ELK7.3实战安装配置文档
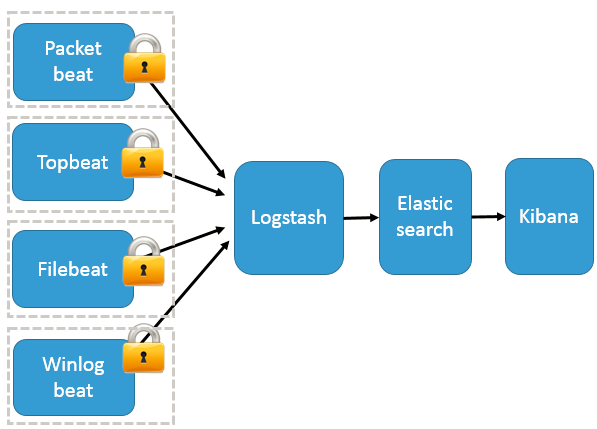
整体架构
一:环境准备
192.168.43.16 jdk,elasticsearch-master ,logstash,kibana
192.168.43.17 jdk,elasticsearch-node1
192.168.43.18 jdk,elasticsearch-node2
192.168.43.19 liunx ,filebeat
#解压
tar -zxvf jdk-12.0.2_linux-x64_bin.tar.gz -C /usr/ #设置环境变量
vim /etc/profile
export JAVA_HOME=/usr/jdk-12.0.2/
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH #使环境变量生效
source /etc/profile
# 修改系统文件
vim /etc/security/limits.conf #增加的内容
* soft nofile 65536
* hard nofile 65536
* soft nproc 2048
* hard nproc 4096 #修改系统文件
vim /etc/security/limits.d/20-nproc.conf #调整成以下配置
* soft nproc 4096
root soft nproc unlimited vim /etc/sysctl.conf
#在最后追加
vm.max_map_count=262144
fs.file-max=655360 #使用 sysctl -p 查看修改结果
sysctl -p
vim /etc/hosts
192.168.43.16 elk-master-node
192.168.43.17 elk-data-node1
192.168.43.18 elk-data-node2
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
groupadd elk
useradd ‐g elk elk
mkdir -p /home/app/elk
chown -R elk:elk /home/app/elk
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.2-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.3.2.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.3.2-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz -C /home/app/elk && \
