python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜
本次主要爬取Top100电影榜单的电影名、主演和上映时间, 同时保存为excel表个形式, 其他相似榜单也都可以依葫芦画瓢
首先打开要爬取的网址https://maoyan.com/board/4, 在不断点击下一页的过程中, 我们可以发现网址的变化是有规律的
https://maoyan.com/board/4?offset=0
https://maoyan.com/board/4?offset=10
https://maoyan.com/board/4?offset=20
不同的页数, 变化的只有offset后面的数字, 且以10的倍数增长
使用的python库
1. requests -> 请求页面
2. re -> 匹配想要获取的内容
3. pandas -> 使内容看起来更有结构化, 同时帮助我们将内容保存为文件
开始编写爬虫程序
- 获取网页源码
base_url = 'https://maoyan.com/board/4?offset='
# 伪造一个请求头, 这个网上有很多
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
}
def get_every_page(url):
result = requests.get(url, headers=headers)
# 响应成功则返回源代码内容
if result.status_code == requests.codes.ok:
return result.text
return None
- 分析源码特征, 编写正则表达式, 获取主要内容
<dd>
<i class="board-index board-index-20">20</i>
<a href="/films/428" title="指环王3:王者无敌" class="image-link" data-act="boarditem-click" data-val="{movieId:428}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="https://p0.meituan.net/movie/932bdfbef5be3543e6b136246aeb99b8123736.jpg@160w_220h_1e_1c" alt="指环王3:王者无敌" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/428" title="指环王3:王者无敌" data-act="boarditem-click" data-val="{movieId:428}">指环王3:王者无敌</a></p>
<p class="star">
主演:伊莱贾·伍德,伊恩·麦克莱恩,丽芙·泰勒
</p>
<p class="releasetime">上映时间:2004-03-15</p>
</div>
<div class="movie-item-number score-num">
<p class="score">
<i class="integer">9.</i>
<i class="fraction">2</i>
</p>
</div>
</div>
</div>
</dd>
从返回的源码中可以发现, 电影的信息都集中在<dd>标签内, 根据其规律, 编写下列正则表达式获取电影名、主演和上映时间的信息
# filmname = []
# actor = []
# stime = []
html = get_every_page(url)
if html:
# 获取电影信息
# 同时这里需要注意的重点是, 一定不要忘记了修饰符re.S, 否则什么也匹配不出来!
data = re.findall('<dd.*?title="(.*?)".*?"star">(.*?)<.*?">(.*?)</p>', html, re.S)
# data中的每一个都是一个元组
输出每一个元组的信息(以某一页为例)
('霸王别姬', '\n 主演:张国荣,张丰毅,巩俐\n ', '上映时间:1993-01-01')
('肖申克的救赎', '\n 主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿\n ', '上映时间:1994-09-10(加拿大)')
('罗马假日', '\n 主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特\n ', '上映时间:1953-09-02(美国)')
('这个杀手不太冷', '\n 主演:让·雷诺,加里·奥德曼,娜塔莉·波特曼\n ', '上映时间:1994-09-14(法国)')
('泰坦尼克号', '\n 主演:莱昂纳多·迪卡普里奥,凯特·温丝莱特,比利·赞恩\n ', '上映时间:1998-04-03')
('唐伯虎点秋香', '\n 主演:周星驰,巩俐,郑佩佩\n ', '上映时间:1993-07-01(中国香港)')
('魂断蓝桥', '\n 主演:费雯·丽,罗伯特·泰勒,露塞尔·沃特森\n ', '上映时间:1940-05-17(美国)')
('乱世佳人', '\n 主演:费雯·丽,克拉克·盖博,奥利维娅·德哈维兰\n ', '上映时间:1939-12-15(美国)')
('天空之城', '\n 主演:寺田农,鹫尾真知子,龟山助清\n ', '上映时间:1992-05-01')
('辛德勒的名单', '\n 主演:连姆·尼森,拉尔夫·费因斯,本·金斯利\n ', '上映时间:1993-12-15(美国)')
因为输出的信息格式差异很大, 我们再来统一一下格式
# data = re.findall('<dd.*?title="(.*?)".*?"star">(.*?)<.*?">(.*?)</p>', html, re.S)
# 去除空格和多余的字符, 分别提取出电影名, 主演和上映时间
for i in data:
filmname.append(i[0].strip())
actor.append((i[1].strip())[3:])
stime.append(i[2][5:].strip())
- 将结果保存为文件
