mybatis源码学习(三)-一级缓存二级缓存
本文主要是个人学习mybatis缓存的学习笔记,主要有以下几个知识点
1.一级缓存配置信息
2.一级缓存源码学习笔记
3.二级缓存配置信息
4.二级缓存源码
5.一级缓存、二级缓存总结
1.一级缓存配置:
一级缓存是SqlSession级别的,同一个sqlSession执行多次相同的查询语句时,第二次会从缓存中获取数据,不查询数据库;一级缓存是无法关闭的,默认是SESSION级别
mybatis一级缓存默认是开启的,一级缓存有两个配置值,SESSION级别和STATEMENT级别,这两个级别的区别是:
如果是SESSION级别(默认值),那么在同一个sqlSession中,都会共享这个缓存
如果是STATEMENT级别,那么会把一级缓存中的缓存清空,也就是说,同一个sqlSession,多次请求同一个sql,每次都会查询数据库
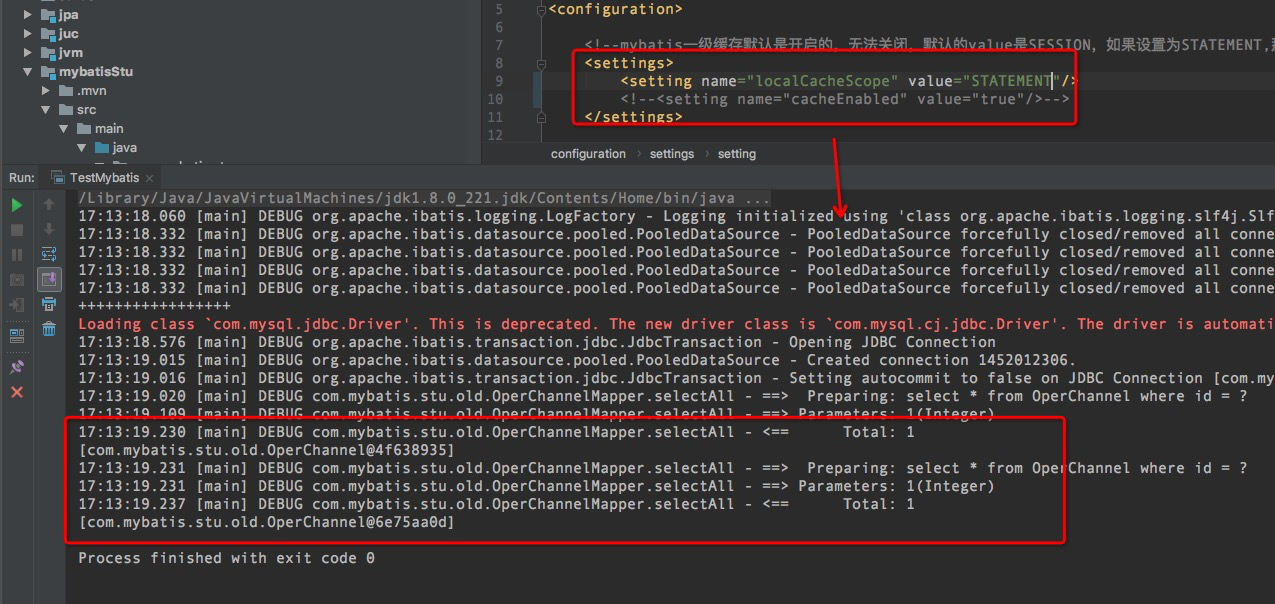
默认是session级别,此时为开启二级缓存:
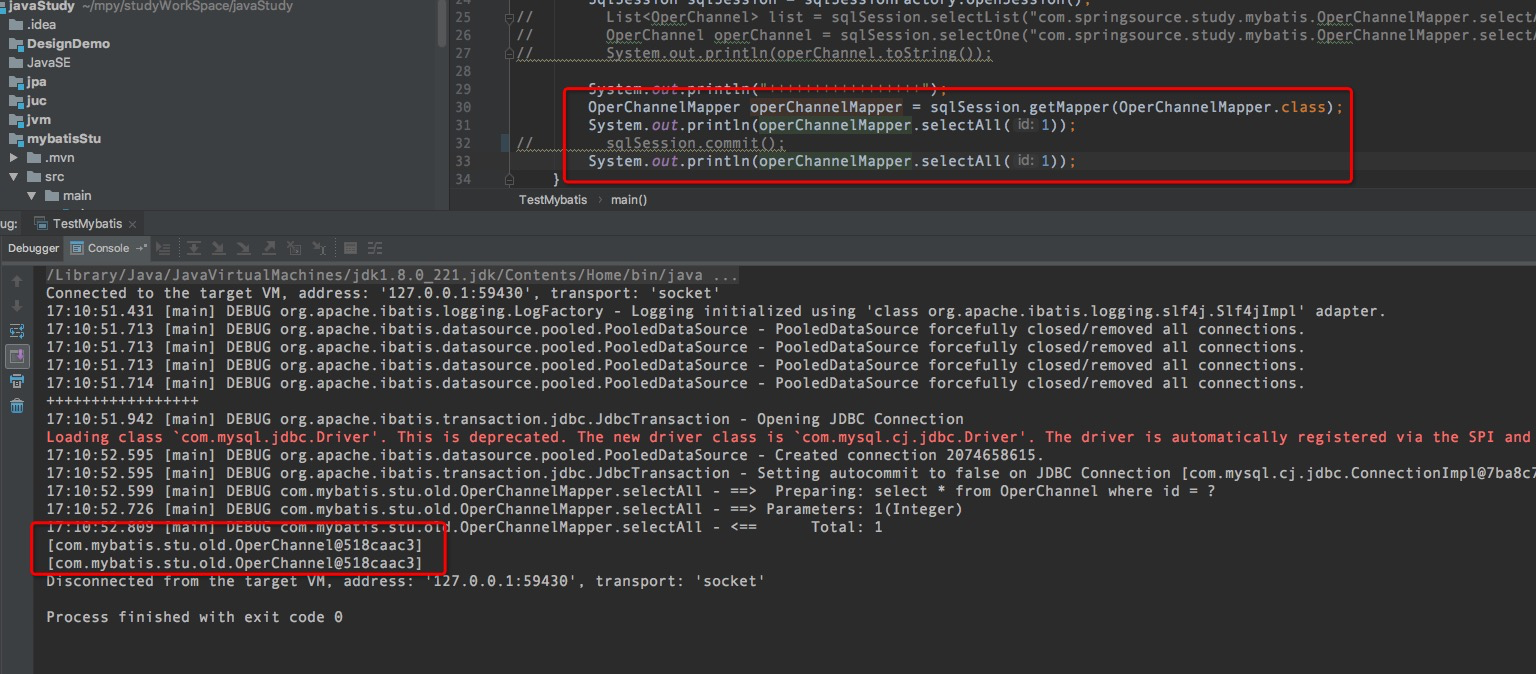
如果把一级缓存的级别设置为STATEMENT,那么同一个sqlSession执行多次相同的SQL,都会查询数据库:
那下面,我们来源码中验证
2.一级缓存源码:
1.首先会根据statement等参数,生成缓存中需要用到的key org.apache.ibatis.executor.CachingExecutor#createCacheKey
2.根据key从一级缓存中获取值,一级缓存是PerpetualCache这个类
org.apache.ibatis.executor.BaseExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler, org.apache.ibatis.cache.CacheKey, org.apache.ibatis.mapping.BoundSql)