tar -zxvf logstash-7.3.2.tar.gz -C /home/app/elk && \
tar -zxvf kibana-7.3.2-linux-x86_64.tar.gz -C /home/app/elk
二、安装elasticsearch
1、配置elasticsearch(切换至elk用户)
创建Elasticsearch数据目录 mkdir /home/app/elk/elasticsearch-7.3.2/data -p
创建Elasticsearch日志目录 mkdir /home/app/elk/elasticsearch-7.3.2/logs -p
主节点配置:vim /home/app/elk/elasticsearch-7.3.2/config/elasticsearch.yml
# 集群名称
cluster.name: es
# 节点名称
node.name: es-master
# 存放数据目录,先创建该目录
path.data: /home/app/elk/elasticsearch-7.3.2/data
# 存放日志目录,先创建该目录
path.logs: /home/app/elk/elasticsearch-7.3.2/logs
# 节点IP
network.host: 192.168.43.16
# tcp端口
transport.tcp.port: 9300
# http端口
http.port: 9200
# 种子节点列表,主节点的IP地址必须在seed_hosts中
discovery.seed_hosts: ["192.168.43.16:9300","192.168.43.17:9300","192.168.43.18:9300"]
# 主合格节点列表,若有多个主节点,则主节点进行对应的配置
cluster.initial_master_nodes: ["192.168.43.16:9300"]
# 主节点相关配置 # 是否允许作为主节点
node.master: true
# 是否保存数据
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false # 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
192.168.43.17数据节点从配置:vim /home/app/elk/elasticsearch-7.3.2/config/elasticsearch.yml
# 集群名称
cluster.name: es
# 节点名称
node.name: es-data1
# 存放数据目录,先创建该目录
path.data: /home/app/elk/elasticsearch-7.3.2/data
# 存放日志目录,先创建该目录
path.logs: /home/app/elk/elasticsearch-7.3.2/logs