将内容生成为DataFrame对象, 再保存为文件
tdict = {'电影名': filmname, '主演': actor, '上映时间': stime}
tdict = pd.DataFrame(tdict, index=[i for i in range(1, 101)])
tdict.to_excel('Top100电影排行榜.xlsx', encoding='utf-8')
print(tdict)
- 完整代码
import requests
import re
import pandas as pd
base_url = 'https://maoyan.com/board/4?offset='
headers = {
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)'
}
def get_every_page(url):
result = requests.get(url, headers=headers)
if result.status_code == requests.codes.ok:
return result.text
return None
def main():
filmname = []
actor = []
stime = []
for i in range(0, 110, 10):
url = base_url + str(i)
html = get_every_page(url)
if html:
data = re.findall('<dd.*?title="(.*?)".*?"star">(.*?)<.*?">(.*?)</p>', html, re.S)
for i in data:
filmname.append(i[0].strip())
actor.append((i[1].strip())[3:])
stime.append(i[2][5:].strip())
tdict = {'电影名': filmname, '主演': actor, '上映时间': stime}
tdict = pd.DataFrame(tdict, index=[i for i in range(1, 101)])
tdict.to_excel('Top100电影排行榜.xlsx', encoding='utf-8')
print(tdict)
main()
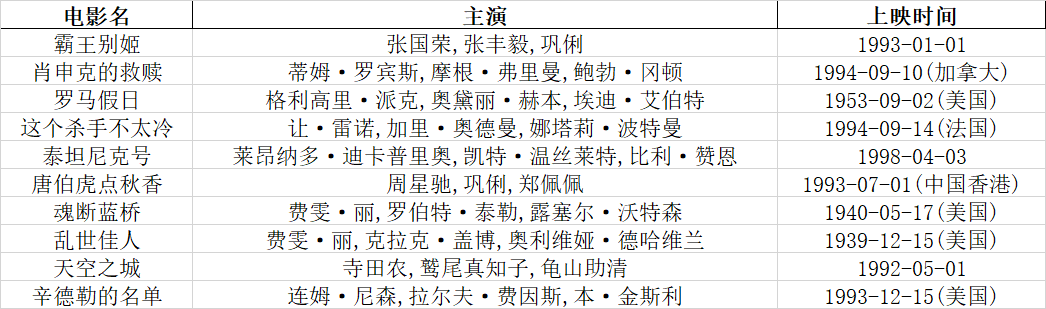
- 检验成功
打开我们的生成的Top100电影排行榜表格, 结果完美输出nice!
(截取Top10)
python爬虫入门新手向实战 - 爬取猫眼电影Top100排行榜的更多相关文章
- 爬虫(七):爬取猫眼电影top100
一:分析网站 目标站和目标数据目标地址:http://maoyan.com/board/4?offset=20目标数据:目标地址页面的电影列表,包括电影名,电影图片,主演,上映日期以及评分. 二:上代 ...
- 多种方法爬取猫眼电影Top100排行榜,保存到csv文件,下载封面图
参考链接: https://blog.csdn.net/BF02jgtRS00XKtCx/article/details/83663400 https://www.makcyun.top/web_sc ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
随机推荐
- python 04 列表
1.列表——list [ ] 有序.可变.支持索引查看. 存储数据,支持大多数数据类型:字符串,数字,布尔值.列表.集合.元组.字典等. 1.1 定义: lst(勿用list) lst = [&qu ...
- 设计模式(C#)——09外观模式
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 前言 在软件开发过程中,客户端程序经常会与复杂系统的内部子系统进行耦合,从而导致客户端程序随着子系统的变化而变化,然 ...
- Redis持久化的原理及优化
更多内容,欢迎关注微信公众号:全菜工程师小辉~ Redis提供了将数据定期自动持久化至硬盘的能力,包括RDB和AOF两种方案,两种方案分别有其长处和短板,可以配合起来同时运行,确保数据的稳定性. RD ...
- 用Python操作文件
用Python操作文件 用word操作一个文件的流程如下: 1.找到文件,双击打开. 2.读或修改. 3.保存&关闭. 用Python操作文件也差不多: f=open(filename) # ...
- 牛客练习赛17 B-好位置
传送门 题意:本来惯例中文题不解释的, 但是有些人不懂这个题意, 简单的来说, 就是s1每一个的每一个字符都可以和别的字符构成一个子串 == s2. 算了还是惯例中文题意不解释吧. 题解:其实以前写 ...
- codeforces 755D. PolandBall and Polygon(线段树+思维)
题目链接:http://codeforces.com/contest/755/problem/D 题意:一个n边形,从1号点开始,每次走到x+k的位置如果x+k>n则到x+k-n的位置,问每次留 ...
- Flask源码浅析
前言 学习一样东西,要先知其然,然后知其所以然. 这次,我们看看Flask Web框架的源码.我会以Flask 0.1的源码为例,把重点放在Flask如何处理请求上,看一看从一个请求到来到返回响应都经 ...
- HTML图片死活不显示
图片不显示: 1.路径 2.名称 3.少写了" ... " 正确的例子:“../images/dd.png” 4.多写了一个“/” ,或者少写了一个“ . ” ,没错.不是三个点, ...
- c++拷贝构造函数引用传参
看一道C++面试题: 给出下述代码,分析编译运行的结果,并提供3个选项: A.编译错误 B.编译成功,运行时程序崩溃 C.编译运行正常,输出10 class A { private: int va ...
- 阿里云机器维护-gitlab Forbidden
gitlab这台机子运行了一两年了,今天突然拉代码不能拉了,看了下接口403 登录网页 Forbidden 看了下是前两天挖矿病毒引发的,大致因为大量请求导致ip被封了 我们只要把这台机子加入配置白名 ...