如何利用Python计算景观指数AI
可使用工具包
- pylandstats
- 此工具包基本是根据fragstats形成的,大部分fragstats里面的景观指数,这里都可以计算。但是,还是有一小部分指数这里没有涉及。
- LS_METRICS
自定义的aggregation index(AI)计算
原理
\]
这里的\(e_{ii}\)是同类型像元公共边的个数
\(max\_e_{ii}\)是同类型像元最大公共边的个数, \(max\_e_{ii}\)的计算有公式可寻,具体计算公式如下:
\[\begin{align*}
& max\_eii = 2n(n-1), & when \quad m = 0, or\\
& max\_eii = 2n(n-1) + 2m -1, & when\quad m ≤ n, or\\
& max\_eii = 2n(n-1) + 2m -2, & when \quad m > n.\\
\end{align*}
\]n为不超过某个类型像元总面积\(A_i\)的最大整数正方形的边长
m=\(A_i-n^2\)
实例
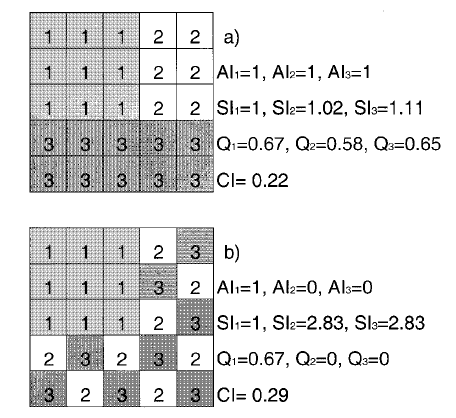
- 例如图a中类型1的聚居指数AI可为:
\[\begin{align*}
&e_{ii}=12\\
&max\_e{ii}=2n(n-1)=2\times3\times2=12\\
&AI=\frac{e_{ii}}{max\_e{ii}}\times100=100
\end{align*}
\]这里AI为100是因为这里乘了一个系数100;
Python实现
- 函数依赖关系

class AI(Landscape, ABC):
def __init__(self, landscape, **kwargs):
super().__init__(landscape, **kwargs)
# 用于计算每种类型公共边的数量
def get_share_edge(self, class_):
# 1.将数据转换为二值型
binary_data = (self.landscape_arr == class_).astype(np.int8)
# 2.设置卷积模板
cov_template = np.array([[0, 0, 0],
[0, 0, 1],
[0, 1, 0]])
# 3.填充边缘
binary_pad = np.pad(binary_data, 1, mode='constant', constant_values=0)
# 4.计算公共边总数
row_num, col_num = binary_pad.shape
count = 0
for i in range(1, row_num - 1):
for j in range(1, col_num - 1):
if binary_pad[i, j] == 1:
count += np.sum(binary_pad[i - 1:i + 2, j - 1:j + 2] * cov_template)
return count
# 计算eii
@property
def eii(self):
return pd.Series([self.get_share_edge(class_) for class_ in self.classes], index=self.classes)
# 计算最大的eii
@property
def max_eii(self):
arr = self.landscape_arr
flat_arr = arr.ravel()
# 规避nodata值
if self.nodata in flat_arr:
a_ser = pd.value_counts(flat_arr).drop(self.nodata).reindex(self.classes)
else:
a_ser = pd.value_counts(flat_arr).reindex(self.classes)
n_ser = np.floor(np.sqrt(a_ser))
m_ser = a_ser - np.square(n_ser)
max_eii = pd.Series(index=a_ser.index)
for i in a_ser.index:
if m_ser[i] == 0:
max_eii[i] = (2 * n_ser[i]) * (n_ser[i] - 1)
elif m_ser[i] <= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 1
elif m_ser[i] >= n_ser[i]:
max_eii[i] = 2 * n_ser[i] * (n_ser[i] - 1) + 2 * m_ser[i] - 2
return max_eii
# 计算AI指数
def aggregation_index(self, class_val=None):
"""
计算斑块类型的聚集指数AI
:param class_val: 整型,需要计算AI的斑块类型代号
:return: 标量数值或者Series
"""
if len(self.classes) < 1:
warnings.warn("当前数组全是空值,没有需要计算的类型聚集指数",
RuntimeWarning,
)
return np.nan
if class_val is None:
return (self.eii / self.max_eii) * 100
else:
return ((self.eii / self.max_eii) * 100)[class_val]
参考文献
- An aggregation index (AI) to quantify spatial patterns of landscapes
- http://www.umass.edu/landeco/research/fragstats/documents/Metrics/Contagion - Interspersion Metrics/Metrics/C116 - AI.htm
如何利用Python计算景观指数AI的更多相关文章
- 利用Python计算π的值,并显示进度条
利用Python计算π的值,并显示进度条 第一步:下载tqdm 第二步;编写代码 from math import * from tqdm import tqdm from time import ...