# 节点IP
network.host: 192.168.43.17
# tcp端口
transport.tcp.port: 9300
# http端口
http.port: 9200
# 种子节点列表,主节点的IP地址必须在seed_hosts中
discovery.seed_hosts: ["192.168.43.16:9300","192.168.43.17:9300","192.168.43.18:9300"]
# 主合格节点列表,若有多个主节点,则主节点进行对应的配置
cluster.initial_master_nodes: ["192.168.43.16:9300"]
# 主节点相关配置 # 是否允许作为主节点
node.master: false
# 是否保存数据
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false # 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
# 集群名称
cluster.name: es
# 节点名称
node.name: es-data2
# 存放数据目录,先创建该目录
path.data: /home/app/elk/elasticsearch-7.3.2/data
# 存放日志目录,先创建该目录
path.logs: /home/app/elk/elasticsearch-7.3.2/logs
# 节点IP
network.host: 192.168.43.18
# tcp端口
transport.tcp.port: 9300
# http端口
http.port: 9200
# 种子节点列表,主节点的IP地址必须在seed_hosts中
discovery.seed_hosts: ["192.168.43.16:9300","192.168.43.17:9300","192.168.43.18:9300"]
# 主合格节点列表,若有多个主节点,则主节点进行对应的配置
cluster.initial_master_nodes: ["192.168.43.16:9300"]
# 主节点相关配置 # 是否允许作为主节点
node.master: false
# 是否保存数据
node.data: true
node.ingest: false
node.ml: false
cluster.remote.connect: false # 跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
2、启动elasticserach
sh /home/app/elk/elasticsearch-7.3.2/bin/elasticsearch -d
3、监控检查
curl -X GET 'http://192.168.43.16:9200/_cluster/health?pretty'
