Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习
如有侵权,请联系删除
获取url参数 urlparse 和 parse_qs
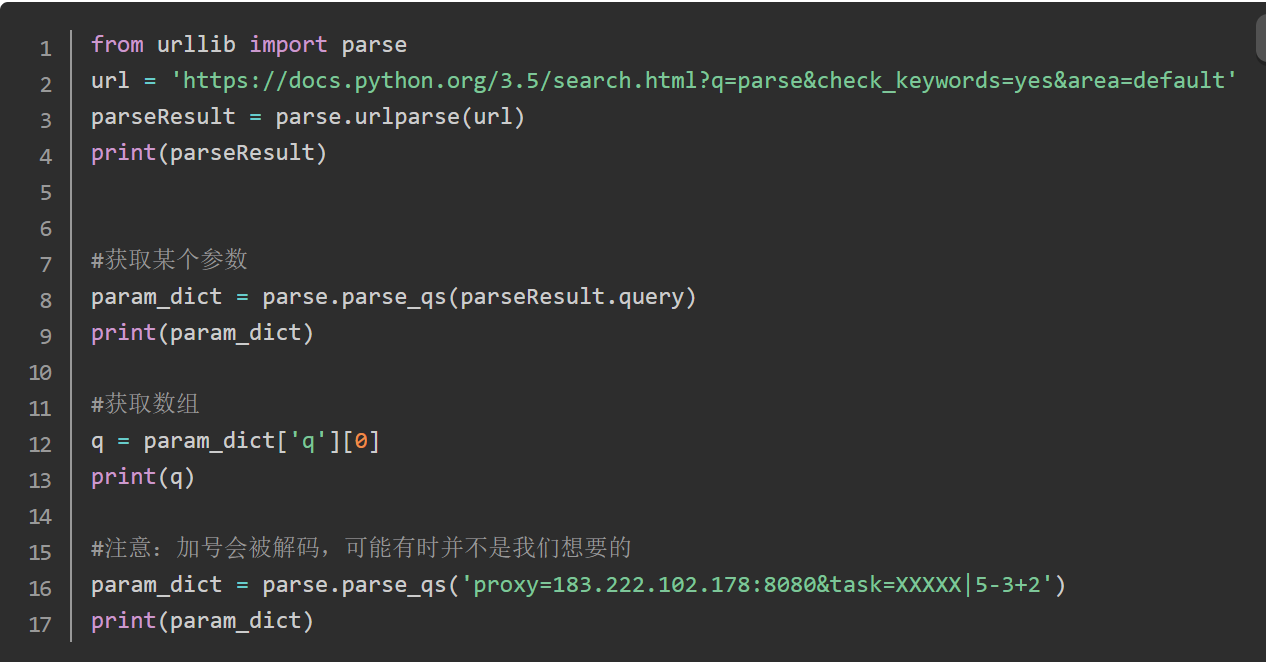
ParseResult(scheme='https', netloc='docs.python.org', path='/3.5/search.html', params='', query='q=parse&check_keywords=yes&area=default', fragment='')
{'q': ['parse'], 'check_keywords': ['yes'], 'area': ['default']}
parse
{'proxy': ['183.222.102.178:8080'], 'task': ['XXXXX|5-3 2']}
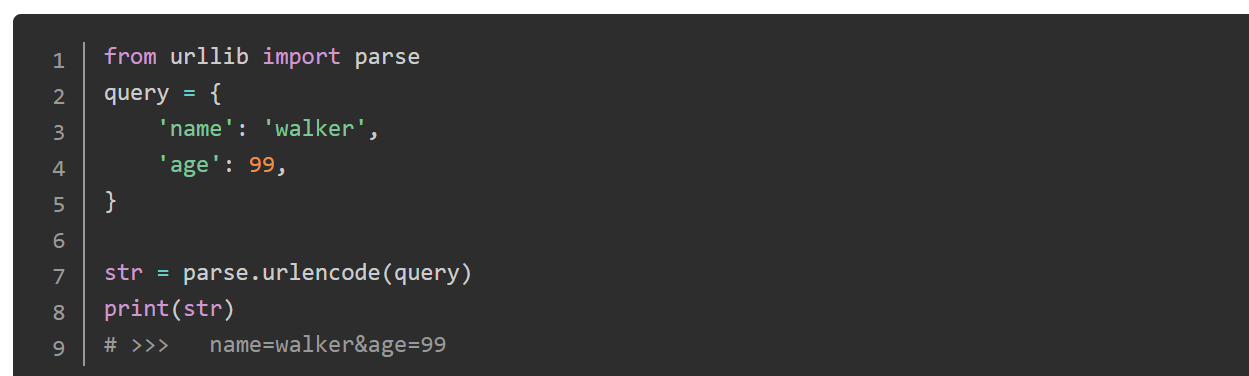
urlencode json 解析成 url参数
对url参数进行编码 quote/quote_plus

对url参数进行解码 unquote/unquote_plus

Python爬虫入门:Urllib parse库使用详解(二)的更多相关文章
- Python爬虫之urllib.parse详解
Python爬虫之urllib.parse 转载地址 Python 中的 urllib.parse 模块提供了很多解析和组建 URL 的函数. 解析url 解析url( urlparse() ) ur ...
