则”,我们要做的是改变 \(K\) 值,并计算对应的 \(J\),然后画出它们的曲线。
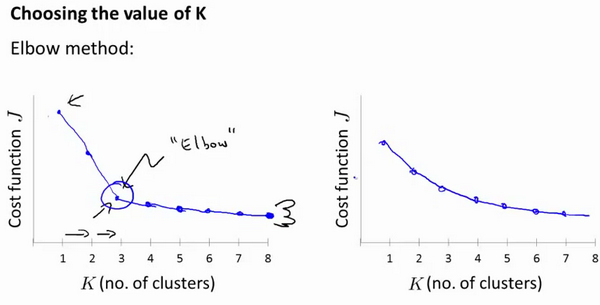
我们可能会得到一条类似于上图左侧的曲线,看起来就好像人的手臂,而且有一个清楚的肘在那儿。这就是“肘部法则”。你会发现它的畸变值会迅速下降,直到 “肘部(K=3)”时,开始变得平缓。所以看起来使用3个簇来进行聚类是合理的。但是在大多数情况下,你可能会得到上面右边的曲线,从头到尾到很平滑,根本不知道肘部在哪里。
所以,其实没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题,人工进行选择。
选择的时候思考我们运用 K-Means 的动机是什么,然后选择能最好服务于该目标的聚类数。
例如,我们 T-恤 制造的例子,我们要将用户按照身材聚类,我们可以分成3个尺寸:\(S,M,L\),也可以分成5个尺寸 \(XS,S,M,L,XL\),这样的选择是在建立在回答了 “聚类后我们制造的 T-恤 能否较好地适合我们的客户” 这个问题基础之上的。
聚类参考资料(可选的)
相似度/距离计算方法总结
(1). 闵可夫斯基距离Minkowski/(其中欧式距离:\(p=2\))
\(dist(X,Y)={{\left( {{\sum\limits_{i=1}^{n}{\left| {{x}_{i}}-{{y}_{i}} \right|}}^{p}} \right)}^{\frac{1}{p}}}\)
(2). 杰卡德相似系数(Jaccard):
\(J(A,B)=\frac{\left| A\cap B \right|}{\left|A\cup B \right|}\)
(3). 余弦相似度(cosine similarity):
\(n\)维向量\(x\)和\(y\)的夹角记做\(\theta\),根据余弦定理,其余弦值为:
\(cos (\theta )=\frac{{{x}^{T}}y}{\left|x \right|\cdot \left| y \right|}=\frac{\sum\limits_{i=1}^{n}{{{x}_{i}}{{y}_{i}}}}{\sqrt{\sum\limits_{i=1}^{n}{{{x}_{i}}^{2}}}\sqrt{\sum\limits_{i=1}^{n}{{{y}_{i}}^{2}}}}\)
(4). Pearson皮尔逊相关系数:
\({{\rho }_{XY}}=\frac{\operatorname{cov}(X,Y)}{{{\sigma }_{X}}{{\sigma }_{Y}}}=\frac{E[(X-{{\mu }_{X}})(Y-{{\mu }_{Y}})]}{{{\sigma }_{X}}{{\sigma }_{Y}}}=\frac{\sum\limits_{i=1}^{n}{(x-{{\mu }_{X}})(y-{{\mu }_{Y}})}}{\sqrt{\sum\limits_{i=1}^{n}{{{(x-{{\mu }_{X}})}^{2}}}}\sqrt{\sum\limits_{i=1}^{n}{{{(y-{{\mu }_{Y}})}^{2}}}}}\)
Pearson相关系数即将\(x\)、\(y\)坐标向量各自平移到原点后的夹角余弦。
聚类的衡量指标
(1). 均一性:\(p\)
类似于精确率,一个簇中只包含一个类别的样本,则满足均一性。其实也可以认为就是正确率(每个 聚簇中正确分类的样本数占该聚簇总样本数的比例和)
(2). 完整性:\(r\)
类似于召回率,同类别样本被归类到相同簇中,则满足完整性;每个聚簇中正确分类的样本数占该
类型的总样本数比例的和
(3). V-measure:
均一性和完整性的加权平均
\(V = \frac{(1+\beta^2)*pr}{\beta^2*p+r}\)
(4). 轮廓系数
样本\(i\)的轮廓系数:\(s(i)\)
簇内不相似度:计算样本\(i\)到同簇其它样本的平均距离为\(a(i)\),应尽可能小。
簇间不相似度:计算样本\(i\)到其它簇\(C_j\)的所有样本的平均距离\(b_{ij}\),应尽可能大。
轮廓系数:\(s(i)\)值越接近1表示样本\(i\)聚类越合理,越接近-1,表示样本\(i\)应该分类到 另外的簇中,近似为0,表示样本\(i\)应该在边界上;所有样本的\(s(i)\)的均值被成为聚类结果的轮廓系数。
\(s(i) = \frac{b(i)-a(i)}{max\{a(i),b(i)\}}\)
(5). ARI
数据集\(S\)共有\(N\)个元素, 两个聚类结果分别是:
\(X=\{{{X}_{1}},{{X}_{2}},...,{{X}_{r}}\},Y=\{{{Y}_{1}},{{Y}_{2}},...,{{Y}_{s}}\}\)
\(X\)和\(Y\)的元素个数为:
\(a=\{{{a}_{1}},{{a}_{2}},...,{{a}_{r}}\},b=\{{{b}_{1}},{{b}_{2}},...,{{b}_{s}}\}\)
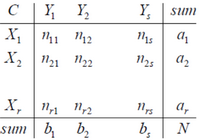
记:\({{n}_{ij}}=\left| {{X}_{i}}\cap {{Y}_{i}} \right|\)
\(ARI=\frac{\sum\limits_{i,j}{C_{{{n}_{ij}}}^{2}}-\left[ \left( \sum\limits_{i}{C_{{{a}_{i}}}^{2}} \right)\cdot \left( \sum\limits_{i}{C_{{{b}_{i}}}^{2}} \right) \right]/C_{n}^{2}}{\frac{1}{2}\left[ \left( \sum\limits_{i}{C_{{{a}_{i}}}^{2}} \right)+\left( \sum\limits_{i}{C_{{{b}_{i}}}^{2}} \right) \right]-\left[ \left( \sum\limits_{i}{C_{{{a}_{i}}}^{2}} \right)\cdot \left( \sum\limits_{i}{C_{{{b}_{i}}}^{2}} \right) \right]/C_{n}^{2}}\)