[root@localhost elk]# curl -X GET 'http://192.168.43.16:9200/_cluster/health?pretty'
{
"cluster_name" : "es",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 3,
"active_primary_shards" : 5,
"active_shards" : 10,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
#status=green表示服务正常
三、安装kibana
1、修改配置文件
cd /home/app/elk/kibana-7.3.2-linux-x86_64/config
vim kibana.yml
# 配置kibana的端口
server.port: 5601
# 配置监听ip
server.host: "192.168.43.16"
# 配置es服务器的ip,如果是集群则配置该集群中主节点的ip
elasticsearch.hosts: "http://192.168.43.16:9200/"
# 配置kibana的日志文件路径,不然默认是messages里记录日志
logging.dest:/home/app/elk/kibana-7.3.2-linux-x86_64/logs/kibana.log
2、启动kibana
nohup /home/app/elk/kibana-7.3.2-linux-x86_64/bin/kibana &
三、安装filebeat(192.168.43.19上事先跑了jumpserver服务)
本次实验我们在192.168.43.19上安装filebeat单独对nginx的访问日志和错误日志进行采集,网上有关于发送json格式的配置,在此为了练习grok,直接发送原格式进行配置
1、下载filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.2-linux-x86_64.tar.gz
mkdir -p /opt/software
tar -zxvf filebeat-7.3.2-linux-x86_64.tar.gz -C /opt/software
2、配置filebeat.yml
vim /opt/software/filebeat-7.3.2/filebeat.yml
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
fields:
log_source: nginx-access
- type: log
paths:
- /var/log/nginx/error.log
fields:
log_source: nginx-error
#============================== Dashboards =====================================
setup.dashboards.enabled: false
#============================== Kibana =====================================
#添加libana仪表盘
setup.kibana:
host: "192.168.43.16:5601"
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.43.16:5044"]
3、启动filebeat
cd /opt/software/filebeat-7.3.2
nohup ./filebeat -c filebeat.yml &
四、安装logstash
1、创建logstash.conf文件
vim /home/app/elk/logstash-7.3.2/config/logstash.conf
input {
beats {
port => 5044
}
}
filter {
if [fields][log_source]=="nginx-access"{
grok {
match => {
"message" => '%{IP:clientip}\s*%{DATA}\s*%{DATA}\s*\[%{HTTPDATE:requesttime}\]\s*"%{WORD:requesttype}.*?"\s*%{NUMBER:status:int}\s*%{NUMBER:bytes_read:int}\s*"%{DATA:requesturl}"\s*%{QS:ua}'
}
overwrite => ["message"]
}
}
if [fields][log_source]=="nginx-error"{
grok {
match => {
"message" => '(?<time>.*?)\s*\[%{LOGLEVEL:loglevel}\]\s*%{DATA}:\s*%{DATA:errorinfo},\s*%{WORD}:\s*%{IP:clientip},\s*%{WORD}:%{DATA:server},\s*%{WORD}:\s*%{QS:request},\s*%{WORD}:\s*%{QS:upstream},\s*%{WORD}:\s*"%{IP:hostip}",\s*%{WORD}:\s*%{QS:referrer}'
}
overwrite => ["message"]
}
}
}
output {
if [fields][log_source]=="nginx-access"{
elasticsearch {
hosts => ["http://192.168.43.16:9200"]