3.如果从一级缓存中取到值,就不查询数据库;否则查询数据库
org.apache.ibatis.executor.BaseExecutor#handleLocallyCachedOutputParameters
4.如果一级缓存中没有取到值,就从数据库中查询,并将数据库中查询到的数据,存到一级缓存中
org.apache.ibatis.executor.BaseExecutor#queryFromDatabase
5.判断缓存级别是否是STATEMENT,如果是,将一级缓存清空
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
这段源码中,第14行,是尝试从一级缓存中根据key,取值;如果不为null,就从一级缓存中取值,第18行,是从数据中查询数据;
在 queryFromDatabase()方法中,会将数据库中查询到的数据,put到一级缓存中
源码中的第29行,就是对一级缓存是否是STATEMENT级别做判断,如果是,就clear;
我们再来说,insert、update、delete,这三种操作,都会走update,
org.apache.ibatis.executor.BaseExecutor#update
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
可以看到,执行doUpdate()方法之前,会先clear一级缓存
3.二级缓存配置
二级缓存是mapper级别的,需要配置才会开启
需要在mybatis的配置文件中,增加以下配置
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
并且在mapper.xml文件中增加
<cache></cache>
这样,二级缓存就开启了
4.二级缓存源码
二级缓存的源码,首先我们要看 org.apache.ibatis.executor.CachingExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler, org.apache.ibatis.cache.CacheKey, org.apache.ibatis.mapping.BoundSql) 这个方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache();
if (cache != null) {
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, parameterObject, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
在第7行,首先会判断,当前sql,是否开启useCache这个属性,对于select 默认是true;update、insert、delete默认是 false;这个点的源码是在解析xml的时候,最终会把每个select、update、insert、delete节点
build成一个mappedStatement,在build之前,有这么一段代码
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
org.apache.ibatis.builder.xml.XMLStatementBuilder#parseStatementNode
这里的意思是:如果是select,那么useCache就是true,否则就是false
接着上面的说,第10行会尝试从二级缓存中获取数据,这里的调用链是这样的
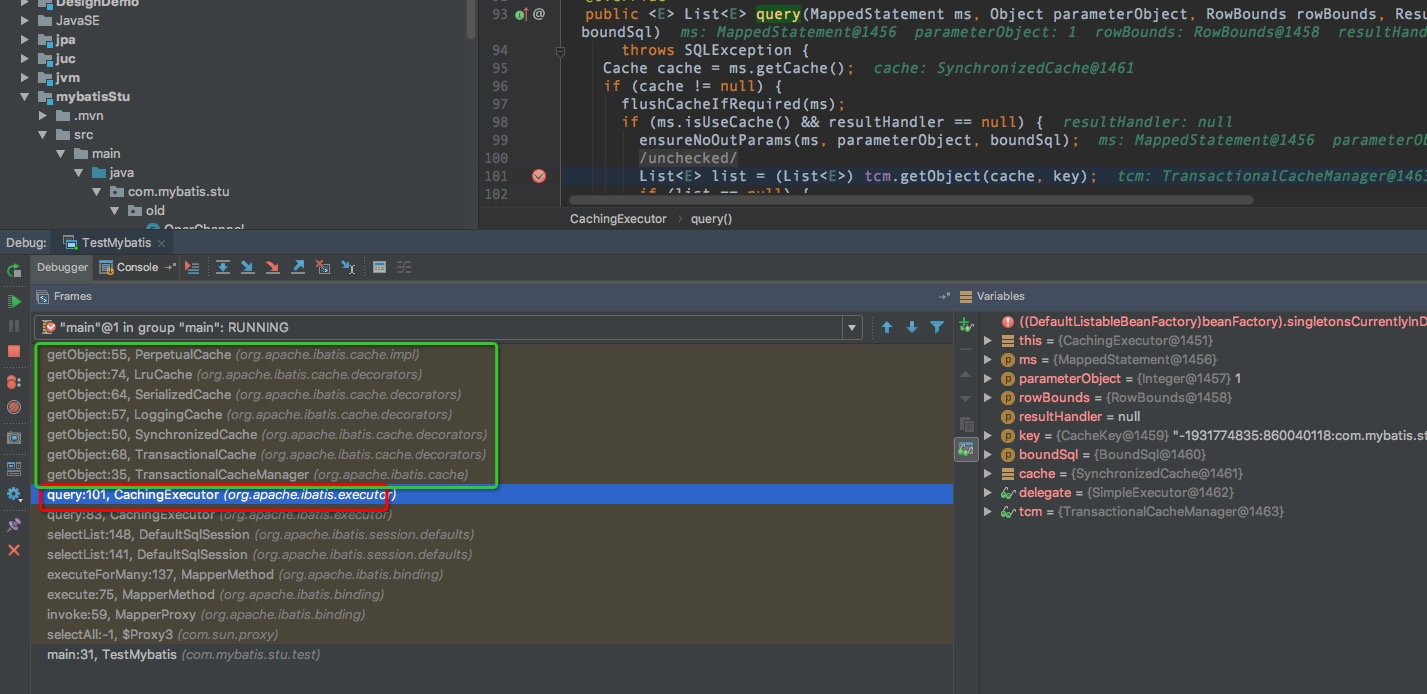
从源码中,可以看到,二级缓存先于以及缓存,如果二级缓存中没有取到值,会充以及缓存中国取,一级缓存中没有取到,再从数据库查询数据
这个调用链这几个cache,还没有搞明白,具体的作用,后面学习之后,会更新;
二级缓存有一个点,需要明确:二级缓存只有在sqlSession执行commit的时候,才会更新;否则是不生效的
