TinyML-TVM是如何驯服Tiny的(下)
TinyML-TVM是如何驯服Tiny的(下)
Lazy Execution
实际上,随着通信开销开始占主导地位,一旦用户请求,就执行算子的开销变得非常昂贵。可以通过延迟评估直到用户需要调用的结果来提高系统的吞吐量。
从实现的角度来看,现在需要在主机端积累函数调用元数据,然后再将其刷新到设备,而不是急于序列化参数元数据和UTVMTask数据。设备runtime也需要一些改变:
(1)现在必须有一个UTVMTask的全局数组
(2)需要循环执行每个任务。
带MicroTVM的AutoTVM
到目前为止,所描述的runtime对于模型部署似乎不是很有用,因为它非常依赖于主机。这是有意的,而runtime实际上是为另一个目标而设计的:AutoTVM支持。
一般来说,AutoTVM提出候选内核,在目标后端随机输入运行,然后使用计时结果来改进其搜索过程。考虑到AutoTVM只关心单个算子的执行,将runtime设计为面向算子,而不是面向模型。但是,在µTVM的情况下,与设备的通信通常将支配执行时间。延迟执行允许多次运行同一个算子,而不将控制权返回给主机,因此通信成本在每次运行中分摊,可以更好地了解性能配置文件。
由于AutoTVM需要在大量候选内核上进行快速迭代,因此µTVM基础设施目前仅使用RAM。然而,对于自托管runtime,肯定需要同时使用闪存和RAM。
托管图形runtime
虽然托管runtime是为AutoTVM设计的,但是仍然可以运行完整的模型(只要没有任何控制流)。此功能仅通过使用TVM的graph runtime免费提供,但需要使用µTVM上下文。事实上,在运行图时对主机的唯一依赖是用于张量分配和算子调度(这只是依赖图的一种拓扑类型)。
Evaluation
有了这一基础架构,试图回答以下问题:
µTVM真的不受设备限制吗?
使用µTVM进行优化实验需要多少算力?
为了评估(1),对两个目标进行了实验:
Arm STM32F746NG开发板,具有Cortex-M7处理器
µTVM主机模拟设备,它在主机上创建一个内存竞技场,与主机接口,就好像它是一个裸机设备一样。
为了评估(2),将探索Arm板的优化,以使成本最大化。
作为比较,使用Arm从本教程中提取了一个量化的CIFAR-10cnn。CMSIS-NN(Arm专家高度优化的内核库)被用作算子库,这使CNN成为完美的评估目标,因为现在可以在Arm板上直接比较µTVM和CMSIS-NN的结果。
Methodology
Arm-Specific Optimizations
使用了TVM from HEAD(提交9fa8341)、CMSIS-NN 5.7.0版(提交a65b7c9a)、STM32CubeF7的1.16.0版以及Arm GNU Tools for Arm嵌入式处理器9-2019-q4-major 9.2.1工具链(修订版277599)中的GCC。在UbuntuW620X主机上运行UbuntuW620X主机和Ry299X内核运行的UbuntuW329X处理器。
特定于Arm的优化
对于CMSIS-NN,第一个卷积映射到RGB卷积实现(特别是用于输入层),后两个映射到 “快速”卷积实现。在之前的通用优化之后,觉得性能已经足够接近RGB卷积,但是对于快速卷积结果却不满意。幸运的是,Arm发布了一篇文章,描述了CMSIS-NN中使用的优化,发现从SIMD内部函数得到了大量的加速。本文提出了一个使用SIMD内部函数的矩阵乘法微内核(下图)。虽然可以在TVM的代码生成设施中添加对内部函数的一流支持,但从长远来看,这可能是TVM提供的一种“快速而肮脏”的支持SIMD的解决方案。
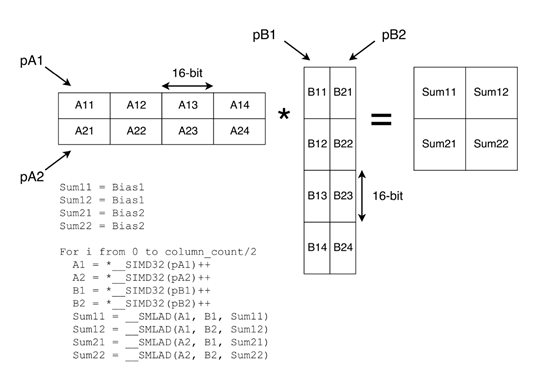
Diagram from CMSIS-NN paper showing a 2x2 matrix multiplication microkernel
CMSIS-NN论文中的图表显示了2x2矩阵乘法微内核