程序代码
直接查看K-Means Clustering.ipynb可点击
获取源码以其他文件,可点击右上角 Fork me on GitHub 自行 Clone。
[C8] 聚类(Clustering)的更多相关文章
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- sklearn:聚类clustering
http://blog.csdn.net/pipisorry/article/details/53185758 不同聚类效果比较 sklearn不同聚类示例比较 A comparison of the ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
第十三章.聚类--Clustering ******************************************************************************** ...
- 机器学习(九)-------- 聚类(Clustering) K-均值算法 K-Means
无监督学习 没有标签 聚类(Clustering) 图上的数据看起来可以分成两个分开的点集(称为簇),这就是为聚类算法. 此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者 ...
- 机器学习-聚类(clustering)算法:K-means算法
1. 归类: 聚类(clustering):属于非监督学习(unsupervised learning) 无类别标记(class label) 2. 举例: 3. Kmeans算法 3.1 clust ...
- 聚类clustering
聚类:把相似的东西分到一组,是无监督学习. 聚类算法的分类: (1)基于划分聚类算法(partition clustering):建立数据的不同分割,然后用相同标准评价聚类结果.(比如最小化平方误差和 ...
- 海量数据挖掘MMDS week5: 聚类clustering
http://blog.csdn.net/pipisorry/article/details/49427989 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- [综]聚类Clustering
Annie19921223的博客 [转载]用MATLAB做聚类分析 http://blog.sina.com.cn/s/blog_9f8cf10d0101f60p.html Free Mind 漫谈 ...
随机推荐
- 使用docker-compose安装wordpress
一.建立应用的目录 mkdir my_wordpress cd my_wordpress 二.创建 docker-compose.yml touch docker-compose.yml;vi doc ...
- mysql五大引擎的区别和优劣之分
数据库引擎介绍 MySQL数据库引擎取决于MySQL在安装的时候是如何被编译的.要添加一个新的引擎,就必须重新编译MYSQL.在缺省情况下,MYSQL支持三个引擎:ISAM.MYISAM和HEAP.另 ...
- 201871010112-梁丽珍《面向对象程序设计(java)》第十六周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- WPF 动态列(DataGridTemplateColumn) 绑定数据 (自定义控件)对象绑定
原文:WPF 动态列(DataGridTemplateColumn) 绑定数据 (自定义控件)对象绑定 WPF 动态列(DataGridTemplateColumn) 绑定数据 (自定义控件) 上面的 ...
- linux 判断文件夹或文件是否存在
文件夹不存在则创建 if [ ! -d "/data/" ];then mkdir /data else echo "文件夹已经存在" fi 文件存在则删除 i ...
- 实现迭代器(__next__和__iter__)
目录 一.简单示例 二.StopIteration异常版 三.模拟range 四.斐波那契数列 一.简单示例 死循环 class Foo: def __init__(self, x): self.x ...
- Python程序中的进程操作-开启多进程(multiprocess.process)
目录 一.multiprocess模块 二.multiprocess.process模块 三.process模块介绍 3.1 方法介绍 3.2 属性介绍 3.3 在windows中使用process模 ...
- umi+dva+antd新建项目(亲测可用)
首先全局安装dva+umiumi:npm install -g umidva:npm install -g dva-cli 通过脚手架创建项目 一: mkdir myapp && cd ...
- IT兄弟连 Java语法教程 数组 多维数组 二维数组的声明
Java语言里提供了支持多维数组的语法.但是这里还想说,从数组底层的运行机制上来看是没有多维数组的. Java语言里的数组类型是引用类型,因此数组变量其实是一个引用,这个引用指向真实的数组内存,数组元 ...
- [03]使用 VS2019 创建 ASP.NET Core Web 程序
使用 VS2019 创建 ASP.NET Core Web 程序 本文作者:梁桐铭- 微软最有价值专家(Microsoft MVP) 文章会随着版本进行更新,关注我获取最新版本 本文出自<从零开 ...