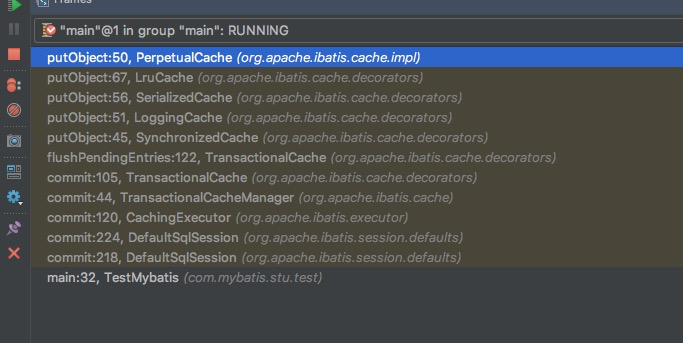
这个是commit的时候,二级缓存Put的调用链
5.总结
一级缓存是sqlSession级别的,二级缓存是mapper级别的,二级缓存的粒度更细,
一级缓存无法关闭,二级缓存可以开启或者关闭
一级缓存如果在分布式的场景下,可能会存在脏数据;
如果使用缓存,感觉还是Redis靠谱吧;
mybatis源码学习(三)-一级缓存二级缓存的更多相关文章
- mybatis源码学习:一级缓存和二级缓存分析
目录 零.一级缓存和二级缓存的流程 一级缓存总结 二级缓存总结 一.缓存接口Cache及其实现类 二.cache标签解析源码 三.CacheKey缓存项的key 四.二级缓存TransactionCa ...
- mybatis源码学习:基于动态代理实现查询全过程
前文传送门: mybatis源码学习:从SqlSessionFactory到代理对象的生成 mybatis源码学习:一级缓存和二级缓存分析 下面这条语句,将会调用代理对象的方法,并执行查询过程,我们一 ...
- mybatis源码学习:插件定义+执行流程责任链
目录 一.自定义插件流程 二.测试插件 三.源码分析 1.inteceptor在Configuration中的注册 2.基于责任链的设计模式 3.基于动态代理的plugin 4.拦截方法的interc ...
- Mybatis源码学习第六天(核心流程分析)之Executor分析
今Executor这个类,Mybatis虽然表面是SqlSession做的增删改查,其实底层统一调用的是Executor这个接口 在这里贴一下Mybatis查询体系结构图 Executor组件分析 E ...
- mybatis源码学习(一) 原生mybatis源码学习
最近这一周,主要在学习mybatis相关的源码,所以记录一下吧,算是一点学习心得 个人觉得,mybatis的源码,大致可以分为两部分,一是原生的mybatis,二是和spring整合之后的mybati ...