张量化的工作原理是定义一个可以插入TVM运算符最内层循环的微内核。使用这种机制,添加对Arm板的SIMD支持就像在C中定义一个微内核(在这里找到)一样简单,反映了论文中的实现。定义了一个使用这个微内核(在这里可以找到)的计划,进行自动调整,然后得到“µTVM SIMD tuned”结果。
虽然能够使用SIMD微核进行直接卷积,但CMSIS-NN使用称之为“部分im2col”的实现策略,在性能和内存使用之间进行了权衡。部分im2col一次只生成几个列,而不是一次显示整个im2col矩阵。然后,对于每个批次,可以将矩阵发送给SIMD matmul函数。
假设是,在其他优化中,可以通过自动调整找到最佳的批量大小。在实践中,发现部分im2col比直接卷积实现慢得多,所以在剩下的结果中没有包含它。
当然,还可以从CMSIS-NN中进行其他优化,以进一步缩小差距:
批量扩展int8权重到int16,以减少SIMD的重复扩展
将卷积拆分为3x3块以减少填充检查
本文目标是展示µTVM能做些什么。甚至连代码库都不能使用它,因为其他的代码库也不能。
End-To-End CIFAR-10
在探索了卷积的优化之后,开始测量对端到端性能的影响。对于Arm板,收集了未调整的结果、未使用任何SIMD的结果、使用SIMD调整的结果以及使用CMSIS-NN的结果。对于模拟的主机设备,只收集未调整的结果和通用的优化结果。
https://github.com/areusch/microtvm-blogpost-eval
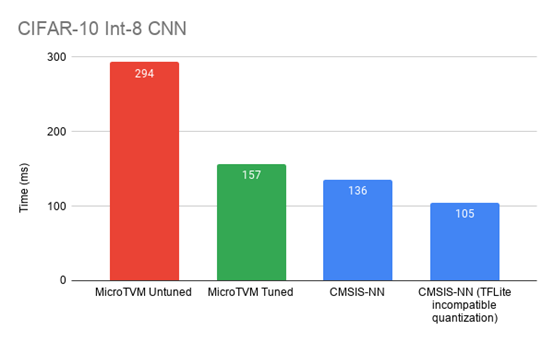
int8-quantized CIFAR-10 CNN comparison on an Arm STM32F746NG (re-posted from above)
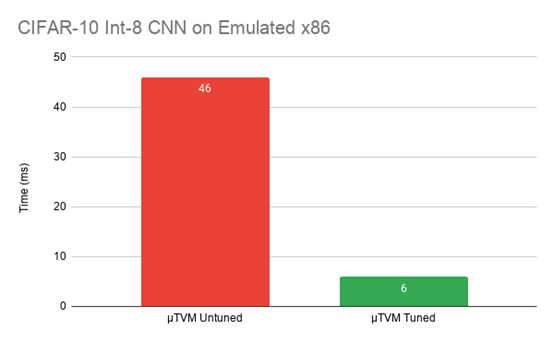
int8-quantized CIFAR-10 CNN comparison on µTVM’s emulated host device
在Arm STM32系列板上,性能比初始未调谐的操作员提高了约2倍,而且结果更接近CMSIS-NN。此外,还能够显著提高主机模拟设备的性能。虽然x86的数字并不意味着什么,表明可以使用相同的基础架构(µTVM)在完全不同的体系结构上优化性能。
随着将这种方法扩展到更广泛的范围,请继续关注更多的端到端基准测试。
Self-Hosted Runtime: The Final Frontier

The envisioned µTVM optimization and deployment pipeline
虽然正如上面所演示的那样,在当前runtime已经可以获得端到端基准测试结果,但是以独立的能力部署这些模型目前仍在路线图上。差距在于面向AutoTVM的runtime,当前依赖于主机来分配张量和调度函数执行。为了在边缘有用,需要一个通过µTVM的管道,它生成一个在裸机设备上运行的二进制文件。然后,用户将能够通过在边缘应用程序中包含这个二进制文件,轻松地将fastml集成到应用程序中。这条管道的每一个阶段都已经准备好了,现在只是把它们粘在一起的问题,所以期待很快在这方面的更新。
Conclusion
用于单核优化的MicroTVM现在已经准备好了,并且是该用例的选择。随着现在构建自托管部署支持,希望也能将µTVM作为模型部署的选择。然而,这不仅仅是一个旁观者的运动-记住:这都是开源的!µTVM仍处于早期阶段,因此每个个体都会对其轨迹产生很大影响。如果有兴趣合作,查看《TVM贡献者指南》,或者直接进入TVM论坛讨论想法。
TinyML-TVM是如何驯服Tiny的(下)的更多相关文章
- TinyML-TVM是如何驯服Tiny的(上)
TinyML-TVM是如何驯服Tiny的(上) 低成本.人工智能驱动的消费类设备的激增,导致了ML研究人员和从业者对"裸智能"(低功耗,通常没有操作系统)设备的广泛兴趣.虽然专家已 ...