action => "index"
index => "nginx-access-%{+YYYY.MM.dd}"
}
}
if [fields][log_source]=="nginx-error"{
elasticsearch {
hosts => ["http://192.168.43.16:9200"]
action => "index"
index => "nginx-error-%{+YYYY.MM.dd}"
}
}
stdout { codec => rubydebug }
}
2、启动logstash
/home/app/elk/logstash-7.3.2/bin/logstash -f /home/app/elk/logstash-7.3.2/config/logstash.conf
六、登陆kibana平台
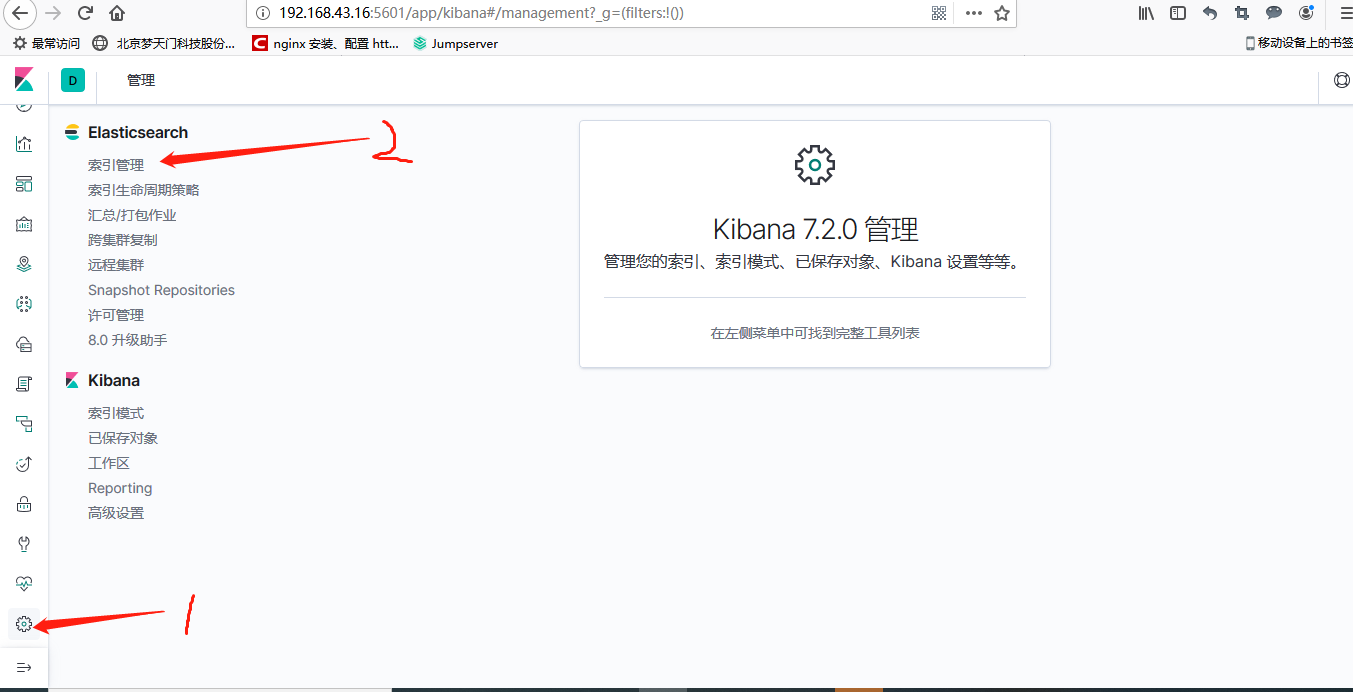
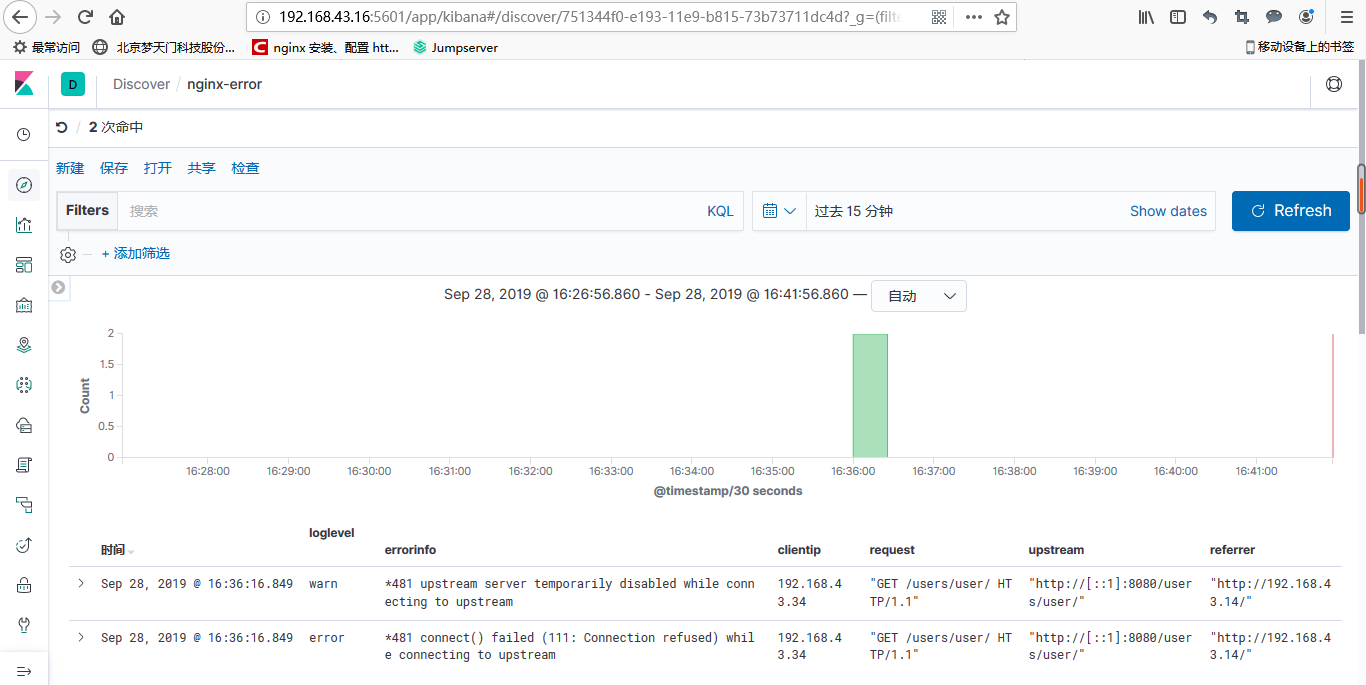
分别点击管理--》索引管理,这时候就能看到nginx的访问日志和错误日志的数据了
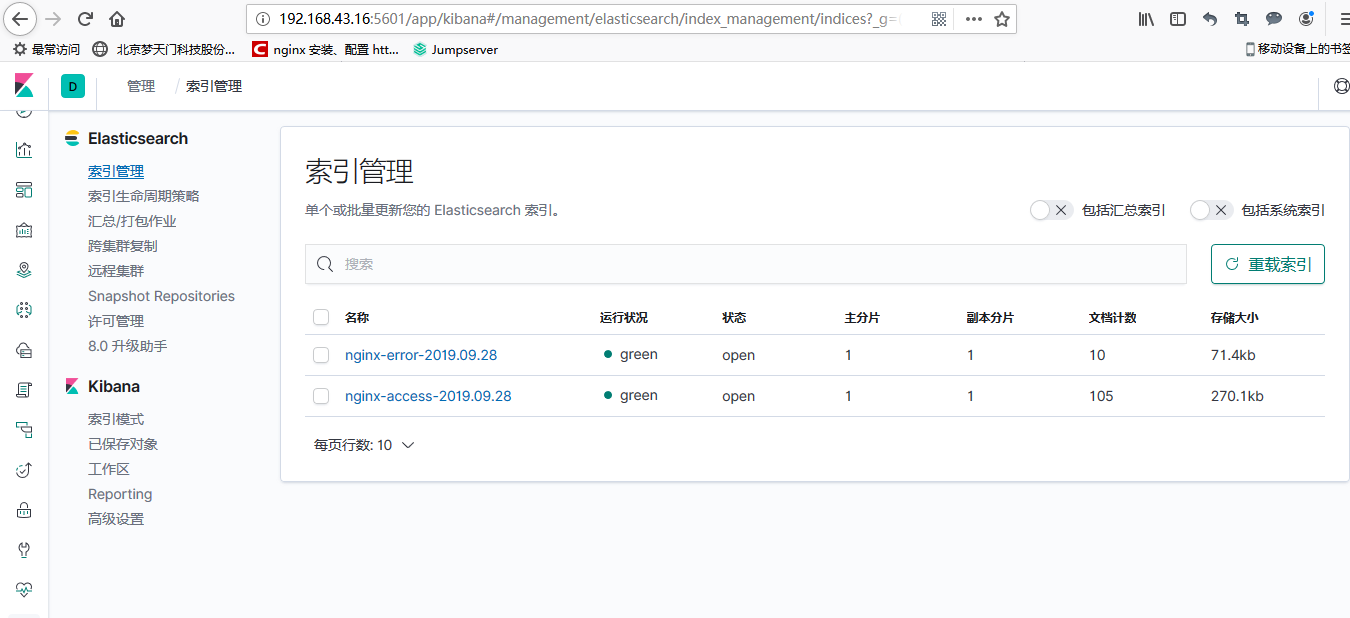
接下来创建索引,分别对访问日志和错误日志建立索引,建立完之后点击discover,就能看到日志数据了
nginx-access
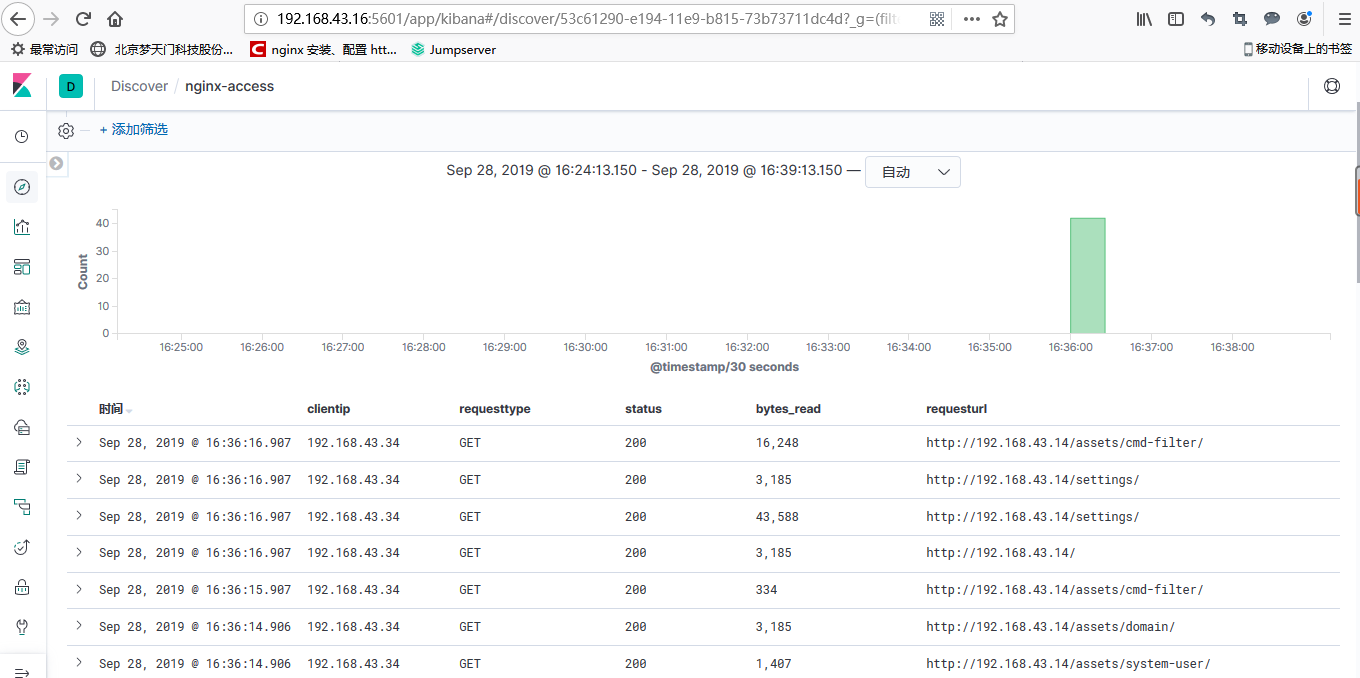
nginx-error
参考文档:
https://elkguide.elasticsearch.cn/logstash/plugins/filter/mutate.html
ELK7.3实战安装配置文档的更多相关文章
- azkaban编译安装配置文档
azkaban编译安装配置文档 参考官方文档: http://azkaban.github.io/azkaban/docs/latest/ azkaban的配置文件说明:http://azkaban. ...
- Oracle12C安装配置文档
Oracle12C安装配置文档 Oracle12C安装配置文档 准备软件: 开始安装: 打开从官网下载下来的两个压缩包,进行解压 打开解压好的后缀为2of2的文件夹找到路径为database下的“ ...
- IDEA2018.1安装配置文档
一.软件安装 1. 下载地址: https://www.jetbrains.com/idea/download/#section=windows 2. 安装: 点击.exe,选择安装路径,点击next ...
- ELK6.x_Kafka 安装配置文档
1. 环境描述 1.1. 环境拓扑 如上图所示:Kafka为3节点集群负责提供消息队列,ES为3节点集群.日志通过logstash或者filebeat传送至Kafka集群,再通过logstash发 ...