- 利用python计算windows全盘文件md5值的脚本
import hashlib import os import time import configparser import uuid def test_file_md5(file_path): t ...
- 利用python计算多边形面积
最近业务上有一个需求,给出多边形面积. Google了一下,发现国内论坛给的算法都是你抄我我抄你,也不验证一下是否正确, 从 博客园到csdncsdn 然后传播到国内各个角落...真是无力吐槽了. 直 ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 《利用Python进行数据分析·第2版》第四章 Numpy基础:数组和矢量计算
<利用Python进行数据分析·第2版>第四章 Numpy基础:数组和矢量计算 numpy高效处理大数组的数据原因: numpy是在一个连续的内存块中存储数据,独立于其他python内置对 ...
- 利用 Python 尝试采用面向对象的设计方法计算图形面积及周长
利用 Python 尝试采用面向对象的设计方法.(1)设计一个基类 Shape:包含两个成员函数:def cal_area(): 计算并返回该图形的面积,保留两位小数:def cal_perimete ...
- 利用Python进行数据分析_Pandas_汇总和计算描述统计
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. In [1]: import numpy as np In [2]: impo ...
- 利用Python科学计算处理物理问题(和物理告个别)
背景: 2019年初由于尚未学习量子力学相关知识,所以处于自学阶段.浅显的学习了曾谨言的量子力学一卷和格里菲斯编写的量子力学教材.注重将量子力学的一些基本概念了解并理解.同时老师向我们推荐了Quant ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
随机推荐
- Spring Cloud Alibaba Nacos Config 实战
Nacos 提供用于存储配置和其他元数据的 key/value 存储,为分布式系统中的外部化配置提供服务器端和客户端支持.使用 Spring Cloud Alibaba Nacos Config,您可 ...
- SPEC CPU2006的安装和使用
https://www.spec.org/download.html http://blog.lazzzy.xyz/2017/09/15/SPEC_CPU2006/ BenchMark SPEC CP ...
- CentOS6 YUM 源失效问题解决办法
问题解决 网站好不容易找到一个 Yum 源还能用,地址:https://vault.centos.org/6.9/ 操作简单,把CentOS-Base.repo 里面的东西全部删掉,添加如下内容即可. ...
- 实例:使用playbook实现httpd安装、配置、以及虚拟主机的配置
一.安装环境配置 1.在控制节点给受控主机配置本地仓库文件 [root@ansible ~]# vim /etc/yum.repos.d/dvd.repo [AppStream] name=appst ...
- k8s 管理存储资源(10)
一.Kubernetes 如何管理存储资源 理解Volume 我们经常会说:容器和 Pod 是短暂的. 其含义是它们的生命周期可能很短,会被频繁地销毁和创建.容器销毁时,保存在容器内部文件系统中的数据 ...
- 018.Python迭代器以及map和reduce函数
一 迭代器 能被next进行调用,并且不断返回下一个值的对象 特征:迭代器会生成惰性序列,它通过计算把值依次的返回,一边循环一边计算而不是一次性得到所有数据 优点:需要数据的时候,一次取一个,可以大大 ...
- 2.7循环_while
循环 目标 程序的三大流程 while 循环基本使用 break 和 continue while 循环嵌套 01. 程序的三大流程 在程序开发中,一共有三种流程方式: 顺序 -- 从上向下,顺序执行 ...
- 6.5 scp:远程文件复制
scp命令 用于在不同的主机之间复制文件,它采用SSH协议来保证复制的安全性.scp命令每次都是全量完整复制,因此效率不高,适合第一次复制时使用,增量复制建议使用rsync命令替代. scp ...
- git&nodejs安装教程
git https://www.cnblogs.com/ximiaomiao/p/7140456.html nodejs https://jingyan.baidu.com/article/e7505 ...
- Python+Selenium - windows安全中心的弹窗(账号登录)
当出现如下图所示的 Windows安全中心弹窗,需要输入用户名和密码时 如何用Python+selenium跳过这个登录. 步骤: 1.在注册表中三个位置各添加两个东西:iexplore.exe 和 ...