大数据 | 分布式文件系统 HDFS
HDFS 的特点与应用场景
适合存储大文件
容错性高
适用于流式的数据访问
适用于读多写少场景
HDFS的相关概念
数据块(Block)
NameNode和DataNode
Secondary NameNode
块缓存
HDFS 架构
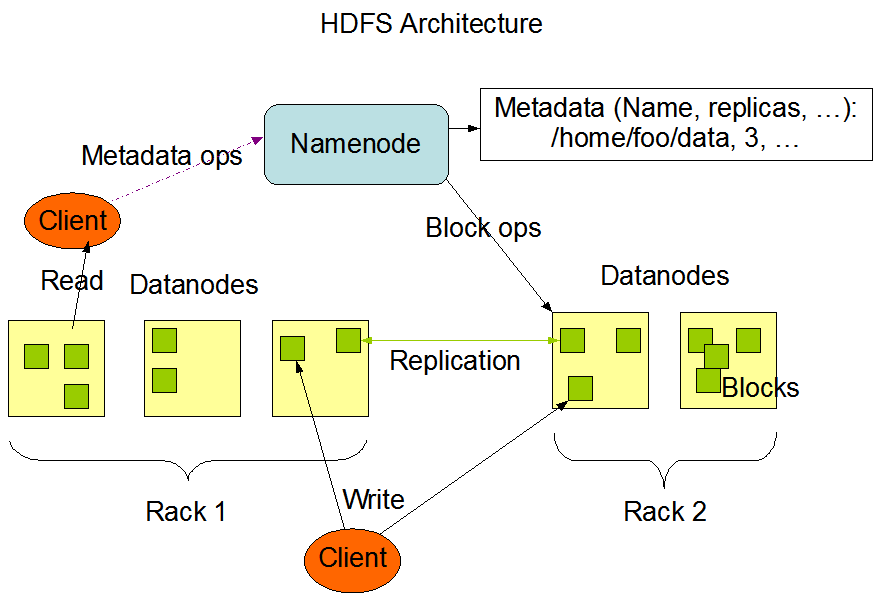
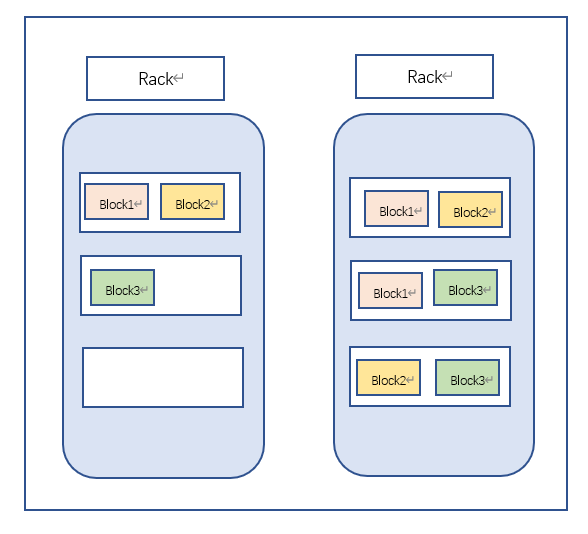
机架感知和副本机制
读写流程
读操作
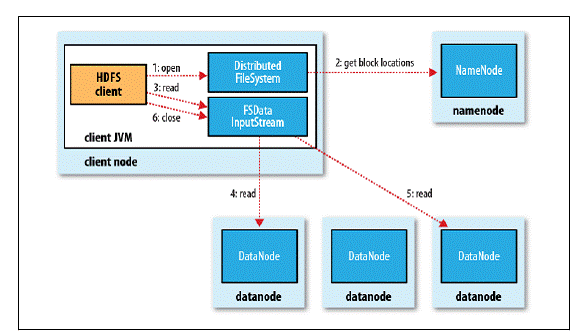
- 客户端通过调用 FileSystem 对象的 open() 方法来打开希望读取的文件,对于 HDFS 来说,这个对象是分布式文件系统的一个实例;
- DistributedFileSystem 通过RPC 调用 NameNode 以确定文件起始块的位置,由于存在多个副本,因此Namenode会返回同一个Block的多个文件的位置,然后根据集群拓扑结构排序,就近取;
- 前两步会返回一个 FSDataInputStream 对象,该对象会被封装成 DFSInputStream 对象,DFSInputStream 可以方便的管理 datanode 和 namenode 数据流,客户端对这个输入流调用 read() 方法;
- 存储着文件起始块的 DataNode 地址的 DFSInputStream 随即连接距离最近的 DataNode,通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端;
- 到达块的末端时,DFSInputStream 会关闭与该 DataNode 的连接,然后寻找下一个块的最佳 DataNode,这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流;
- 一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法关闭文件读取。
写操作
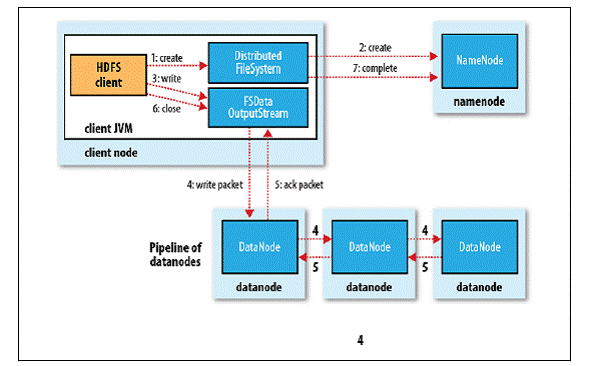
- 客户端通过调用 DistributedFileSystem 的 create() 方法创建新文件;
- DistributedFileSystem 通过 RPC 调用 NameNode 去创建一个没有 Blocks 关联的新文件,创建前 NameNode 会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode 会为创建新文件记录一条记录,否则就会抛出 IO 异常;
- 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode 和 Datanode。客户端开始写数据到 DFSOutputStream,DFSOutputStream 会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
- DataStreamer 会去处理接受 Data Queue,它先问询 NameNode 这个新的 Block 最适合存储在哪几个 DataNode 里,比如重复数是 3,那么就找到 3 个最适合的 DataNode,把他们排成一个 pipeline。DataStreamer 把 Packet 按队列输出到管道的第一个 Datanode 中,第一个 DataNode 又把 Packet 输出到第二个 DataNode 中,以此类推;
- DFSOutputStream 还有一个队列叫 Ack Quene,也是由 Packet 组成,等待 DataNode 的收到响应,当 Pipeline 中的所有 DataNode 都表示已经收到的时候,这时 Akc Quene 才会把对应的 Packet 包移除掉;
- 客户端完成写数据后调用 close() 方法关闭写入流;
- DataStreamer 把剩余的包都刷到 Pipeline 里然后等待 Ack 信息,收到最后一个 Ack 后,通知 NameNode 把文件标示为已完成。
总结

大数据 | 分布式文件系统 HDFS的更多相关文章
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据 | 分布式文件系统HDFS 练习
