[spark程序]统计人口平均年龄(本地文件)(详细过程)
一、题目描述
(1)编写Spark应用程序,该程序可以在本地文件系统中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89
2 67
3 69
4 78
(2)编写Spark应用程序,对本地文件系统中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、生成数据文件peopleage.txt
1)创建程序的目录结构
创建一个存放代码的目录,进入目录下创建一个目录用来保存该题目所有文件(/swy/resource/spark/peopleage)
在peopleage目录下建立src/main/scala代码目录,专门用来保存scala代码文件,命令如下:

2)生成数据文件peopleage.txt的代码
创建一个代码文件GeneratePeopleAge.scala,用来生成数据文件peopleage.txt,命令如下:


代码如下:
import java.io.FileWriter
import java.io.File
import scala.util.Random object GeneratePeopleAge{ def main(args:Array[String]){
val fileWriter = new FileWriter(new File("/swy/resource/spark/peopleage/peopleage.txt"),false)
val rand = new Random()
for (i <- 1 to 1000){
fileWriter.write(i+" "+rand.nextInt(100))
fileWriter.write(System.getProperty("line.separator"))
}
fileWriter.flush()
fileWriter.close()
}
}
3)sbt打包
退回到people目录下:

输入如下:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
输入命令打包:
sbt package
打包成功:

4)运行文件,生成peopleage.txt

可以看到目录下已经生成peopleage.txt,查看文件:

2、计算所有人口的平均年龄
1)创建CountAvgage.scala

2)代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object CountAvgAge {
def main(args:Array[String]) {
if (args.length < 1) {
println("Usage: CountAvgAge inputdatafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Count average age")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0),3)
val peopleNum =lines.count()
val totalAge = lines.map(line => line.split(" ")(1)).map(t => t.trim.toInt).collect().reduce((a,b) => a+b)
println("Total Age is: " +totalAge+ "; Number of People is: " +peopleNum)
val avgAge : Double = totalAge.toDouble / peopleNum.toDouble
println("Average Age is: " +avgAge)
}
}
3)打包
退回people文件夹,输入命令打包:

4)运行程序
输入如下命令:

结果:
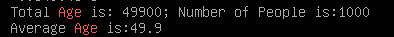
原文:http://dblab.xmu.edu.cn/blog/1756-2/
[spark程序]统计人口平均年龄(本地文件)(详细过程)的更多相关文章
- [spark程序]统计人口平均年龄(HDFS文件)(详细过程)
一.题目描述 (1)请编写Spark应用程序,该程序可以在分布式文件系统HDFS中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包 ...
- 记录一次用宝塔部署微信小程序Node.js后端接口代码的详细过程
一直忙着写毕设,上一次写博客还是元旦,大半年过去了.... 后面会不断分享各种新项目的源码与技术.欢迎关注一起学习哈! 记录一次部署微信小程序Node.js后端接口代码的详细过程,使用宝塔来部署. 我 ...
- R语言—统计结果输出至本地文件方法总结
1.sink()在代码开始前加一行:sink(“output.txt”),就会自动把结果全部输出到工作文件夹下的output.txt文本文档.这时在R控制台的输出窗口中是看不到输出结果的.代码结束时用 ...
- JNI初级:android studio生成so文件详细过程
本文主要参考blog:http://blog.csdn.net/jkan2001/article/details/54316375 下面是本人结合blog生成so包过程中遇到一些问题和解决方法 (1) ...
- Spark保存到HDFS或本地文件相关问题
spark中saveAsTextFile如何最终生成一个文件 http://www.lxway.com/641062624.htm 一般而言,saveAsTextFile会按照执行task的多少生成多 ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- Spark程序本地运行
Spark程序本地运行 本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!! spark是基于hadoop运算的,两者有依赖关系,见下图: 前言: 1.环境 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- spark本地环境的搭建到运行第一个spark程序
搭建spark本地环境 搭建Java环境 (1)到官网下载JDK 官网链接:https://www.oracle.com/technetwork/java/javase/downloads/jdk8- ...
随机推荐
- 洛谷P2051 [AHOI2009] 中国象棋(状压dp)
题目简介 n*m的棋盘,对每行放炮,要求每行每列炮数<=2,求方案数%9999973 N,M<=100 题目分析 算法考虑 考虑到N,M范围较小,每一行状态只与前面的行状态有关,考虑状压D ...
- 从源码的角度彻底搞懂 HandlerMapping 和 HandlerAdapter
彻底搞懂 HandlerMapping和HandlerAdapter 知识点的回顾: 当Tomcat接收到请求后会回调Servlet的service方法,一开始入门Servlet时,我们会让自己的Se ...
- phpstorm 设置换行符的格式
菜单 > 文件 > 设置
- 常用函数-Linux文件操作
/************************************************************************ 函数功能:寻找文件夹下的某格式文件 std::vec ...
- linux::jsoncpp库
下载库:http://sourceforge.net/projects/jsoncpp/files/ tar -zxvf jsoncpp-src- -C jsoncpp () 安装 scons $ s ...
- Flink Connector 深度解析
作者介绍:董亭亭,快手大数据架构实时计算引擎团队负责人.目前负责 Flink 引擎在快手内的研发.应用以及周边子系统建设.2013 年毕业于大连理工大学,曾就职于奇虎 360.58 集团.主要研究领域 ...
- 开源造轮子:一个简洁,高效,轻量级,酷炫的不要不要的canvas粒子运动插件库
一:开篇 哈哈哈,感谢标题党的莅临~ 虽然标题有点夸张的感觉,但实际上,插件库确实是简洁,高效,轻量级,酷炫酷炫的咯.废话不多说,先来看个标配例子吧: (codepen在线演示编辑:http://co ...
- Spring Boot Security And JSON Web Token
Spring Boot Security And JSON Web Token 说明 流程说明 何时生成和使用jwt,其实我们主要是token更有意义并携带一些信息 https://github.co ...
- 微信小程序中的canvas基础应用
学了东西还是要记录一下,刚入职的小萌新啊,运气好分到一个项目不是很急的组原以为时间多了可以多学一些东西,但是发现好像不知道从哪里开始下手,我太南了.... 看旁边的实习生同事一直在搞canvas,自己 ...
- Eureka和zookeeper的比较
什么是CAP? CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性). Availability(可用性).Partition tolerance(分区容错性),三者不 ...