- python爬虫入门urllib库的使用
urllib库的使用,非常简单. import urllib2 response = urllib2.urlopen("http://www.baidu.com") print r ...
- Python爬虫入门 Urllib库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- Python爬虫连载4-Error模块、Useragent详解
一.error 1.URLError产生的原因:(1)没有网络:(2)服务器连接失败:(3)不知道指定服务器:(4)是OSError的子类 from urllib import request,err ...
- 转python爬虫:BeautifulSoup 使用select方法详解
1 html = """ 2 <html><head><title>The Dormouse's story</title> ...
- 爬虫入门之urllib库详解(二)
爬虫入门之urllib库详解(二) 1 urllib模块 urllib模块是一个运用于URL的包 urllib.request用于访问和读取URLS urllib.error包括了所有urllib.r ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
随机推荐
- RHCE7 认证之学习笔记
-------------------------------------------------------------------------------------------初始化:两台服务器 ...
- C#-宽带连接
public static string Connect(string UserS,string PwdS) { string arg = @"rasdial.exe 宽带连接" ...
- Windows核心编程 第七章 线程的调度、优先级和亲缘性(上)
第7章 线程的调度.优先级和亲缘性 抢占式操作系统必须使用某种算法来确定哪些线程应该在何时调度和运行多长时间.本章将要介绍Microsoft Windows 98和Windows 2000使用的一些算 ...
- Windows核心编程 第三章 内核对象
第3章内核对象 在介绍Windows API的时候,首先要讲述内核对象以及它们的句柄.本章将要介绍一些比较抽象的概念,在此并不讨论某个特定内核对象的特性,相反只是介绍适用于所有内核对象的特性. 首先介 ...
- http预请求options
在有很多情况下,当我们在js里面调用一次ajax请求时,在浏览器那边却会查询到两次请求,第一次的Request Method参数是OPTIONS,还有一次就是我们真正的请求,比如get或是post请求 ...
- 数据人必读!玩转数据可视化用这个就够了——高德LOCA API 2.0升级来袭!
引言 "一图胜千言",大数据时代来临,数据与人们生活密切相关.复杂难懂且体量庞大的数据给人的感觉总是冷冰冰的,让人难以获取到重点信息,也找不出规律和特征,数据价值发挥不出来.空间数 ...
- Java对象内存分布
[deerhang] 创建对象的四种方式:new关键字.反射.Object.clone().unsafe方法 new和反射是通过调用构造器创建对象的,创建对象的时候使用invokespecial指令 ...
- 用Taro写一个微信小程序(二)——配置目录别名
配置别名可以方便书写代码引用路径,让代码更整洁. 官方文档可参考https://nervjs.github.io/taro/docs/config-detail#alias 一.在config/ind ...
- NetCore3.1及Vue开发通用RBAC前后端通用框架
目录 框架说明 项目框架图 多租户权限设计表 效果图 后端拉取运行 前端项目请参考 前端系列 发布到docker中 netcore3.1 发布到docker中所遇到的坑及解决 框架说明 该框架是本人学 ...
- Spring循环依赖问题的解决
循环依赖问题 一个bean的创建分为如下步骤: 当创建一个简单对象的时候,过程如下: 先从单例池中获取bean,发现无 a 创建 a 的实例 为 a 赋值 把 a 放到单例池中 当创建一个对象并且其中 ...