本次作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 利用Shell命令与HDFS进行交互 以”./bin/dfs ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据篇:HDFS
HDFS HDFS是什么? Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File Syste ...
- 你想了解的分布式文件系统HDFS,看这一篇就够了
1.分布式文件系统 计算机集群结构 分布式文件系统把文件分布存储到多个节点(计算机)上,成千上万的计算机节点构成计算机集群. 分布式文件系统使用的计算机集群,其配置都是由普通硬件构成的,与用多个处理器 ...
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 大数据技术 - 分布式文件系统 HDFS 的设计
本章内容介绍下 Hadoop 自带的分布式文件系统,HDFS 即 Hadoop Distributed Filesystem.HDFS 能够存储超大文件,可以部署在廉价的服务器上,适合一次写入多次读取 ...
随机推荐
- Python socket 编程实验
实验内容 1.编写一个基于UDP协议的客户机与服务器程序,实现相互通讯. 2.编写一个基于TCP协议的客户机与服务器程序,实现相互通讯. 3.捕获以上两种通讯的数据包,使用Wireshark进行分析, ...
- python基础之面向对象(三))(实战:烤地瓜(SweetPotato))
一.分析"烤地瓜"的属性和方法 示例属性如下: cookedLevel : 这是数字:0~3表示还是生的,超过3表示半生不熟,超过5表示已经烤好了,超过8表示已经烤成木炭了!我们的 ...
- python基础之字典、集合
一.字典(dictionary) 作用:存多个值,key-value存取,取值速度快 定义:key必须是不可变类型,value可以是任意类型 字典是一个无序的,可以修改的,元素呈键值对的形式,以逗号分 ...
- 10.8 ss:查看网络状态
ss命令 是类似并将取代netstat的工具,它能用来查看网络状态信息,包括TCP.UDP连接.端口等.它的优点是能够显示更多更详细的有关网络连接状态的信息,而且比netstat更快速更高效. ...
- 【Azure 事件中心】azure-spring-cloud-stream-binder-eventhubs客户端组件问题, 实践消息非顺序可达
问题描述 查阅了Azure的官方文档( 将事件发送到特定分区: https://docs.azure.cn/zh-cn/event-hubs/event-hubs-availability-and-c ...
- [leetcode] 39. 组合总和(Java)(dfs、递归、回溯)
39. 组合总和 直接暴力思路,用dfs+回溯枚举所有可能组合情况.难点在于每个数可取无数次. 我的枚举思路是: 外层枚举答案数组的长度,即枚举解中的数字个数,从1个开始,到target/ min(c ...
- Ajax|看这一篇就够了!详解Ajax工作原理及开发步骤
传统开发的缺点,是对于浏览器的页面,全部都是全局刷新的体验.如果我们只是想取得或是更新页面中的部分信息那么就必须要应用到局部刷新的技术. 局部刷新也是有效提升用户体验的一种非常重要的方式. Ajax技 ...
- CVPR2020论文解析:视频分类Video Classification
CVPR2020论文解析:视频分类Video Classification Rethinking Zero-shot Video Classification: End-to-end Training ...
- CUDA C++编程手册(总论)
CUDA C++编程手册(总论) CUDA C++ Programming Guide The programming guide to the CUDA model and interface. C ...
- Hashing散列注意事项
Hashing散列注意事项 Numba支持内置功能hash(),只需__hash__()在提供的参数上调用成员函数即可 .这使得添加对新类型的哈希支持变得微不足道,这是因为扩展APIoverload_ ...