- Android图片压缩框架-Tiny 集成
为了简化对图片压缩的调用,提供最简洁与合理的api压缩逻辑,对于压缩为Bitmap根据屏幕分辨率动态适配最佳大小,对于压缩为File优化底层libjpeg的压缩,整个图片压缩过程全在压缩线程池中异步压 ...
- 数据库优化实践【TSQL篇】
在前面我们介绍了如何正确使用索引,调整索引是见效最快的性能调优方法,但一般而言,调整索引只会提高查询性能.除此之外,我们还可以调整数据访问代码和TSQL,本文就介绍如何以最优的方法重构数据访问代码和T ...
- Linux 安装Anaconda 4.4.0
安装步骤参考了官网的说明:https://docs.anaconda.com/anaconda/install/linux.html 具体步骤如下: 1.在官网下载地址 https://www.an ...
- Linux安装pytorch的具体过程以及其中出现问题的解决办法
1.安装Anaconda 安装步骤参考了官网的说明:https://docs.anaconda.com/anaconda/install/linux.html 具体步骤如下: 首先,在官网下载地址 h ...
- (转)SQLServer_十步优化SQL Server中的数据访问 二
原文地址:http://tech.it168.com/a2009/1125/814/000000814758_all.shtml 第五步:识别低效TSQL,采用最佳实践重构和应用TSQL 由于每个程序 ...
- 深入SQL Server优化【推荐】
深入sql server优化,MSSQL优化,T-SQL优化,查询优化 十步优化SQL Server 中的数据访问故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性 ...
- SQL Server 性能优化详解
故事开篇:你和你的团队经过不懈努力,终于使网站成功上线,刚开始时,注册用户较少,网站性能表现不错,但随着注册用户的增多,访问速度开始变慢,一些用户开始发来邮件表示抗议,事情变得越来越糟,为了留住用户, ...
- C++程序结构---1
C++ 基础教程Beta 版 原作:Juan Soulié 翻译:Jing Xu (aqua) 英文原版 本教程根据Juan Soulie的英文版C++教程翻译并改编. 本版为最新校对版,尚未定稿.如 ...
随机推荐
- hdu4118
题意: 给你一颗无向带权树,每个定点上有一个人,问所有定点都不在自己位置上的最长路径总和是多少.. 思路: 其实很简单,贪心的想下,既然要求全局最大,那么对于每一条边用的次 ...
- 8.PHP图像处理
PHP图像处理 GD2 Jpgraph 创建一个画布: <?php header('content-type:image/gif'); //echo "你好"; ...
- Linux系统登录相关
whoami:查看当前用户 who:查看当前登录系统的所有用户 tty指的是主机的图形化界面的面板 pts/x指的是远程ssh连接的窗口 who -b:主机的上一次启动时间 w:显示已经登陆系统的用户 ...
- MS06-040漏洞研究(下)【转载】
课程简介 经过前两次的分析,我们已经对Netapi32.dll文件中所包含的漏洞成功地实现了利用.在系统未打补丁之前,这确实是一个非常严重的漏洞,那么打了补丁之后,这个动态链接库是不是就安全了呢?答案 ...
- pycharm2019
812LFWMRSH-eyJsaWNlbnNlSWQiOiI4MTJMRldNUlNIIiwibGljZW5zZWVOYW1lIjoi5q2j54mIIOaOiOadgyIsImFzc2lnbmVlT ...
- NumPy之:使用genfromtxt导入数据
目录 简介 genfromtxt介绍 多维数组 autostrip comments 跳过行和选择列 简介 在做科学计算的时候,我们需要从外部加载数据,今天给大家介绍一下NumPy中非常有用的一个方法 ...
- [LeetCode每日一题]88. 合并两个有序数组
[LeetCode每日一题]88. 合并两个有序数组 问题 给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 nums1 成为一个有序数组. 初始化 n ...
- java之I/O流
I/O流的使用情况多种多样,首先它的数据源就可能是文件.控制台.服务器等,它的单位可能是按字节.按字符.按行等.为了涵盖所有的可能,java类库中创建了大量的类,如此多的类让我们在使用时感觉有点难以选 ...
- Pytorch实现对卷积的可插拔reparameterization
需要实现对卷积层的重参数化reparameterization 但是代码里卷积前weight并没有hook,很难在原本的卷积类上用pure oo的方式实现 目前的解决方案是继承原本的卷积,挂载一个we ...
- FROM-4-TO-6!!!!!!!!! - OO第二单元总结
电梯的这三次作业是对并发编程的一次管窥,感觉收获还是蛮多的.在设计上有好的地方也有不足,这里简单回顾总结一下 设计总述 电梯这个问题由于比较贴近真实生活,所以需求还是很好理解的.总的来说,我的数据处理 ...