Python爬虫(一):爬虫伪装
1 简介
对于一些有一定规模或盈利性质比较强的网站,几乎都会做一些防爬措施,防爬措施一般来说有两种:一种是做身份验证,直接把虫子挡在了门口,另一种是在网站设置各种反爬机制,让虫子知难而返。
2 伪装策略
我们知道即使是一些规模很小的网站通常也会对来访者的身份做一下检查,如验证请求 Headers,而对于那些上了一定规模的网站就更不用说了。因此,为了让我们的爬虫能够成功爬取所需数据信息,我们需要让爬虫进行伪装,简单来说就是让爬虫的行为变得像普通用户访问一样。
2.1 Request Headers问题
为了演示我使用百度搜索 163邮箱

使用 F12 工具看一下请求信息
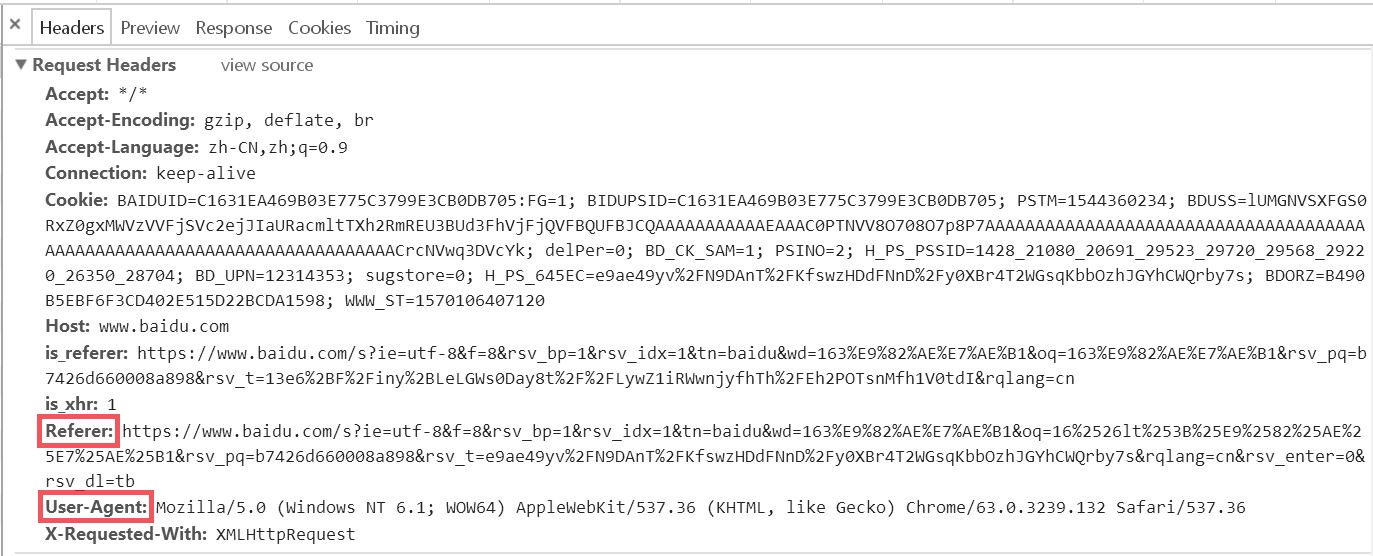
在上图中,我们可以看到 Request Headers 中包含 Referer 和 User-Agent 两个属性信息,Referer 的作用是告诉服务器该网页是从哪个页面链接过来的,User-Agent 中文是用户代理,它是一个特殊字符串头,作用是让服务器能够识别用户使用的操作系统、CPU 类型、浏览器等信息。通常的处理策略是:1)对于要检查 Referer 的网站就加上;2)对于每个 request 都添加 User-Agent。
2.2 IP限制问题
有时我们可能会对一些网站进行长期或大规模的爬取,而我们在爬取时基本不会变换 IP,有的网站可能会监控一个 IP 的访问频率和次数,一但超过这个阈值,就可能认作是爬虫,从而对其进行了屏蔽,对于这种情况,我们要采取间歇性访问的策略。
通常我们爬取是不会变换 IP 的,但有时可能会有一些特殊情况,要长时间不间断对某网站进行爬取,这时我们就可能需要采用 IP 代理的方式,但这种方式一般会增加我们开销,也就是可能要多花钱。
3 总结
有些时候我们进行爬取时 Request Headers 什么的已经做好了伪装,却并未得到如愿以偿的结果,可能会出现如下几种情况:得到的信息不完整、得到不相关的信息、得不到信息,这种情况我们就需要研究网站的防爬机制,对其进行详细分析了。常见的几种我列一下:
1)不规则信息:网址上会有一些没有规则的一长串信息,这种情况通常采用 selenium(模拟浏览器,效率会低一些) 解决;
2)动态校验码:比如根据时间及一些其他自定义规则生成,这种情况我们就需要找到其规则进行破解了;
3)动态交互:需要与页面进行交互才能通过验证,可以采用 selenium 解决;
4)分批次异步加载:这种情况获取的信息可能不完整,可以采用 selenium 解决。
Python爬虫(一):爬虫伪装的更多相关文章
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python基础及爬虫入门
**写在前面**我们在学习任何一门技术的时候,往往都会看很多技术博客,很多程序员也会写自己的技术博客.但是我想写的这些不是纯技术博客,我暂时也没有这个能力写出 Python 或者爬虫相关的技术博客来. ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
随机推荐