- RHEL6-HA集群在VMware虚拟机环境安装配置文档
(一)系统环境描述 本文档基于RHEL6u5 系统安装,配置为2节点高可用集群,节点为两台VMware虚拟机. 也可参考http://blog.51cto.com/ty1992/1325327 (二) ...
- MySQL5.6.36 linux rpm包安装配置文档
一.卸载自带mysql,删除MySQL的lib库,服务文件 [root@localhost ~]#rpm -qa|grep mysql qt-mysql-4.6.2-26.el6_4.x86_64 m ...
- Weblate 2.11安装配置文档
一.系统环境: OS:CentOS 6.8 x64 Minimal HostName:Weblate IP:192.168.75.153 Python:2.7.13 pip:9.0.1 Weblate ...
- ganlia安装配置文档
gangliaz在ubuntu中安装和配置很简单 1. 服务器端安装 sudo apt-get install ganglia-monitor ganglia-webfrontend rrdtool ...
- WebLogic12C安装配置文档
jdk版本:1.8; jdk安装路径不准有空格 JDK安装: jdk版本:1.8; jdk安装路径不准有空格 WebLogic安装: 解压安装包 解压JAR 找到fmw_12.2.1.3.0_wls\ ...
随机推荐
- Liunx软件安装之Redis
Redis是一个开源(BSD许可),内存数据结构存储,用作数据库,缓存和消息代理.它支持数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,位图,超级日志和带有半径查询的地理空间索引.Redi ...
- egret之红包满屏随意飘动
在做这个需求之前,我们假设屏幕上同时飘动的红包数最大为10 ) { let redBag = GameUtil.createBitmapByName("Red_bag_png"); ...
- 极简Docker和Kubernetes发展史
2013年 Docker项目开源 2013年,以AWS及OpenStack,以Cloud Foundry为代表的开源Pass项目,成了云计算领域的一股清流,pass提供了一种"应用托管&qu ...
- Spring 核心技术(7)
接上篇:Spring 核心技术(6) version 5.1.8.RELEASE 1.6 定制 Bean 的特性 Spring Framework 提供了许多可用于自定义 bean 特性的接口.本节将 ...
- [企业微信通知系列]Jenkins发布后自动通知
一.前言 最近使用Jenkins进行自动化部署,但是部署后,并没有相应的通知,虽然有邮件发送通知,但是发现邮件会受限于接收方的接收设置,导致不能及时看到相关的发布内容.而由于公司使用的是企业微信,因此 ...
- JIra配置权限方案
目录: 添加用户 添加用户组 将用户分配到不同的组中 创建项目权限方案 配置项目采用的权限方案 1. 添加用户 1)使用admin权限的账户登录后,点击右上角的配置,选择system 2)在打开的页面 ...
- 【转载】Why Learning to Code is So Damn Hard By Erik Trautman
原文网址:https://www.thinkful.com/blog/why-learning-to-code-is-so-damn-hard/ 在罗老师的<算法竞赛 入门到进阶>总看到了 ...
- NOIP 2016 蚯蚓 题解
一道有趣的题目,首先想到合并果子,然而发现会超时,我们可以发现首先拿出来的切掉后比后拿出来切掉后还是还长,即满足单调递增,故建立三个队列即可. 代码 #include<bits/stdc++.h ...
- poj1037 [CEOI 2002]A decorative fence 题解
---恢复内容开始--- 题意: t组数据,每组数据给出n个木棒,长度由1到n,除了两端的木棒外,每一根木棒,要么比它左右的两根都长,要么比它左右的两根都短.即要求构成的排列为波浪型.对符合要求的排列 ...
- Allure-pytest功能特性介绍
前言 Allure框架是一个灵活的轻量级多语言测试报告工具,它不仅以web的方式展示了简介的测试结果,而且允许参与开发过程的每个人从日常执行的测试中最大限度的提取有用信息从dev/qa的角度来看,Al ...