- Mybatis源码解析(三) —— Mapper代理类的生成
Mybatis源码解析(三) -- Mapper代理类的生成 在本系列第一篇文章已经讲述过在Mybatis-Spring项目中,是通过 MapperFactoryBean 的 getObject( ...
- 手把手带你阅读Mybatis源码(三)缓存篇
前言 大家好,这一篇文章是MyBatis系列的最后一篇文章,前面两篇文章:手把手带你阅读Mybatis源码(一)构造篇 和 手把手带你阅读Mybatis源码(二)执行篇,主要说明了MyBatis是如何 ...
- Mybatis源码学习之整体架构(一)
简述 关于ORM的定义,我们引用了一下百度百科给出的定义,总体来说ORM就是提供给开发人员API,方便操作关系型数据库的,封装了对数据库操作的过程,同时提供对象与数据之间的映射功能,解放了开发人员对访 ...
- Mybatis源码学习第八天(总结)
源码学习到这里就要结束了; 来总结一下吧 Mybatis的总体架构 这次源码学习我们,学习了重点的模块,在这里我想说一句,源码的学习不是要所有的都学,一行一行的去学,这是错误的,我们只需要学习核心,专 ...
随机推荐
- Linux性能分析
生产环境服务器变慢,诊断思路和性能评估 整机:top 代码 public class JavaDemo2 { public static void main(String[] args) { whil ...
- 前端技术之:JS开发几个有意思的东东
一. 查看性能分析报告 npm run build:prod --report 二.vue ui工具 三.vue-element-admin https://panjiachen.gite ...
- 在虚拟机上的关于NFS网络文件系统
小知识: NFS(Network Files System)即网络文件系统,NFS文件系统协议允许网络中的主机通过TCP/IP协议进行资源共享,NFS客户端可以像使用本地资源一样读写远端NFS服务端的 ...
- 【TCP/IP网络编程】:03地址族与数据序列
上一篇文章介绍了套接字的创建过程,这篇文章主要讨论分配给套接字的IP地址和端口号的相关知识. IP地址和端口号 IP(Internet Protocol,网络协议)地址是收发网络数据而分配给计算机的值 ...
- Netty连接处理那些事
编者注:Netty是Java领域有名的开源网络库,特点是高性能和高扩展性,因此很多流行的框架都是基于它来构建的,比如我们熟知的Dubbo.Rocketmq.Hadoop等,针对高性能RPC,一般都是基 ...
- 「Usaco2005 Dec」清理牛棚(spfa秒杀线段树dp)
约翰的奶牛们从小娇生惯养,她们无法容忍牛棚里的任何脏东西. 约翰发现,如果要使这群有洁癖的奶牛满意,他不得不雇佣她们中的一些来清扫牛棚, 约翰的奶牛中有N(1≤N≤10000)头愿意通过清扫牛棚来挣一 ...
- 大数据之路day03--java循环的延申与练习(while 、do-while、for)
在今天,我突然被一个很尴尬的问题问到了,问题是这样的:说一下java循环的应用场景. 我想很多人一下子听到这样的问题不知道怎么回答,大部分人会去想有什么循环格式,特点是什么.这些都是错误的,在往后的面 ...
- Kubernetes 挂载文件到pod里面
下面以chart为例子: 1.创建ConfigMap,这里要注意config.js为挂载的文件名 [root@cn-hongkong templates]# cat app-config.yaml a ...
- python之小木马(文件上传,下载,调用命令行,按键监控记录)
window版 服务端: 开启两个线程,一个用来接收客户端的输入,一个用来监控服务端键盘的记录 客户端: get 文件(下载)put 文件(上传) window下cmd命令执行结果会直接打印出来,ke ...
- egret开发方法(最笨的方法)
egret开发方法(最笨的方法)1 1个精灵1个对象名字 获取精灵设置属性也是直接获取对象设置属性 (不用想的少些代码 因为没有jquery好用) ps:如果要设置很多个精灵属性 那可以添加到数组 然 ...