- JavaScript 数据结构与算法之美 - 冒泡排序、插入排序、选择排序
1. 前言 算法为王. 想学好前端,先练好内功,只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算 ...
- HTML 画布(摘自菜鸟教程)
颜色.样式和阴影 属性 描述 fillStyle 设置或返回用于填充绘画的颜色.渐变或模式. strokeStyle 设置或返回用于笔触的颜色.渐变或模式. shadowColor 设置或返回用于阴影 ...
- 《阿里巴巴Java开发手册1.4.0》阅读总结与心得(三)
(六)工程结构 (一)应用分层 1. [推荐]图中默认上层依赖于下层,箭头关系表示可直接依赖,如:开放接口层可以依赖于Web 层,也可以直接依赖于 Service 层,依此类推: 开放接口层: ...
- 使用Docker快速部署ELK分析Nginx日志实践(二)
Kibana汉化使用中文界面实践 一.背景 笔者在上一篇文章使用Docker快速部署ELK分析Nginx日志实践当中有提到如何快速搭建ELK分析Nginx日志,但是这只是第一步,后面还有很多仪表盘需要 ...
- Oralce 触发器
今天做了一个需要用到触发器实现的功能中间去到了各种问题,还好最后都解决了: 整个过程中真是遇到了不少错误: ORA-04091: 表 KPGO.T_ISSUER 发生了变化, 触发器/函数不能读它 O ...
- CF982C Cut 'em all! DFS 树 * 二十一
Cut 'em all! time limit per test 1 second memory limit per test 256 megabytes input standard input ...
- springboot的最简创建方式
springboot是目前比较流行的技术栈之一,我在这里写一个springboot工程最简方式 首先开发工具是IDEA,双击打开IDEA,点击Create new Project 进入到这个页面,选择 ...
- spring组件注册
基于注解和类的组件注册 @Conditional 作用:按照一定的条件进行判断,如果满足条件的话就给spring容器中注册bean 该注解既可以标注到方法上面,也可以标注到类上面(只有满足条件时, ...
- C#中读写Xml配置文件常用方法工具类
场景 有时需要使用配置文件保存一些配置的属性,使其在下次打开时设置仍然生效. 这里以对xml配置文件的读写为例. 1.读取XML配置文. 2.写入XML配置文件. 3.匹配 XPath 表达式的第一个 ...
- HBase常用操作之namespace
1.介绍 在HBase中,namespace命名空间指对一组表的逻辑分组,类似RDBMS中的database,方便对表在业务上划分.Apache HBase从0.98.0, 0.95.2两个版本开始支 ...